Cos'è il campionamento dell'ipercubo latino?
Il campionamento dell’ipercubo latino è un metodo che può essere utilizzato per campionare numeri casuali in cui i campioni sono distribuiti uniformemente su uno spazio campionario.
È ampiamente utilizzato per generare campioni chiamati campioni casuali controllati e viene spesso applicato nell’analisi Monte Carlo perché può ridurre significativamente il numero di simulazioni necessarie per ottenere risultati accurati.
Introduzione del campione
Per comprendere l’idea del campionamento dell’ipercubo latino, considera il seguente semplice esempio:
Supponiamo di voler ottenere un campione di 2 valori da un set di dati normalmente distribuito con media pari a 0 e deviazione standard pari a 1.
Se utilizzassimo un vero generatore di numeri casuali per ottenere questo campione, è possibile che entrambi i valori siano maggiori di 0 o entrambi i valori siano minori di 0.
Tuttavia, se utilizzassimo il campionamento dell’ipercubo latino per ottenere questo campione, allora sarebbe garantito che un valore sarebbe maggiore di 0 e un altro minore di 0, perché potremmo partizionare specificamente lo spazio campionario in una regione con valori maggiori di 0 e una regione con valori inferiori a 0, quindi selezionare un campione casuale da ciascuna regione.
Campionamento dell’ipercubo latino unidimensionale
L’idea alla base del campionamento unidimensionale dell’ipercubo latino è semplice: dividere una data CDF in n regioni diverse e scegliere casualmente un valore in ciascuna regione per ottenere un campione di dimensione n .
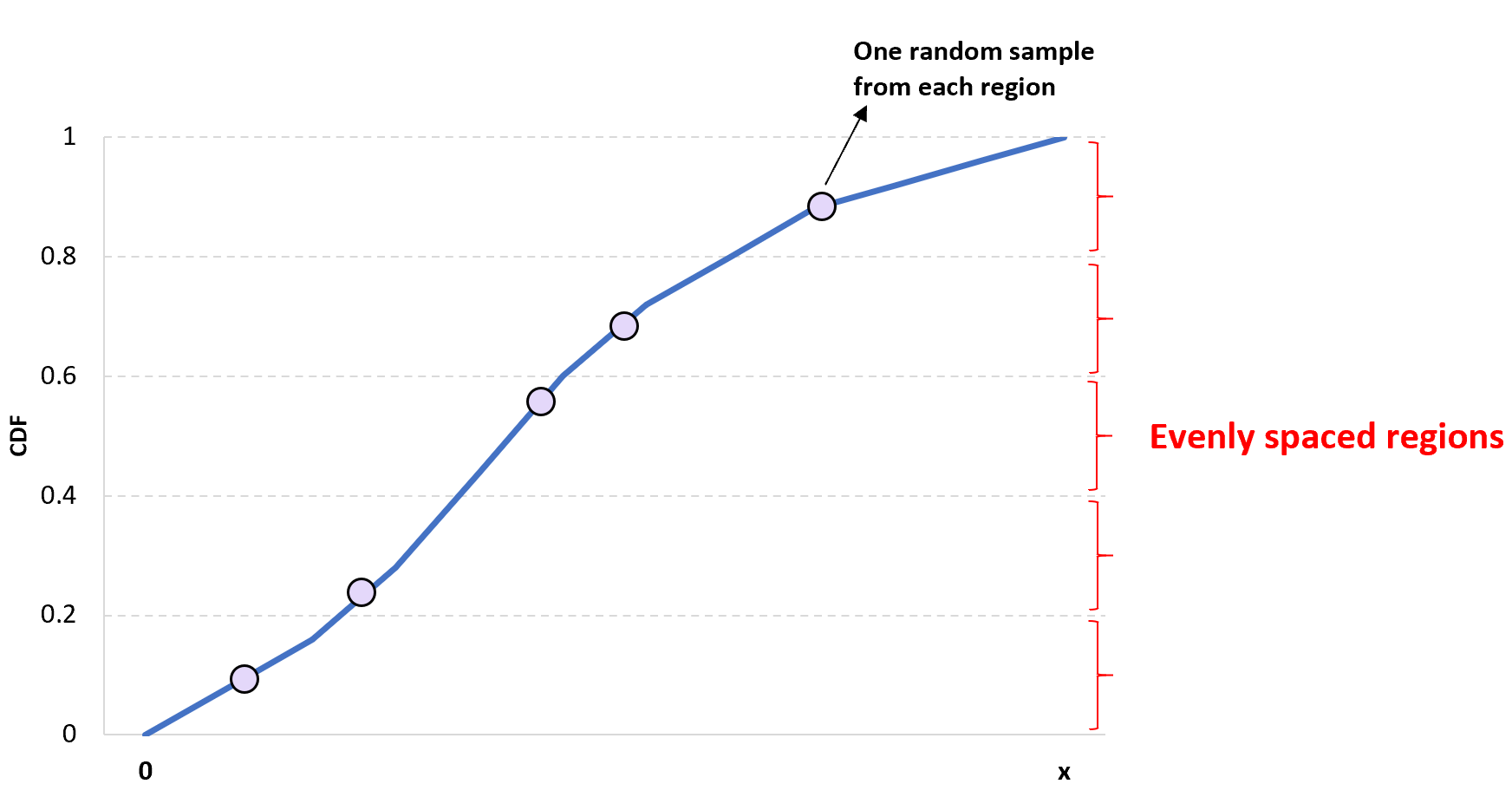
Il vantaggio di questo approccio è che garantisce che nel campione sia incluso almeno un valore per ciascuna regione.
