Cosa sono i dati ad alta dimensione? (definizione ed esempi)
I dati ad alta dimensionalità si riferiscono a un set di dati in cui il numero di caratteristiche p è maggiore del numero di osservazioni N , spesso scritto come p >> N.
Ad esempio, un set di dati con p = 6 caratteristiche e solo N = 3 osservazioni verrebbe considerato dati ad alta dimensione perché il numero di caratteristiche è maggiore del numero di osservazioni.
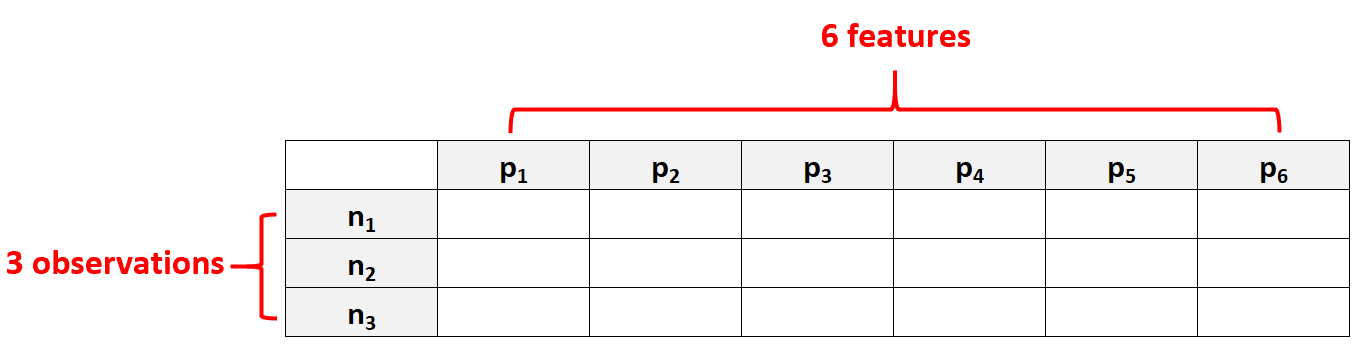
Un errore comune che le persone commettono è presumere che “dati ad alta dimensione” significhi semplicemente un set di dati con molte caratteristiche. Tuttavia, ciò non è corretto. Un set di dati può contenere 10.000 caratteristiche, ma se contiene 100.000 osservazioni, non è ad alta dimensionalità.
Nota: fare riferimento al capitolo 18 di Elementi di apprendimento statistico per una discussione approfondita della matematica alla base dei dati ad alta dimensione.
Perché i dati ad alta dimensione sono un problema?
Quando il numero di caratteristiche in un set di dati supera il numero di osservazioni, non avremo mai una risposta deterministica.
In altre parole, diventa impossibile trovare un modello in grado di descrivere la relazione tra le variabili predittive e la variabile risposta , perché non disponiamo di sufficienti osservazioni su cui addestrare il modello.
Esempi di dati ad alta dimensione
Gli esempi seguenti illustrano set di dati ad alta dimensione in diversi domini.
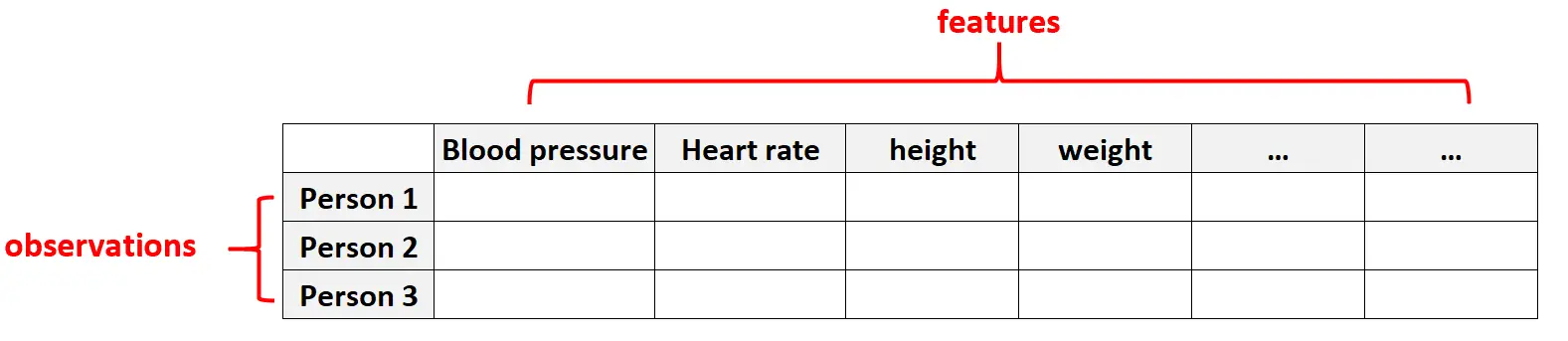
Esempio 1: dati sanitari
I dati ad alta dimensione sono comuni nei set di dati sanitari in cui il numero di caratteristiche per un dato individuo può essere enorme (ad esempio pressione sanguigna, frequenza cardiaca a riposo, stato del sistema immunitario, storia chirurgica, altezza, peso, condizioni esistenti, ecc.).
