Come utilizzare proc cluster in sas (con esempio)
Il clustering è una tecnica di apprendimento automatico che tenta di trovare gruppi di osservazioni all’interno di un set di dati.
L’obiettivo è trovare cluster tali che le osservazioni all’interno di ciascun cluster siano abbastanza simili tra loro, mentre le osservazioni in cluster diversi siano abbastanza diverse l’una dall’altra.
Il modo più semplice per eseguire il clustering in SAS è utilizzare PROC CLUSTER .
L’esempio seguente mostra come utilizzare PROC CLUSTER nella pratica.
Esempio: come utilizzare PROC CLUSTER in SAS
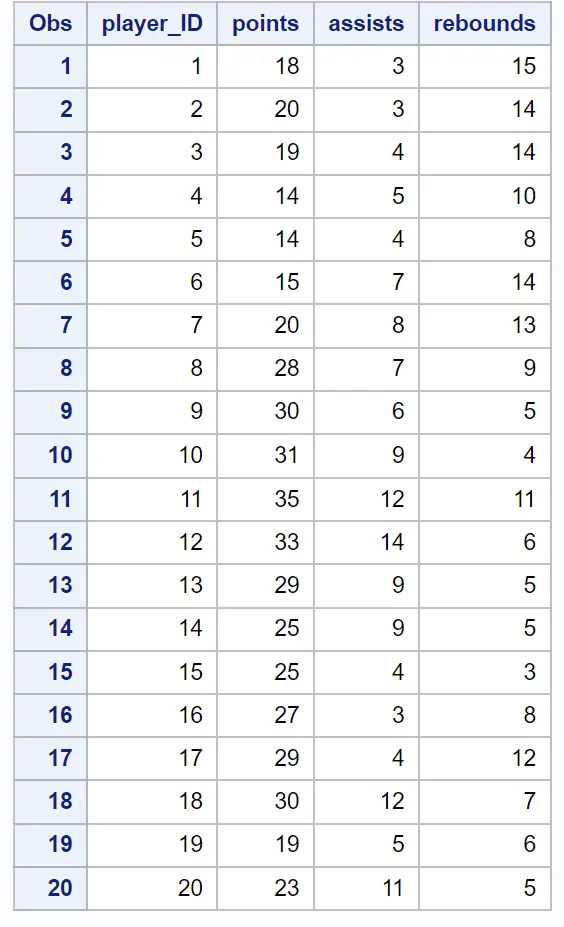
Supponiamo di avere il seguente set di dati contenente informazioni su punti, assist e rimbalzi per 20 diversi giocatori di basket:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
