Minimi quadrati parziali in python (passo dopo passo)
Uno dei problemi più comuni che incontrerai nell’apprendimento automatico è la multicollinearità . Ciò si verifica quando due o più variabili predittive in un set di dati sono altamente correlate.
Quando ciò accade, un modello potrebbe essere in grado di adattarsi bene a un set di dati di addestramento, ma potrebbe funzionare male su un nuovo set di dati che non ha mai visto perché si adatta eccessivamente al set di dati di addestramento. insieme di formazione.
Un modo per aggirare questo problema è utilizzare un metodo chiamato minimi quadrati parziali , che funziona come segue:
- Standardizzare le variabili predittive e di risposta.
- Calcolare M combinazioni lineari (chiamate “componenti PLS”) delle p variabili predittive originali che spiegano una quantità significativa di variazione sia nella variabile di risposta che nelle variabili predittive.
- Utilizzare il metodo dei minimi quadrati per adattare un modello di regressione lineare utilizzando i componenti PLS come predittori.
- Utilizza la convalida incrociata k-fold per trovare il numero ottimale di componenti PLS da mantenere nel modello.
Questo tutorial fornisce un esempio passo passo di come eseguire i minimi quadrati parziali in Python.
Passaggio 1: importa i pacchetti necessari
Per prima cosa importeremo i pacchetti necessari per eseguire i minimi quadrati parziali in Python:
import numpy as np
import pandas as pd
import matplotlib. pyplot as plt
from sklearn. preprocessing import scale
from sklearn import model_selection
from sklearn. model_selection import RepeatedKFold
from sklearn. model_selection import train_test_split
from sklearn. cross_decomposition import PLSRegression
from sklearn . metrics import mean_squared_error
Passaggio 2: caricare i dati
Per questo esempio utilizzeremo un set di dati chiamato mtcars , che contiene informazioni su 33 auto diverse. Utilizzeremo hp come variabile di risposta e le seguenti variabili come predittori:
- mpg
- Schermo
- merda
- peso
- qsec
Il codice seguente mostra come caricare e visualizzare questo set di dati:
#define URL where data is located
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/mtcars.csv"
#read in data
data_full = pd. read_csv (url)
#select subset of data
data = data_full[["mpg", "disp", "drat", "wt", "qsec", "hp"]]
#view first six rows of data
data[0:6]
mpg disp drat wt qsec hp
0 21.0 160.0 3.90 2.620 16.46 110
1 21.0 160.0 3.90 2.875 17.02 110
2 22.8 108.0 3.85 2.320 18.61 93
3 21.4 258.0 3.08 3.215 19.44 110
4 18.7 360.0 3.15 3.440 17.02 175
5 18.1 225.0 2.76 3.460 20.22 105
Passaggio 3: adattare il modello dei minimi quadrati parziali
Il codice seguente mostra come adattare il modello PLS a questi dati.
Si noti che cv = RepeatedKFold() dice a Python di utilizzare la convalida incrociata k-fold per valutare le prestazioni del modello. Per questo esempio scegliamo k = 10 pieghe, ripetute 3 volte.
#define predictor and response variables
X = data[["mpg", "disp", "drat", "wt", "qsec"]]
y = data[["hp"]]
#define cross-validation method
cv = RepeatedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
mse = []
n = len (X)
# Calculate MSE with only the intercept
score = -1*model_selection. cross_val_score (PLSRegression(n_components=1),
n.p. ones ((n,1)), y, cv=cv, scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Calculate MSE using cross-validation, adding one component at a time
for i in np. arange (1, 6):
pls = PLSRegression(n_components=i)
score = -1*model_selection. cross_val_score (pls, scale(X), y, cv=cv,
scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
#plot test MSE vs. number of components
plt. plot (mse)
plt. xlabel (' Number of PLS Components ')
plt. ylabel (' MSE ')
plt. title (' hp ')
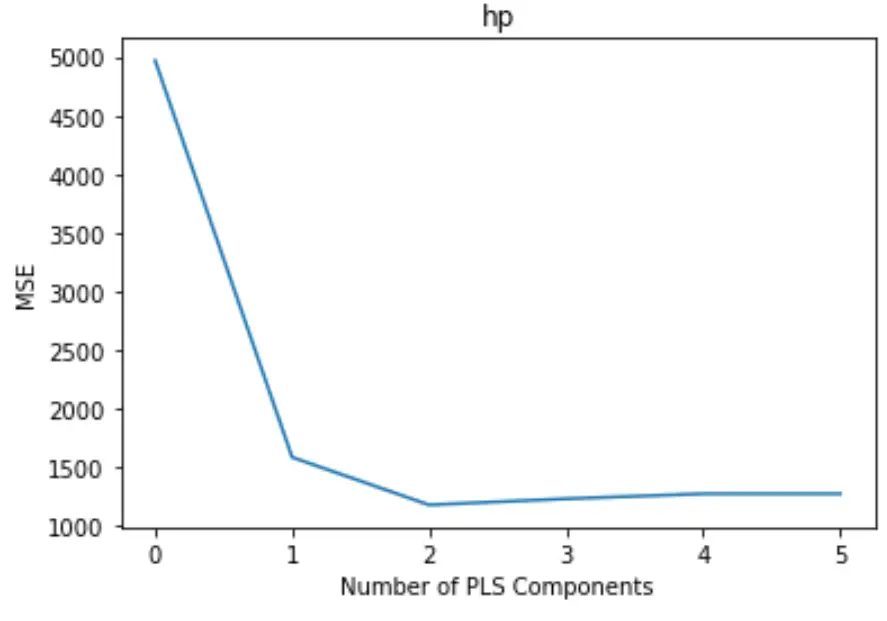
Il grafico mostra il numero di componenti PLS lungo l’asse x e il test MSE (errore quadratico medio) lungo l’asse y.
Dal grafico possiamo vedere che l’MSE del test diminuisce aggiungendo due componenti PLS, ma inizia ad aumentare quando aggiungiamo più di due componenti PLS.
Pertanto, il modello ottimale include solo i primi due componenti PLS.
Passaggio 4: utilizzare il modello finale per fare previsioni
Possiamo utilizzare il modello PLS finale con due componenti PLS per fare previsioni su nuove osservazioni.
Il codice seguente mostra come suddividere il set di dati originale in un set di training e uno di test e utilizzare il modello PLS con due componenti PLS per effettuare previsioni sul set di test.
#split the dataset into training (70%) and testing (30%) sets
X_train , _
#calculate RMSE
pls = PLSRegression(n_components=2)
pls. fit (scale(X_train), y_train)
n.p. sqrt (mean_squared_error(y_test, pls. predict (scale(X_test))))
29.9094
Vediamo che l’RMSE del test risulta essere 29.9094 . Questa è la deviazione media tra il valore hp previsto e il valore hp osservato per le osservazioni del set di test.
Il codice Python completo utilizzato in questo esempio può essere trovato qui .
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più