Cos'è una distribuzione aperta?
In statistica, una distribuzione aperta è una distribuzione di frequenza in cui una o più classi (o “classi”) sono aperte.
Ad esempio, la seguente distribuzione di frequenza rappresenta una distribuzione aperta in cui la classe più piccola è aperta:
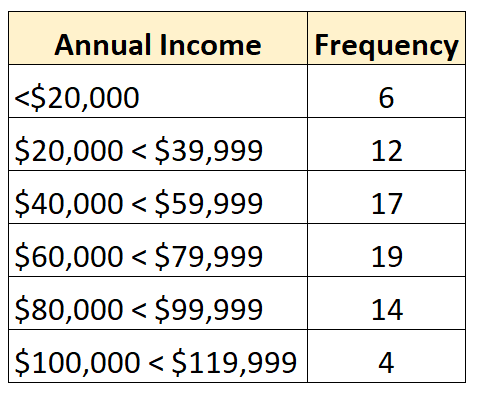
E la seguente distribuzione di frequenza mostra una distribuzione aperta in cui la classe più grande è aperta:
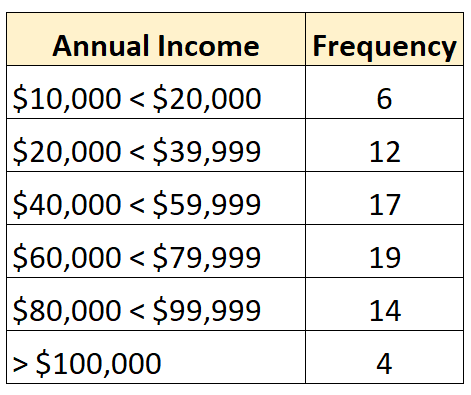
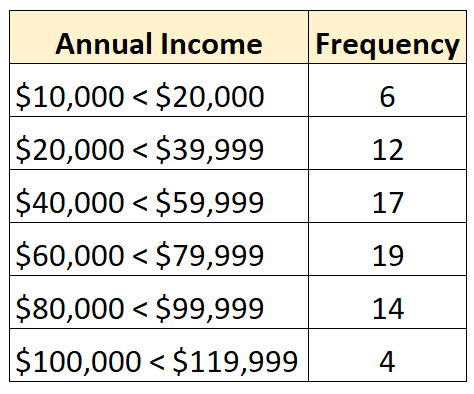
Al contrario, una distribuzione chiusa è quella in cui ciascuna classe della distribuzione di frequenza ha un limite superiore e inferiore, come il seguente:
Cosa causa le distribuzioni aperte?
Le distribuzioni aperte sono spesso il risultato della scelta dei ricercatori di raccogliere dati in modo tale che una delle classi risulti aperta.
Ad esempio, supponiamo che un ricercatore effettui un’indagine sui residenti di una determinata città e chieda loro qual è il loro reddito familiare annuale.
Il ricercatore può scegliere di fornire la risposta più ampia possibile “> $ 100.000” perché sa che i residenti ad alto reddito potrebbero non sentirsi a proprio agio nel condividere quanto guadagnano se è significativamente superiore a $ 100.000.
Al contrario, il ricercatore può scegliere di dare la risposta più breve possibile perché sa che anche i residenti che guadagnano molto poco non si sentiranno a proprio agio nel condividere quel poco che guadagnano.
In poche parole, i ricercatori spesso includono corsi aperti nei loro sondaggi perché vogliono massimizzare il numero di persone che si sentono a proprio agio nel rispondere alle domande del sondaggio.
Il problema con le distribuzioni aperte
Il problema con le distribuzioni aperte è che i dati reali vengono censurati . In altre parole, possiamo conoscere il numero di persone che guadagnano più di 100.000 dollari in una determinata città, ma in realtà non conosciamo il loro esatto reddito annuo.
È possibile che alcune persone guadagnino $ 150.000, $ 250.000, $ 500.000 o anche di più, ma non ne abbiamo idea poiché ciascuna di queste persone non può indicare di guadagnare “> $ 100.000” nell’indagine.
Poiché i dati sono censurati nelle distribuzioni aperte, non siamo nemmeno in grado di calcolare la media esatta e la deviazione standard dei valori nel set di dati poiché non abbiamo accesso a tutti i valori nei dati grezzi.
Come analizzare una distribuzione aperta
Poiché non è possibile calcolare la media esatta di una distribuzione aperta, spesso utilizziamo la mediana come misura del “centro” del set di dati.
Ricordiamo che la mediana rappresenta il valore medio del set di dati.
Quando si lavora con distribuzioni aperte, possiamo utilizzare la seguente formula per trovare la migliore stima della mediana:
Migliore stima della mediana: L + ((n/2 – F) / f) * w
Oro:
- L: Il limite inferiore del gruppo centrale
- n: il numero totale di osservazioni
- F: La frequenza cumulativa fino al gruppo centrale
- f: La frequenza del gruppo centrale
- w: La larghezza del gruppo centrale
Ad esempio, supponiamo di avere la seguente distribuzione aperta:
Ci sono un totale di 72 valori nel set di dati. Quindi, sappiamo che il valore mediano sarà compreso tra il 36° e il 37° valore più grande nel set di dati. Ciascuno di questi valori rientra nella classe “$60.000 – $79.999”, quindi sappiamo che il reddito mediano rientra in quell’intervallo.
La nostra migliore stima della mediana sarebbe:
Mediana: 60.000 + ((72/2 – 25) / 19) * 19.999 = $ 71.578
Questo valore rappresenta la nostra migliore stima del reddito medio annuo degli individui in questo set di dati.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più