Diciamo che vogliamo fare qualche raggruppamento per cercare di identificare “cluster” di giocatori con statistiche simili tra loro.
Il codice seguente mostra come utilizzare PROC CLUSTER in SAS per eseguire il clustering:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
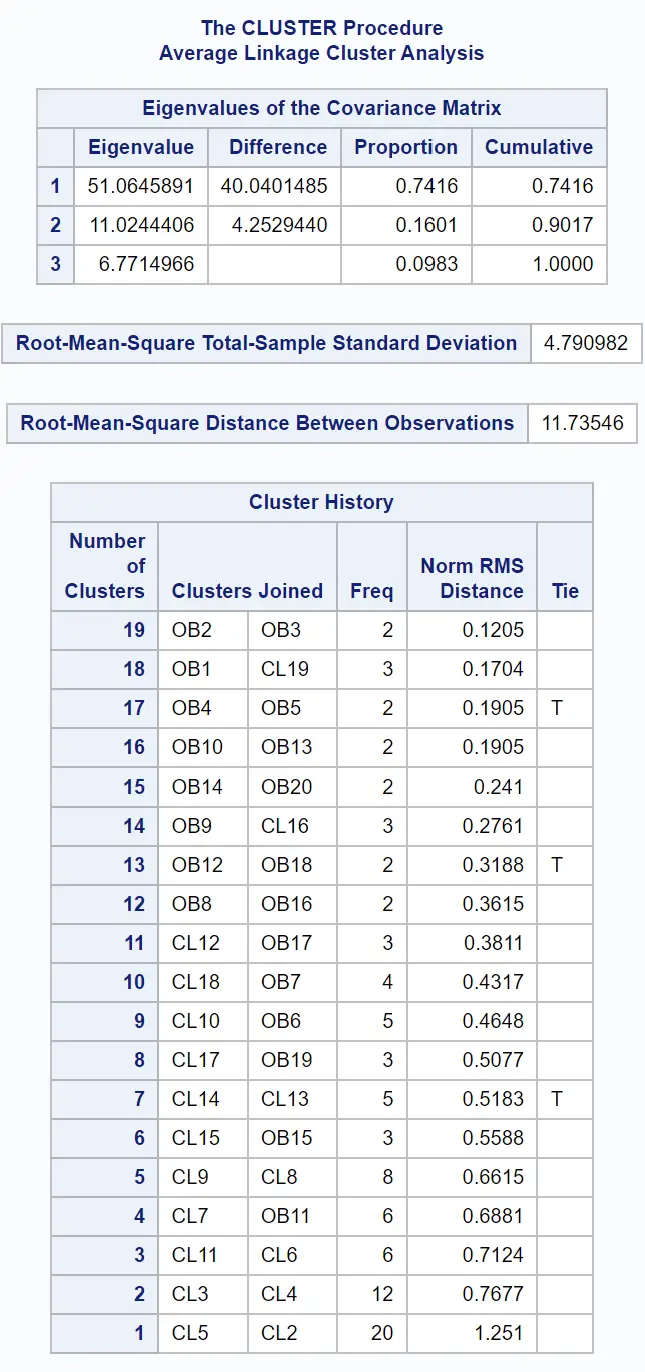
Le prime tabelle dei risultati forniscono informazioni su come è stato effettuato il clustering:
Viene anche prodotto un dendrogramma in modo da poter ispezionare visivamente la somiglianza tra le osservazioni nel set di dati:
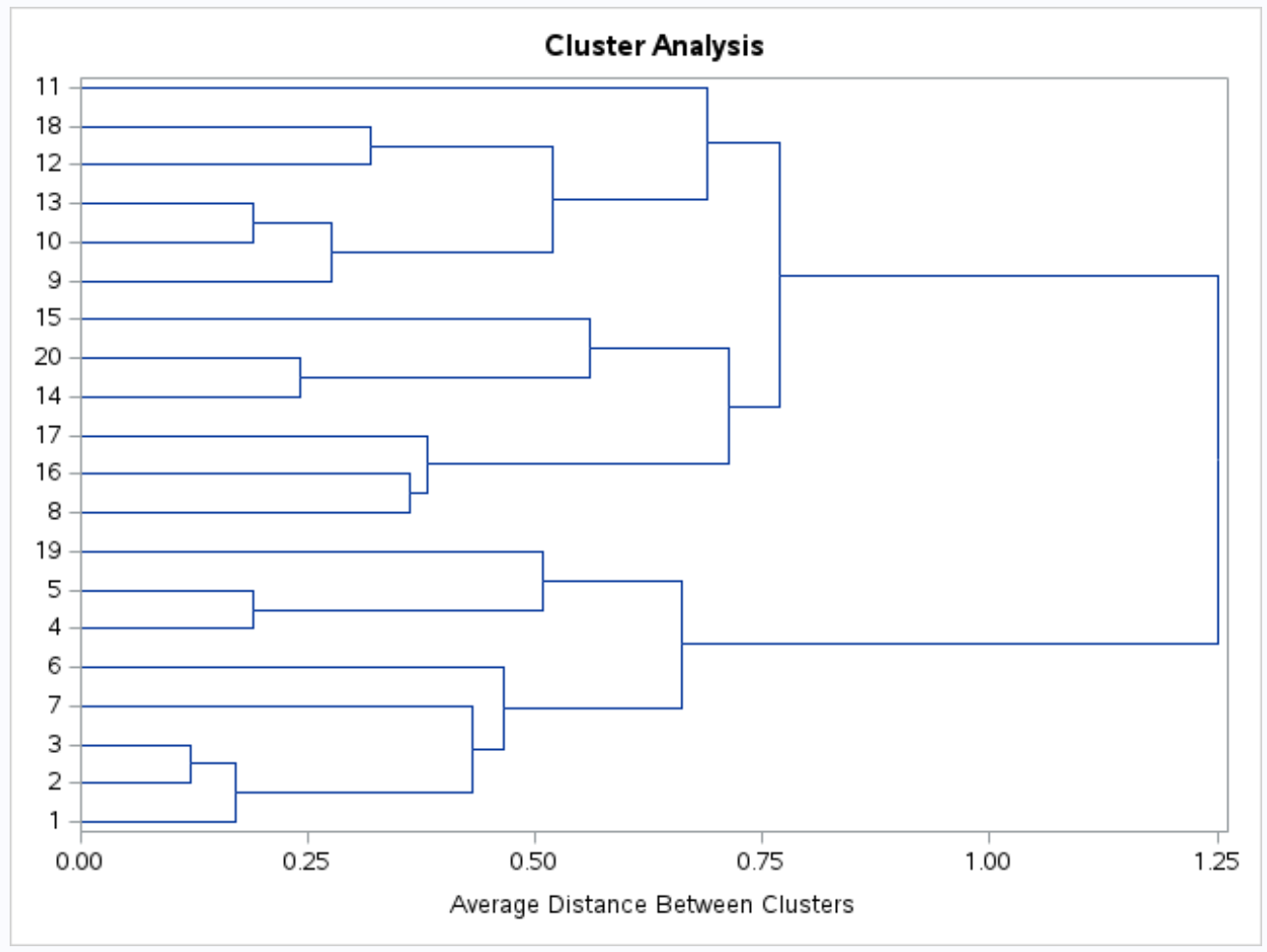
L’asse y mostra le singole osservazioni e l’asse x mostra la distanza media tra i cluster.