In questi set di dati, è comune che il numero di caratteristiche sia maggiore del numero di osservazioni.
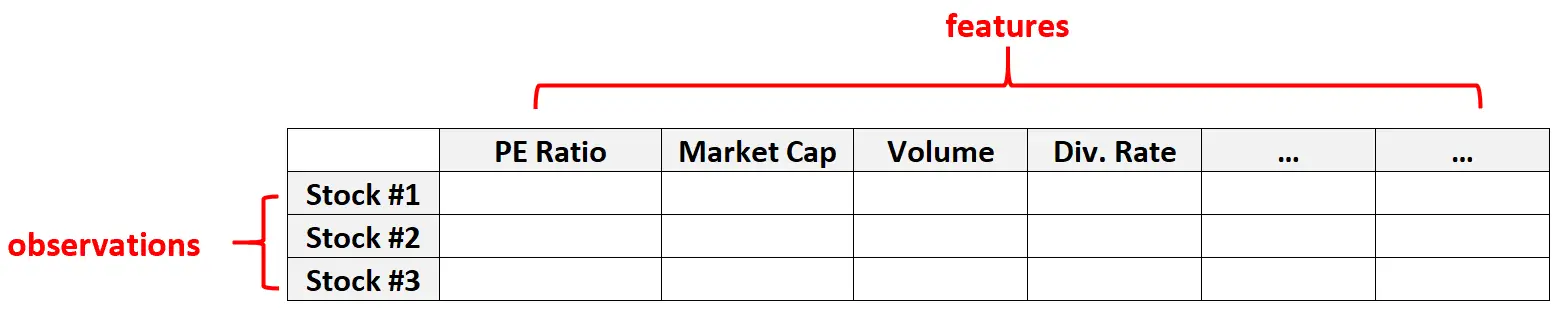
Esempio 2: dati finanziari
I dati ad alta dimensione sono comuni anche nei set di dati finanziari in cui il numero di caratteristiche per un dato titolo può essere piuttosto elevato (ad esempio rapporto PE, capitalizzazione di mercato, volume degli scambi, tasso di dividendo, ecc.)
In questi tipi di set di dati, è normale che il numero di entità sia molto maggiore del numero di singole azioni.
Esempio 3: Genomica
I dati ad alta dimensione sono comuni anche nel campo della genomica, dove il numero di caratteristiche genetiche di un dato individuo può essere enorme.

Come gestire dati di grandi dimensioni
Esistono due modi comuni per elaborare dati ad alta dimensione:
1. Scegli di includere meno funzionalità.
Il modo più ovvio per evitare di gestire dati ad alta dimensione è semplicemente includere meno funzionalità nel set di dati.
Esistono diversi modi per decidere quali funzionalità rimuovere da un set di dati, tra cui:
- Rimuovi funzionalità con molti valori mancanti: se una determinata colonna in un set di dati presenta molti valori mancanti, potresti essere in grado di rimuoverla completamente senza perdere molte informazioni.
- Rimuovi funzionalità a bassa varianza: se una determinata colonna in un set di dati ha valori che cambiano molto poco, potresti essere in grado di rimuoverla perché è improbabile che offra tante informazioni utili su una variabile di risposta rispetto ad altre funzionalità.
- Rimuovi funzionalità con una bassa correlazione con la variabile di risposta: se una determinata funzionalità non è altamente correlata con la variabile di risposta che ti interessa, probabilmente puoi rimuoverla dal set di dati, poiché è improbabile che sia una funzionalità utile in un modello.
2. Utilizzare un metodo di regolarizzazione.
Un altro modo per gestire dati ad alta dimensione senza rimuovere funzionalità dal set di dati è utilizzare una tecnica di regolarizzazione come:
- Analisi del componente principale
- Regressione delle componenti principali
- Regressione di picco
- Regressione al lazo
Ognuna di queste tecniche può essere utilizzata per elaborare in modo efficiente dati ad alta dimensione.
Puoi trovare un elenco completo di tutti i tutorial sul machine learning statistico in questa pagina .
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più