Anova vs regressione: qual è la differenza?
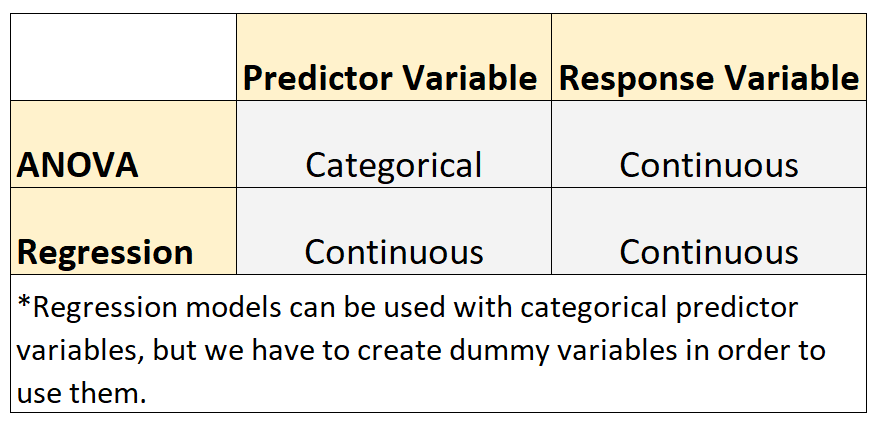
Due modelli comunemente usati nelle statistiche sono ANOVA e modelli di regressione.
Questi due tipi di modelli condividono la seguente somiglianza:
- La variabile di risposta in ciascun modello è continua. Esempi di variabili continue includono peso, altezza, lunghezza, larghezza, tempo, età, ecc.
Tuttavia, questi due tipi di modelli condividono la seguente differenza :
- I modelli ANOVA vengono utilizzati quando le variabili predittive sono categoriali. Esempi di variabili categoriali includono il livello di istruzione, il colore degli occhi, lo stato civile, ecc.
- I modelli di regressione vengono utilizzati quando le variabili predittive sono continue.*
*I modelli di regressione possono essere utilizzati con variabili predittive categoriali, ma per utilizzarli è necessario creare variabili fittizie .
Gli esempi seguenti mostrano quando utilizzare nella pratica ANOVA o modelli di regressione.
Esempio 1: modello ANOVA preferito
Supponiamo che un biologo voglia capire se quattro diversi fertilizzanti portano o meno alla stessa crescita media delle piante (in pollici) nell’arco di un mese. Per testarlo, applica ciascun fertilizzante a 20 piante e registra la crescita di ciascuna pianta dopo un mese.
In questo scenario, il biologo deve utilizzare un modello ANOVA unidirezionale per analizzare le differenze tra i fertilizzanti perché esiste una variabile predittrice ed è categoriale.
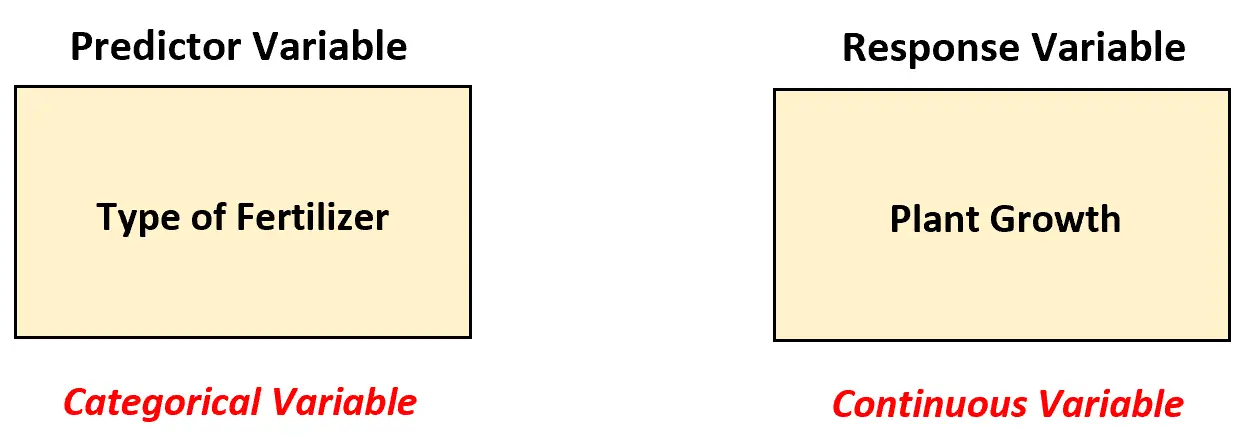
In altre parole, i valori della variabile predittore possono essere classificati nelle seguenti “categorie”:
- Fertilizzante 1
- Fertilizzante 2
- Fertilizzante 3
- Fertilizzante 4
Un’ANOVA unidirezionale dirà al biologo se la crescita media delle piante è uguale o meno tra i quattro diversi fertilizzanti.
