Come eseguire l'anova nidificata in r (passo dopo passo)
Un’ANOVA annidata è un tipo di ANOVA (“analisi della varianza”) in cui almeno un fattore è annidato all’interno di un altro fattore.
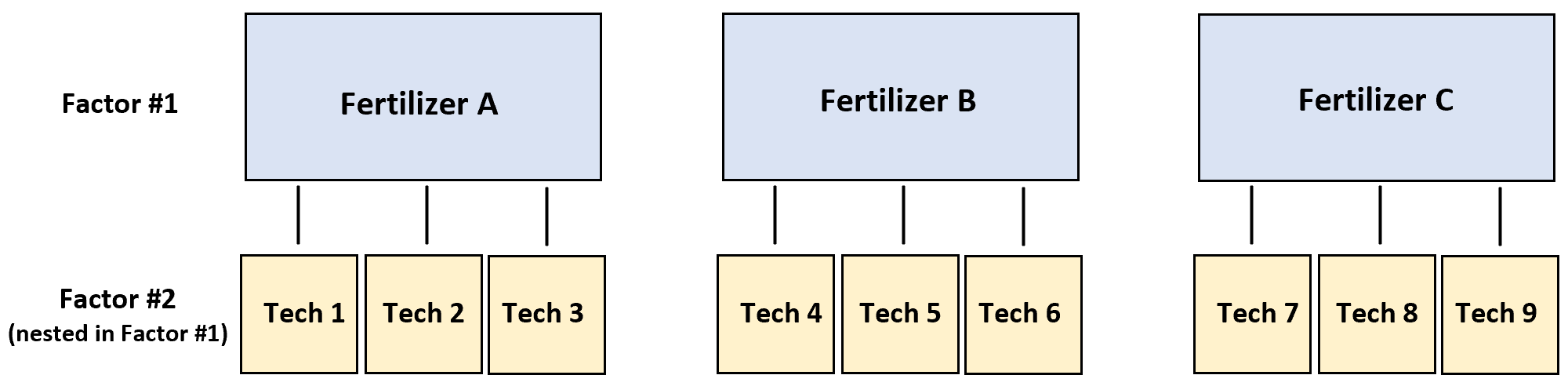
Ad esempio, supponiamo che un ricercatore voglia sapere se tre diversi fertilizzanti producono diversi livelli di crescita delle piante.
Per testarlo, tre tecnici diversi cospargono ciascuno il fertilizzante A su quattro piante, altri tre tecnici cospargono ciascuno il fertilizzante B su quattro piante e altri tre tecnici cospargono ciascuno il fertilizzante C su quattro piante.
In questo scenario, la variabile di risposta è la crescita delle piante e i due fattori sono tecnico e fertilizzante. Si scopre che il tecnico è immerso nel fertilizzante:
Il seguente esempio passo passo mostra come eseguire questa ANOVA annidata in R.
Passaggio 1: creare i dati
Innanzitutto, creiamo un data frame per contenere i nostri dati in R:
#create data df <- data. frame (growth=c(13, 16, 16, 12, 15, 16, 19, 16, 15, 15, 12, 15, 19, 19, 20, 22, 23, 18, 16, 18, 19, 20, 21, 21, 21, 23, 24, 22, 25, 20, 20, 22, 24, 22, 25, 26), fertilizer=c(rep(c(' A ', ' B ', ' C '), each= 12 )), tech=c(rep(1:9, each= 4 ))) #view first six rows of data head(df) growth fertilizer tech 1 13 A 1 2 16 A 1 3 16 A 1 4 12 A 1 5 15 A 2 6 16 A 2
Passaggio 2: regolare l’ANOVA nidificato
Possiamo usare la seguente sintassi per adattare un’ANOVA nidificata in R:
aov(risposta ~ fattore A / fattore B)
Oro:
- risposta: la variabile di risposta
- fattore A: il primo fattore
- fattore B: il secondo fattore annidato nel primo fattore
Il codice seguente mostra come adattare l’ANOVA nidificata per il nostro set di dati:
#fit nested ANOVA nest <- aov(df$growth ~ df$fertilizer / factor(df$tech)) #view summary of nested ANOVA summary(nest) Df Sum Sq Mean Sq F value Pr(>F) df$fertilizer 2 372.7 186.33 53.238 4.27e-10 *** df$fertilizer:factor(df$tech) 6 31.8 5.31 1.516 0.211 Residuals 27 94.5 3.50 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Passaggio 3: interpretare il risultato
Possiamo osservare la colonna del valore p per determinare se ciascun fattore ha o meno un effetto statisticamente significativo sulla crescita delle piante.
Dalla tabella sopra, possiamo vedere che il fertilizzante ha un effetto statisticamente significativo sulla crescita delle piante (valore p < 0,05), ma il tecnico no (valore p = 0,211).