Osservando questo dendrogramma, sembra che le osservazioni ricadano naturalmente in tre gruppi:
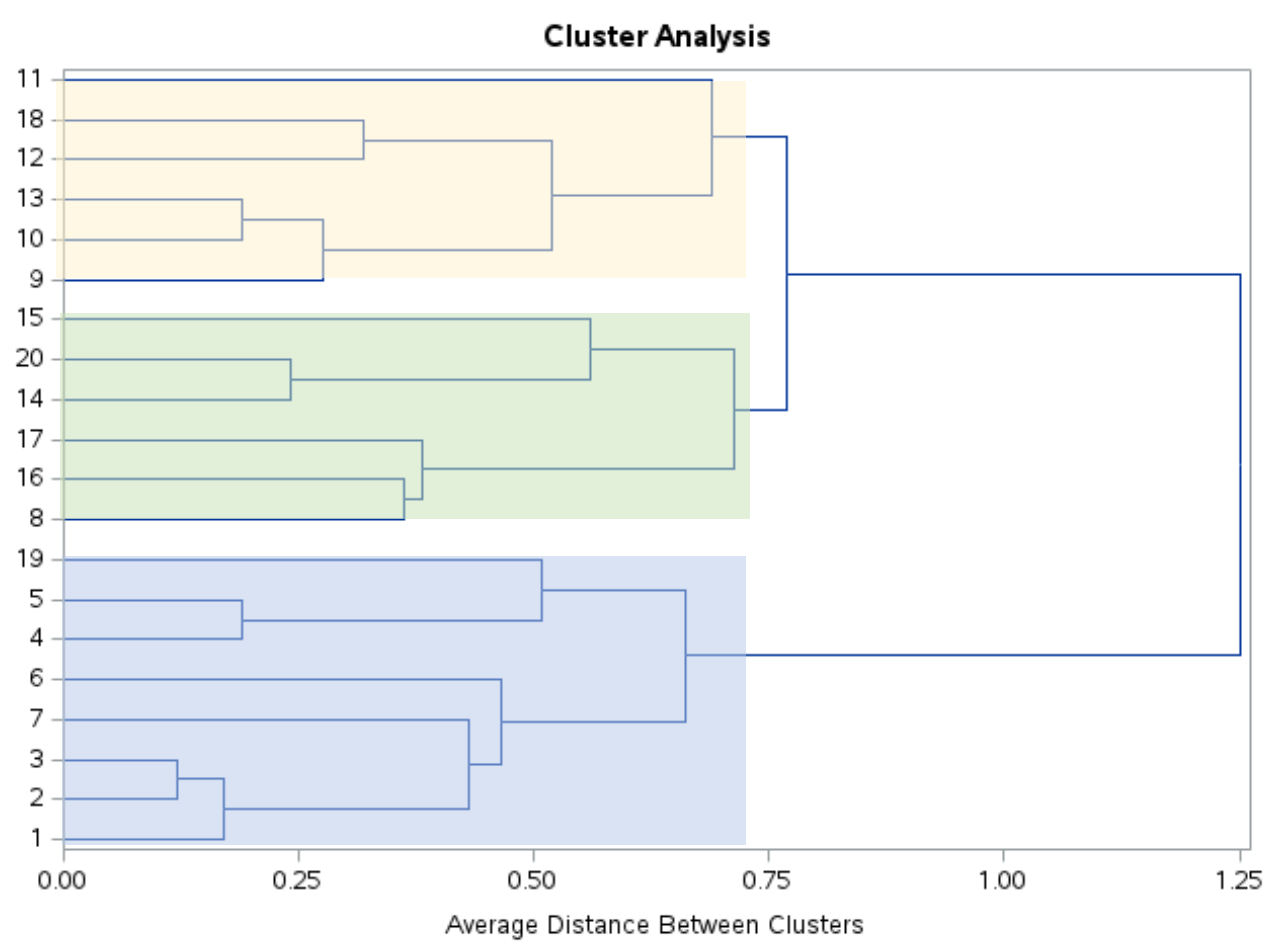
Possiamo quindi utilizzare l’istruzione PROC TREE con ncl=3 per dire a SAS di assegnare ciascuna osservazione nel set di dati originale a uno dei tre cluster:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Il set di dati risultante mostra ciascuna delle osservazioni originali insieme all’ammasso a cui appartengono:
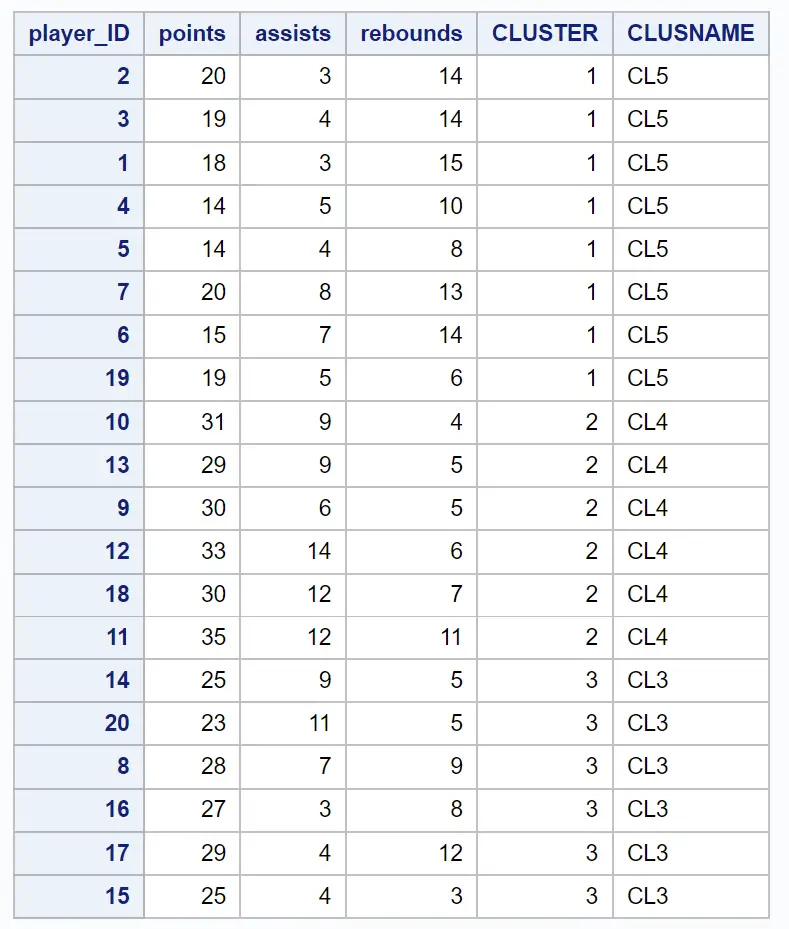
Ad esempio, possiamo vedere: che i giocatori con ID 2, 3, 1, 4, 5, 7, 6 e 19 appartengono tutti al cluster 1 .
Questo ci dice che questi otto giocatori sono “simili” in termini di variabili punti, assist e rimbalzi.
Nota : per questo esempio, abbiamo scelto di utilizzare la media come metodo di collegamento per il clustering. Fare riferimento alla documentazione SAS per un elenco completo degli altri metodi di associazione che è possibile utilizzare.
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in SAS:
Come eseguire l’analisi dei componenti principali in SAS
Come eseguire la regressione lineare multipla in SAS
Come eseguire la regressione logistica in SAS
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più