Una rapida introduzione all’apprendimento supervisionato e non supervisionato
Il campo dell’apprendimento automatico contiene un’enorme serie di algoritmi che possono essere utilizzati per comprendere i dati. Questi algoritmi possono essere classificati in una delle due categorie seguenti:
1. Algoritmi di apprendimento supervisionato: implicano la costruzione di un modello per stimare o prevedere un risultato basato su uno o più input.
2. Algoritmi di apprendimento non supervisionato: implicano la ricerca di strutture e relazioni dagli input. Non esiste un output di “supervisione”.
Questo tutorial spiega la differenza tra questi due tipi di algoritmi insieme a diversi esempi di ciascuno.
Algoritmi di apprendimento supervisionato
Un algoritmo di apprendimento supervisionato può essere utilizzato quando abbiamo una o più variabili esplicative ( X1 , la variabile di risposta:
Y = f (X) + ε
dove f rappresenta l’informazione sistematica che X fornisce su Y e dove ε è un termine di errore casuale indipendente da X con media pari a zero.
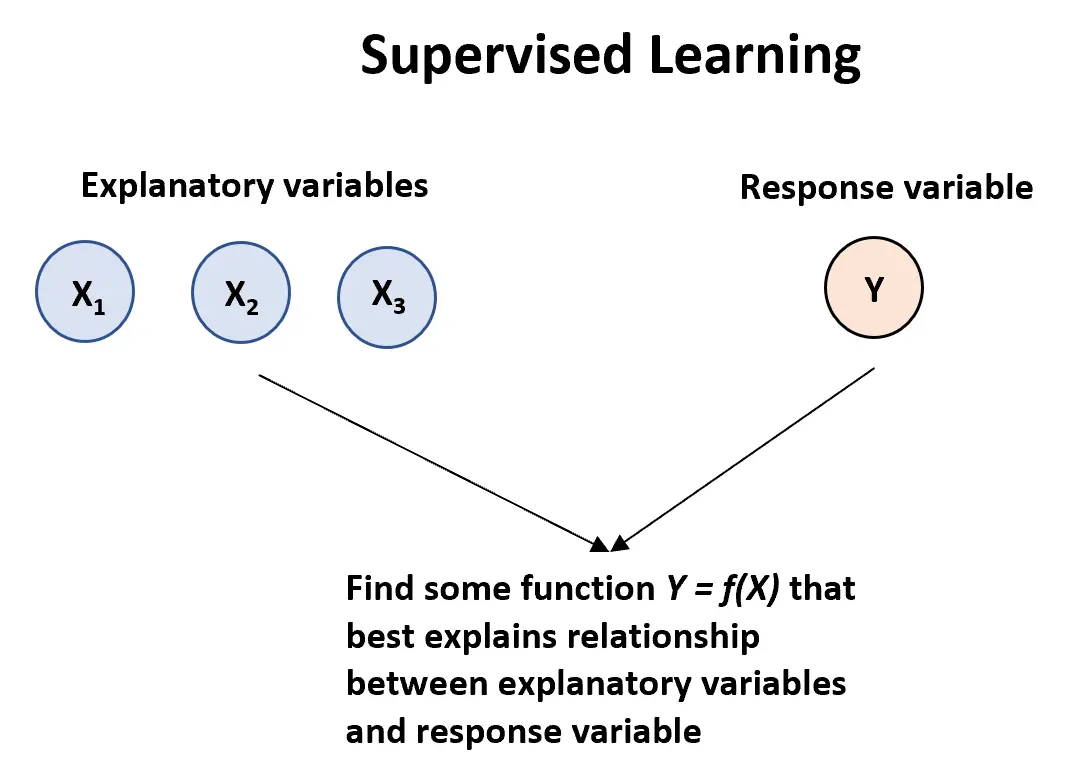
Esistono due tipi principali di algoritmi di apprendimento supervisionato:
1. Regressione: la variabile di output è continua (es. peso, altezza, tempo, ecc.)
2. Classificazione: la variabile di output è categoriale (ad esempio maschio o femmina, successo o fallimento, benigna o maligna, ecc.)
Ci sono due ragioni principali per cui utilizziamo algoritmi di apprendimento supervisionato:
1. Previsione: spesso utilizziamo una serie di variabili esplicative per prevedere il valore di una variabile di risposta (ad esempio, utilizzando la metratura e il numero di camere da letto per prevedere il prezzo di una casa ).
2. Inferenza: potremmo essere interessati a capire come viene influenzata una variabile di risposta quando cambia il valore delle variabili esplicative (ad esempio, quanto aumenta il prezzo degli immobili, in media, quando il numero di stanze aumenta di uno?)
A seconda che il nostro obiettivo sia l’inferenza o la previsione (o una combinazione di entrambi), possiamo utilizzare diversi metodi per stimare la funzione f . Ad esempio, i modelli lineari offrono un’interpretazione più semplice, ma i modelli non lineari difficili da interpretare possono offrire previsioni più accurate.
Ecco un elenco degli algoritmi di apprendimento supervisionato più comunemente utilizzati:
- Regressione lineare
- Regressione logistica
- Analisi discriminante lineare
- Analisi discriminante quadratica
- Alberi decisionali
- L’ingenuo Bayes
- Supporta macchine vettoriali
- Reti neurali
Algoritmi di apprendimento non supervisionato
Un algoritmo di apprendimento non supervisionato può essere utilizzato quando abbiamo un elenco di variabili ( X 1 , data.