Questo ci dice che se vogliamo aumentare la crescita delle piante, dobbiamo concentrarci sul fertilizzante utilizzato piuttosto che sul singolo tecnico che applica il fertilizzante.
Passaggio 4: visualizzare i risultati
Infine, possiamo utilizzare i boxplot per visualizzare la distribuzione della crescita delle piante per fertilizzante e per tecnico:
#load ggplot2 data visualization package library (ggplot2) #create boxplots to visualize plant growth ggplot(df, aes (x=factor(tech), y=growth, fill=fertilizer)) + geom_boxplot()
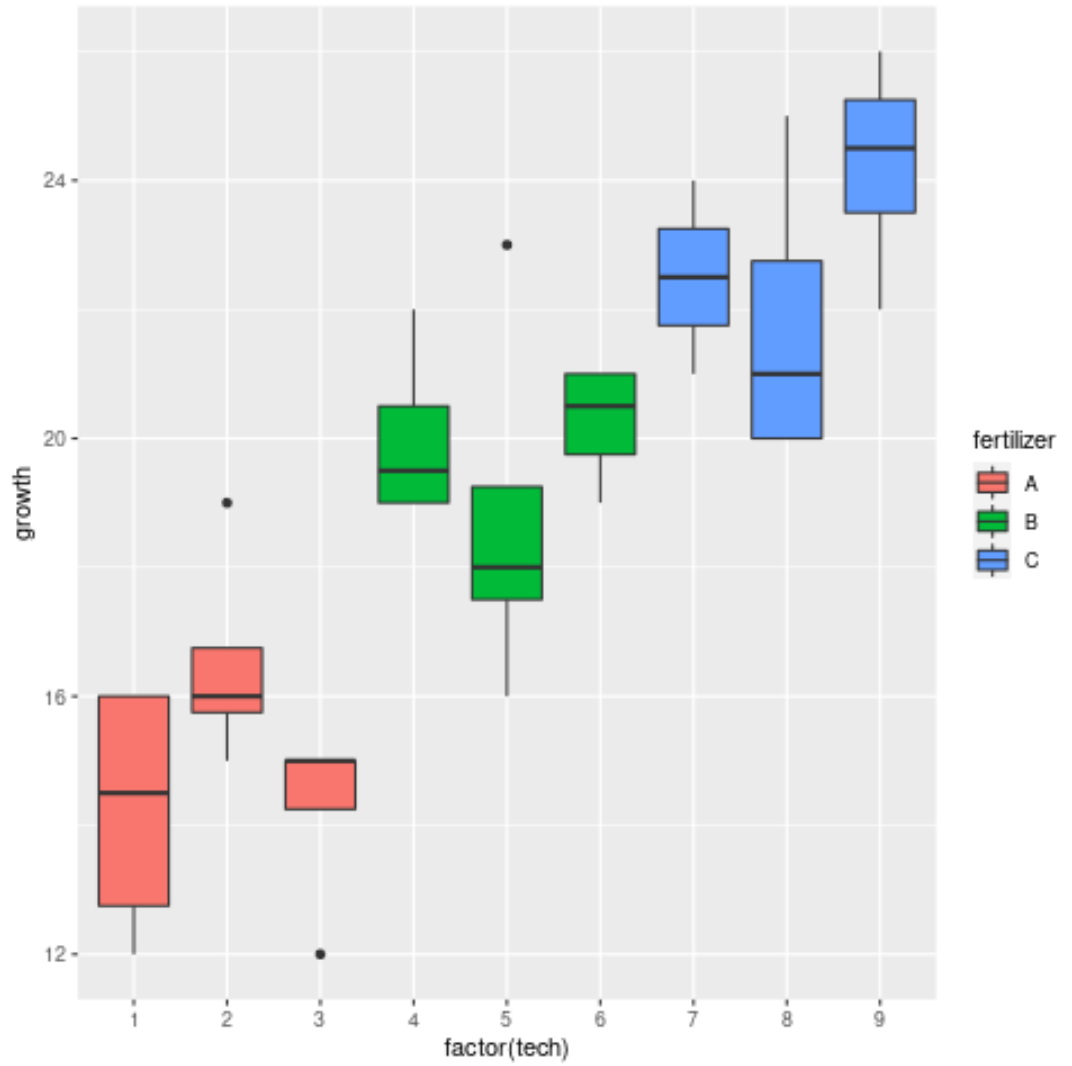
Il grafico mostra che esiste una variazione significativa nella crescita tra i tre diversi fertilizzanti, ma non così tanta variazione tra i tecnici all’interno di ciascun gruppo di fertilizzanti.
Ciò sembra corrispondere ai risultati dell’ANOVA nidificata e conferma che i fertilizzanti hanno un effetto significativo sulla crescita delle piante, ma i singoli tecnici no.
Risorse addizionali
Come eseguire l’ANOVA unidirezionale in R
Come eseguire l’ANOVA bidirezionale in R
Come eseguire l’ANOVA a misure ripetute in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più