Campionamento di ipercubi latini bidimensionali
Possiamo facilmente estendere l’idea del campionamento dell’ipercubo latino unidimensionale anche a due dimensioni.
Per due variabili, x e y, possiamo dividere lo spazio campionario di ciascuna variabile in n regioni equidistanti e selezionare un campione casuale da ciascuno spazio campionario per ottenere valori casuali su due dimensioni.
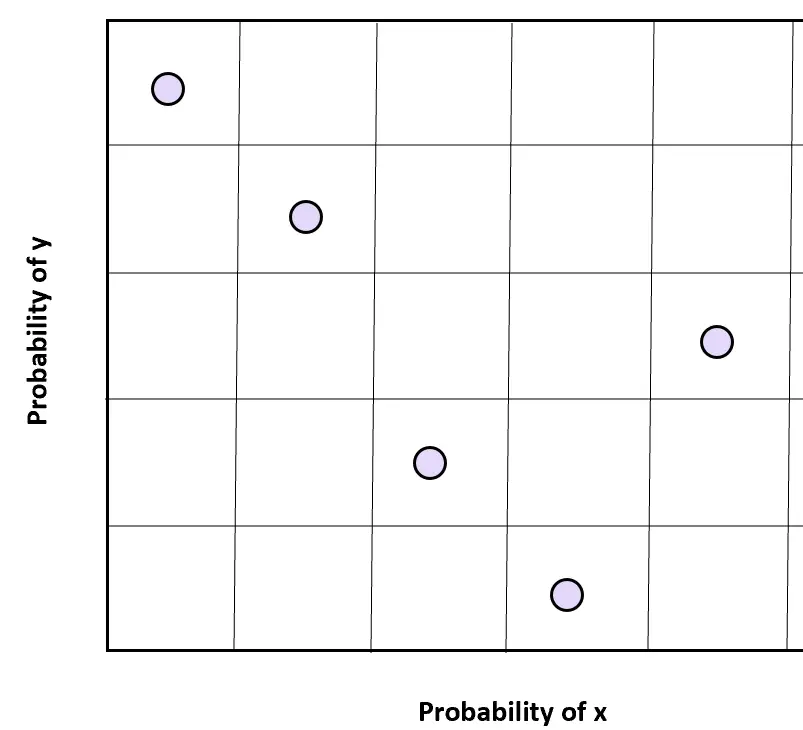
È importante notare che le due variabili devono essere indipendenti affinché questa tecnica di campionamento ottenga i risultati desiderati.
Campionamento dell’ipercubo latino N-dimensionale
Per eseguire il campionamento dell’ipercubo latino in dimensioni più grandi, possiamo semplicemente estendere l’idea del campionamento dell’ipercubo latino bidimensionale a un numero ancora maggiore di dimensioni.
Ciascuna variabile viene semplicemente divisa in regioni equidistanti e vengono quindi scelti campioni casuali da ciascuna regione per ottenere un campione casuale controllato.
Correlati: cosa sono i dati ad alta dimensione?
Perché utilizzare il campionamento dell’ipercubo latino?
Il vantaggio principale del campionamento dell’ipercubo latino è che produce campioni che riflettono la vera distribuzione sottostante e tendono a richiedere dimensioni del campione molto più piccole rispetto al semplice campionamento casuale .
Questo metodo di campionamento può essere particolarmente utile se si lavora con dati con un numero elevato di dimensioni e si desidera ottenere campioni casuali che riflettano sicuramente la vera distribuzione sottostante dei dati.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più