Come eseguire la codifica one-hot in python
La codifica one-hot viene utilizzata per convertire le variabili categoriali in un formato che può essere facilmente utilizzato dagli algoritmi di machine learning .
L’idea di base della codifica one-hot è quella di creare nuove variabili che assumano i valori 0 e 1 per rappresentare i valori categorici originali.
Ad esempio, l’immagine seguente mostra come effettueremo la codifica one-hot per convertire una variabile categoriale contenente i nomi dei team in nuove variabili contenenti solo valori 0 e 1:
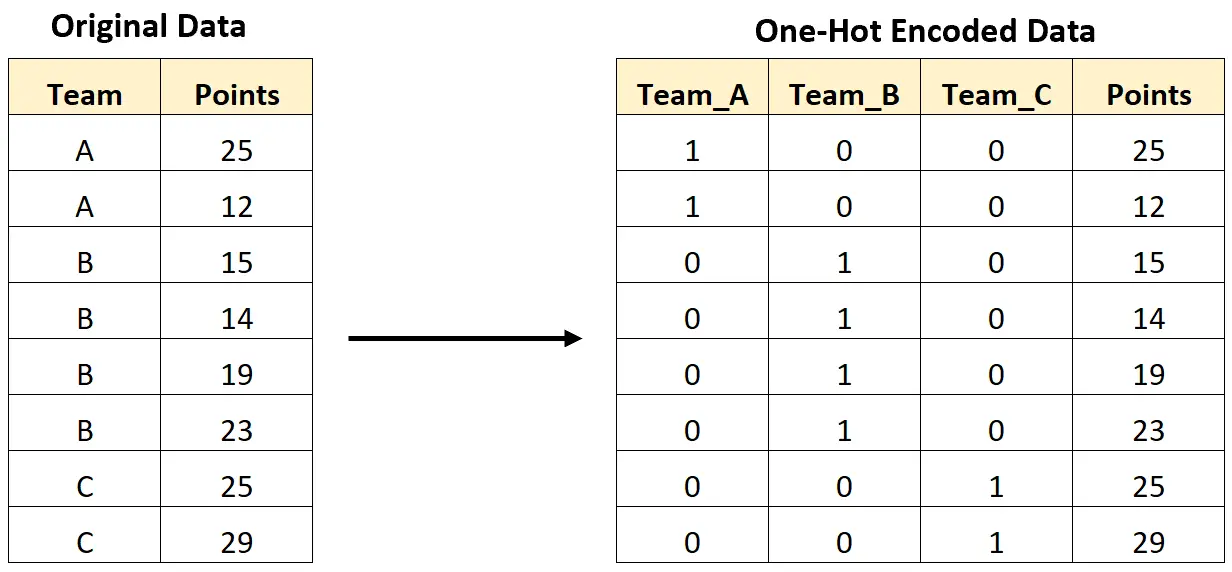
Il seguente esempio passo passo mostra come eseguire la codifica one-hot per questo set di dati esatto in Python.
Passaggio 1: creare i dati
Innanzitutto, creiamo il seguente DataFrame panda:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
Passaggio 2: eseguire la codifica one-hot
Successivamente, importiamo la funzione OneHotEncoder() dalla libreria sklearn e usiamola per eseguire la codifica a caldo sulla variabile ‘team’ nel DataFrame pandas:
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
Tieni presente che tre nuove colonne sono state aggiunte a DataFrame poiché la colonna “team” originale conteneva tre valori univoci.
Nota : puoi trovare la documentazione completa per la funzione OneHotEncoder() qui .
Passaggio 3: rimuovere la variabile categoriale originale
Infine, possiamo rimuovere la variabile originale ‘team’ dal DataFrame poiché non ne abbiamo più bisogno:
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Correlato: Come eliminare colonne in Panda (4 metodi)
Potremmo anche rinominare le colonne del DataFrame finale per renderle più facili da leggere:
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
La codifica one-hot è completa e ora possiamo inserire questo DataFrame di Panda in qualsiasi algoritmo di apprendimento automatico che desideriamo.
Risorse addizionali
Come calcolare una media troncata in Python
Come eseguire la regressione lineare in Python
Come eseguire la regressione logistica in Python
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più