Esempio 2: modello di regressione preferito
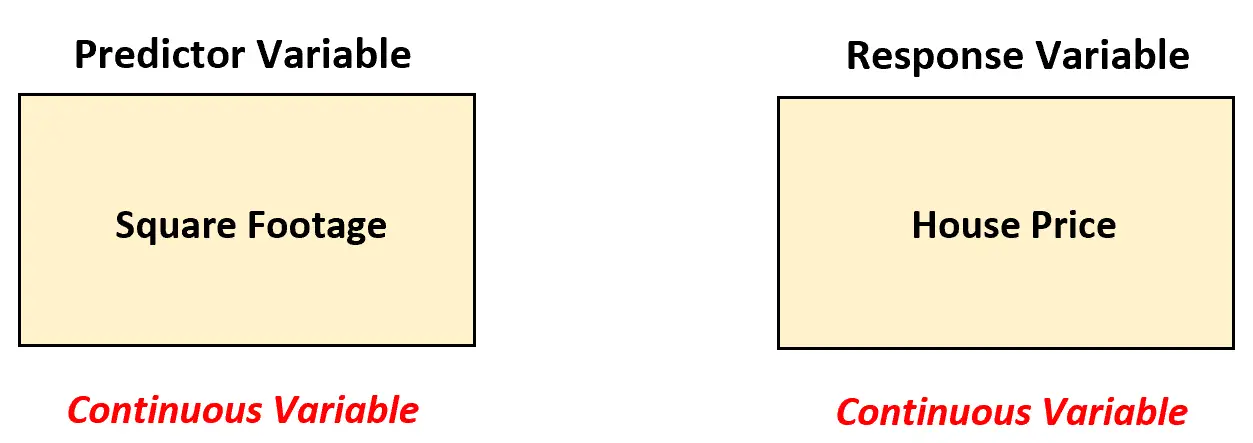
Diciamo che un agente immobiliare vuole capire la relazione tra metratura e prezzo dell’immobile. Per analizzare questa relazione, raccoglie dati sulla metratura e sul prezzo di 200 case in una determinata città.
In questo scenario, l’agente immobiliare dovrebbe utilizzare un semplice modello di regressione lineare per analizzare la relazione tra queste due variabili perché la variabile predittore (metratura) è continua.
Utilizzando una regressione lineare semplice, l’agente immobiliare può adattare il seguente modello di regressione:
Prezzo dell’immobile = β 0 + β 1 (area quadrata)
Il valore di β 1 rappresenterà la variazione media del prezzo della casa associata a ogni metro quadrato aggiuntivo.
Ciò consentirà all’agente immobiliare di quantificare il rapporto tra metratura e prezzo dell’immobile.