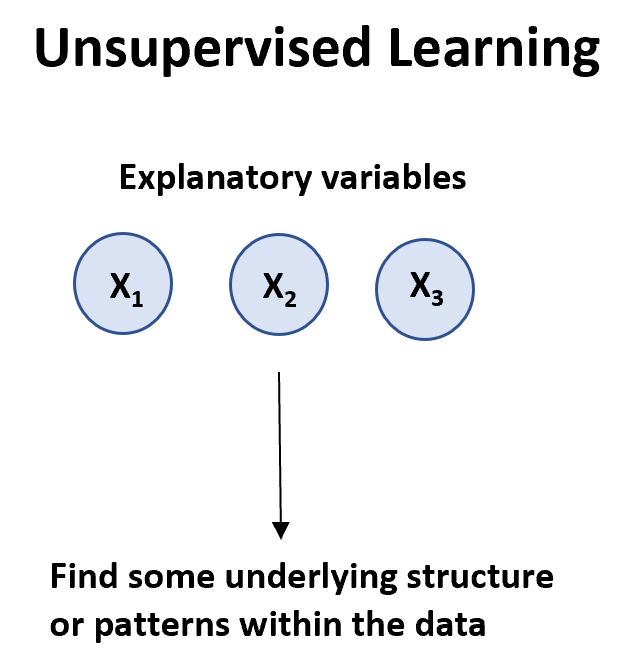
Esistono due tipi principali di algoritmi di apprendimento non supervisionato:
1. Clustering: utilizzando questi tipi di algoritmi, proviamo a trovare “cluster” di osservazioni in un set di dati simili tra loro. Questo viene spesso utilizzato nella vendita al dettaglio quando un’azienda desidera identificare gruppi di clienti con abitudini di acquisto simili in modo che possano creare strategie di marketing specifiche rivolte a determinati gruppi di clienti.
2. Associazione: utilizzando questi tipi di algoritmi, cerchiamo di trovare “regole” che possano essere utilizzate per stabilire associazioni. Ad esempio, i rivenditori possono sviluppare un algoritmo di associazione che indica che “se un cliente acquista il prodotto X, è molto probabile che acquisti anche il prodotto Y”.
Ecco un elenco degli algoritmi di apprendimento non supervisionato più comunemente utilizzati:
- Analisi del componente principale
- K-significa clustering
- Raggruppamento di K-medoidi
- Classificazione gerarchica
- Algoritmo a priori
Riepilogo: apprendimento supervisionato o non supervisionato
La tabella seguente riassume le differenze tra algoritmi di apprendimento supervisionato e non supervisionato:
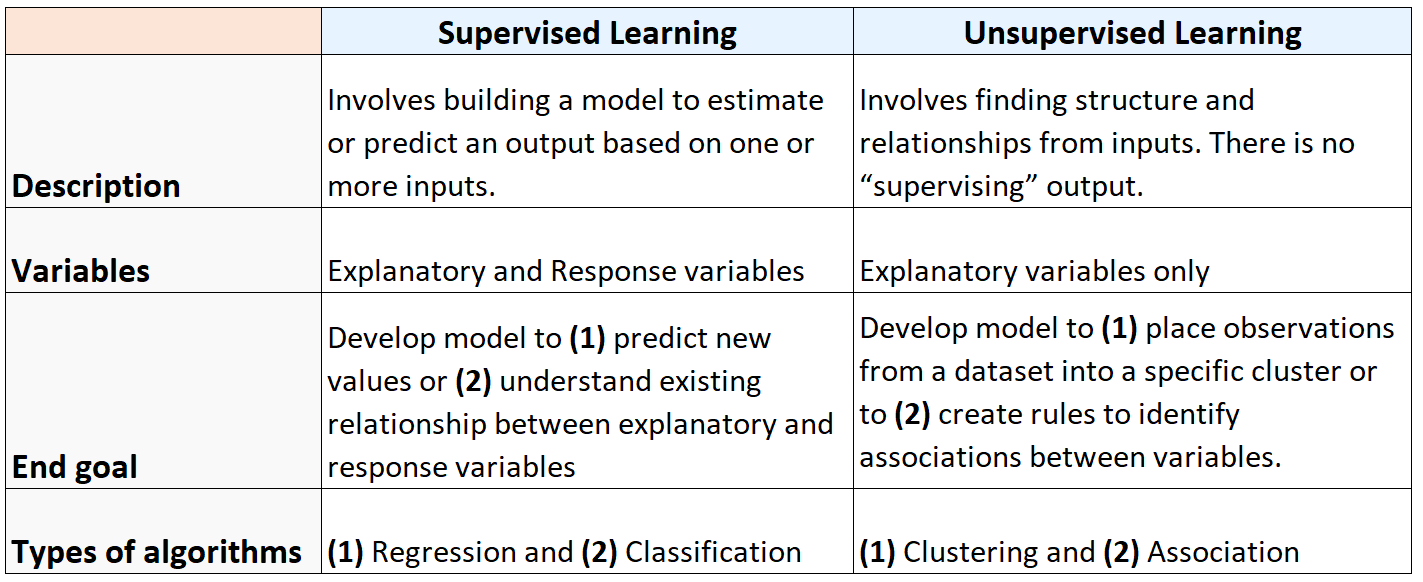
E il diagramma seguente riassume i tipi di algoritmi di machine learning:

Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più