Esempio 3: modello di regressione con variabili dummy preferite
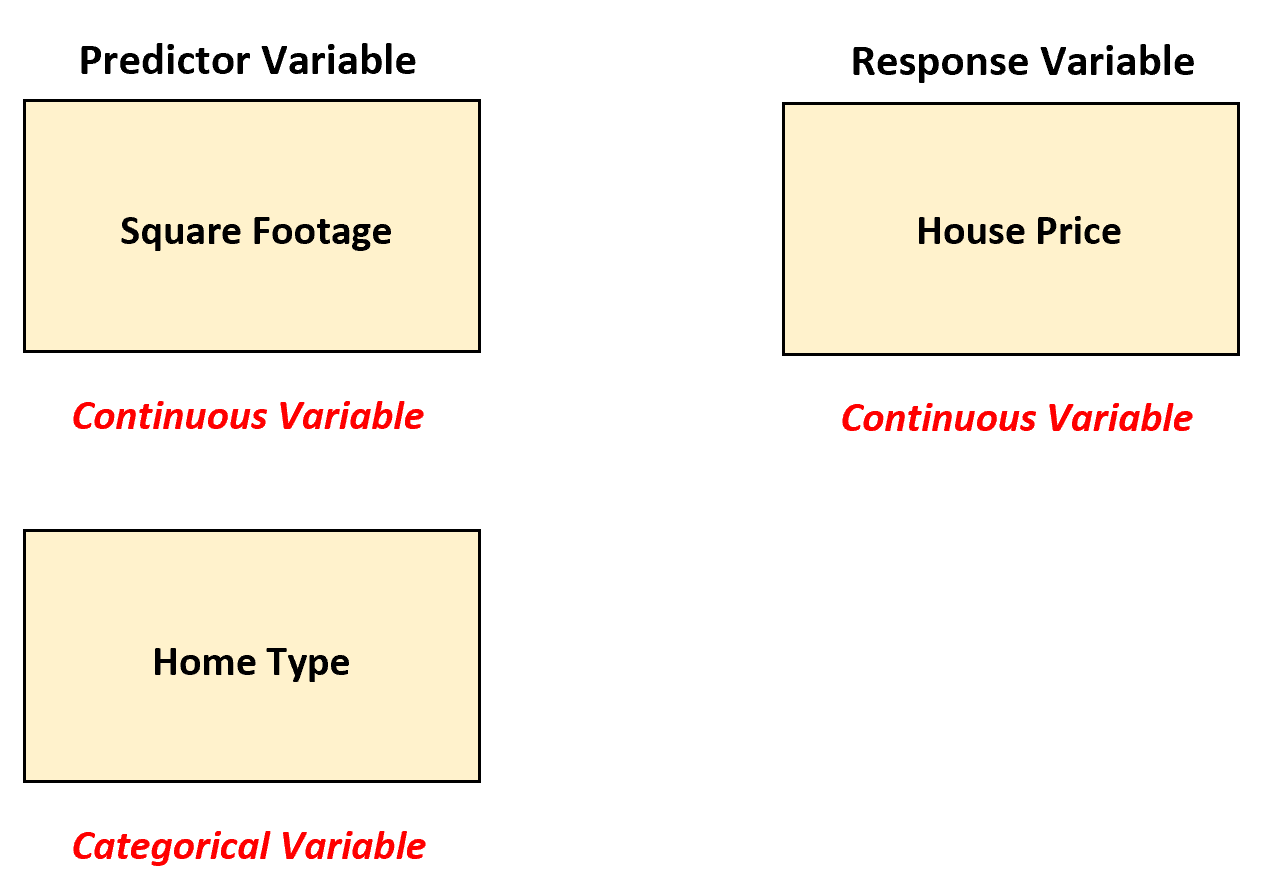
Supponiamo che un agente immobiliare voglia comprendere la relazione tra le variabili predittive “metratura” e “tipologia di casa” (unifamiliare, appartamento, residenza) con la variabile di risposta del prezzo dell’immobile.
In questo scenario, l’agente immobiliare può utilizzare la regressione lineare multipla convertendo il “tipo di casa” in una variabile fittizia poiché attualmente è una variabile categoriale.
L’agente immobiliare può quindi adattare il seguente modello di regressione lineare multipla:
Prezzo dell’immobile = β 0 + β 1 (superficie quadrata) + β 2 (unifamiliare) + β 3 (appartamento)
Ecco come interpreteremmo i coefficienti del modello:
- β 1 : La variazione media del prezzo della casa associata a un metro quadrato in più.
- β 2 : La differenza di prezzo media tra una casa unifamiliare e una casa a schiera, presupponendo che la metratura rimanga costante.
- β 3 : Differenza media di prezzo tra una casa unifamiliare e un appartamento, assumendo una superficie costante.
Dai un’occhiata ai seguenti tutorial per vedere come creare variabili fittizie in diversi software statistici:
Risorse addizionali
I seguenti tutorial forniscono un’introduzione approfondita ai modelli ANOVA:
I seguenti tutorial forniscono un’introduzione approfondita ai modelli di regressione lineare:
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più