Distribuzione di frequenza non raggruppata: definizione ed esempio
Supponiamo di condurre un sondaggio in cui chiediamo a 15 famiglie quanti animali hanno in casa. I risultati sono i seguenti:
1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 8
Un modo per riassumere questi risultati è creare una distribuzione di frequenza , che ci dice quanto spesso compaiono valori diversi in un set di dati.
Utilizziamo spesso distribuzioni di frequenza clusterizzate , in cui creiamo gruppi di valori e quindi riassumiamo il numero di osservazioni in un set di dati che rientrano in tali gruppi.
Ecco un esempio di distribuzione di frequenza raggruppata per i dati del nostro sondaggio:
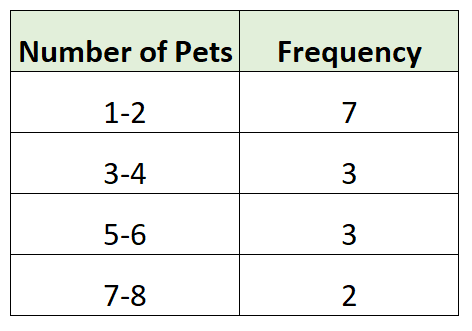
Per prima cosa abbiamo creato gruppi di dimensione 2 e poi abbiamo contato il numero di singole osservazioni del set di dati che rientravano in ciascun gruppo. Per esempio:
- 7 famiglie avevano 1 o 2 animali
- 3 famiglie avevano 3 o 4 animali
- 3 famiglie avevano 5 o 6 animali
- 2 famiglie avevano 7 o 8 animali
Un altro tipo di distribuzione di frequenza che potremmo creare è una distribuzione di frequenza non raggruppata , che mostra la frequenza di ogni singolo valore di dati anziché di gruppi di valori di dati.
Ecco un esempio di distribuzione di frequenza non clusterizzata per i dati del nostro sondaggio:
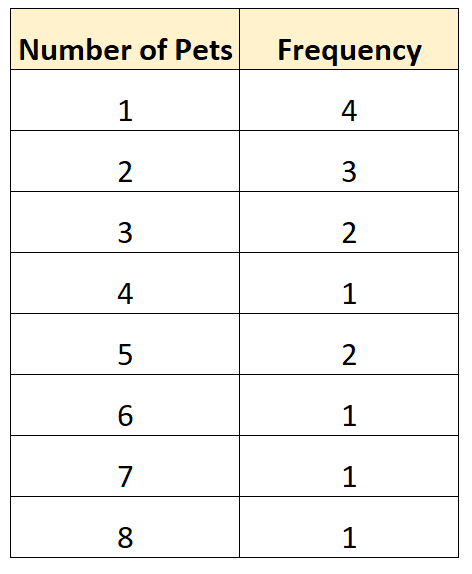
Questo tipo di distribuzione della frequenza ci consente di vedere direttamente quanto spesso si sono verificati valori diversi nel nostro set di dati. Per esempio:
- 4 famiglie avevano 1 animale
- 3 famiglie avevano 2 animali
- 2 famiglie avevano 3 animali
- 1 famiglia aveva 4 animali
E così via.
Quando utilizzare distribuzioni di frequenza non raggruppate
Le distribuzioni di frequenza non raggruppate possono essere utili quando vuoi vedere la frequenza con cui ogni singolo valore appare in un set di dati.
Tieni presente che le distribuzioni di frequenza non cluster funzionano meglio con piccoli set di dati in cui sono presenti solo pochi valori univoci.
Ad esempio, nei dati del nostro sondaggio precedente c’erano solo 8 valori univoci, quindi aveva senso creare una distribuzione di frequenza non clusterizzata.
Tuttavia, se avessimo migliaia di set di dati contenenti centinaia o valori univoci, una distribuzione di frequenza non cluster richiederebbe molto tempo e sarebbe difficile raccogliere informazioni.
Per insiemi di dati più grandi, ha senso costruire distribuzioni di frequenza raggruppate.
Come visualizzare distribuzioni di frequenza non raggruppate
Il modo più semplice per visualizzare i valori in una distribuzione di frequenza non raggruppata è creare un poligono di frequenza , che visualizza le frequenze di ogni singolo valore in un semplice grafico.
Ecco come apparirebbe un poligono di frequenza per i nostri dati di esempio:
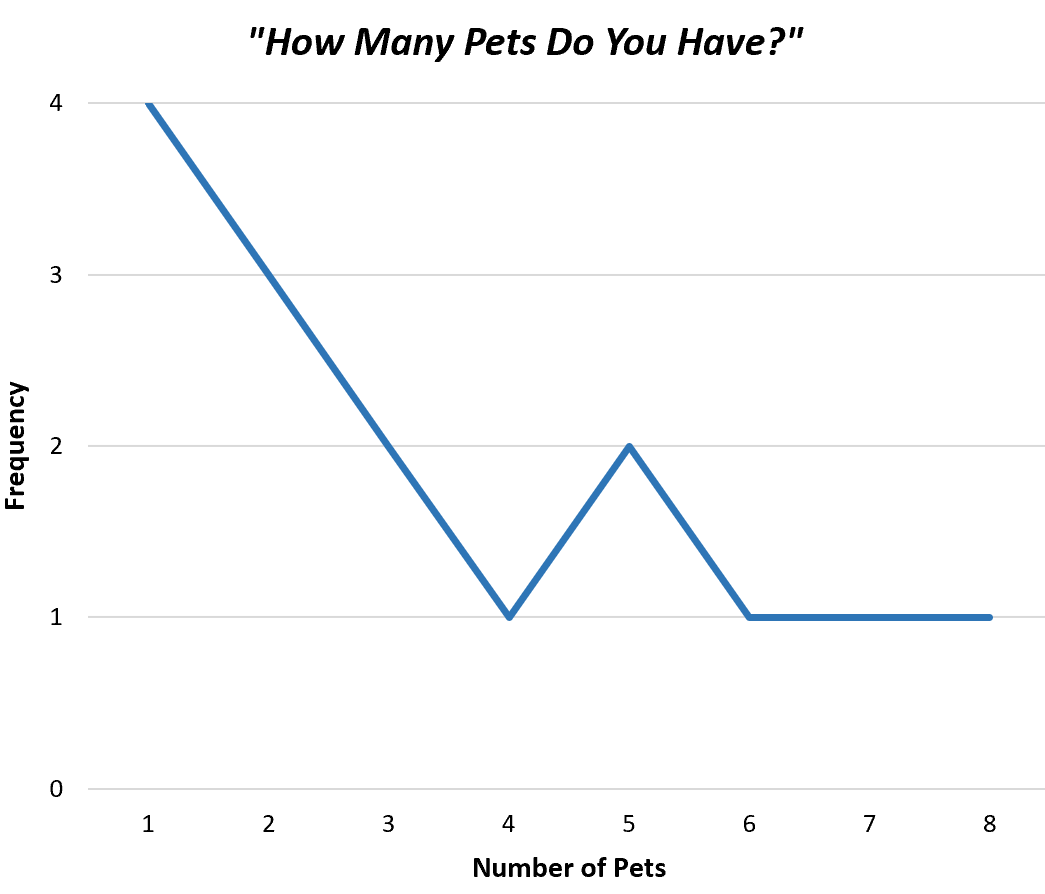
Questo ci aiuta a capire rapidamente la frequenza con cui ciascun valore appare nel set di dati.
In alternativa, potremmo creare un grafico a barre per visualizzare esattamente gli stessi dati utilizzando barre anziché una singola linea:
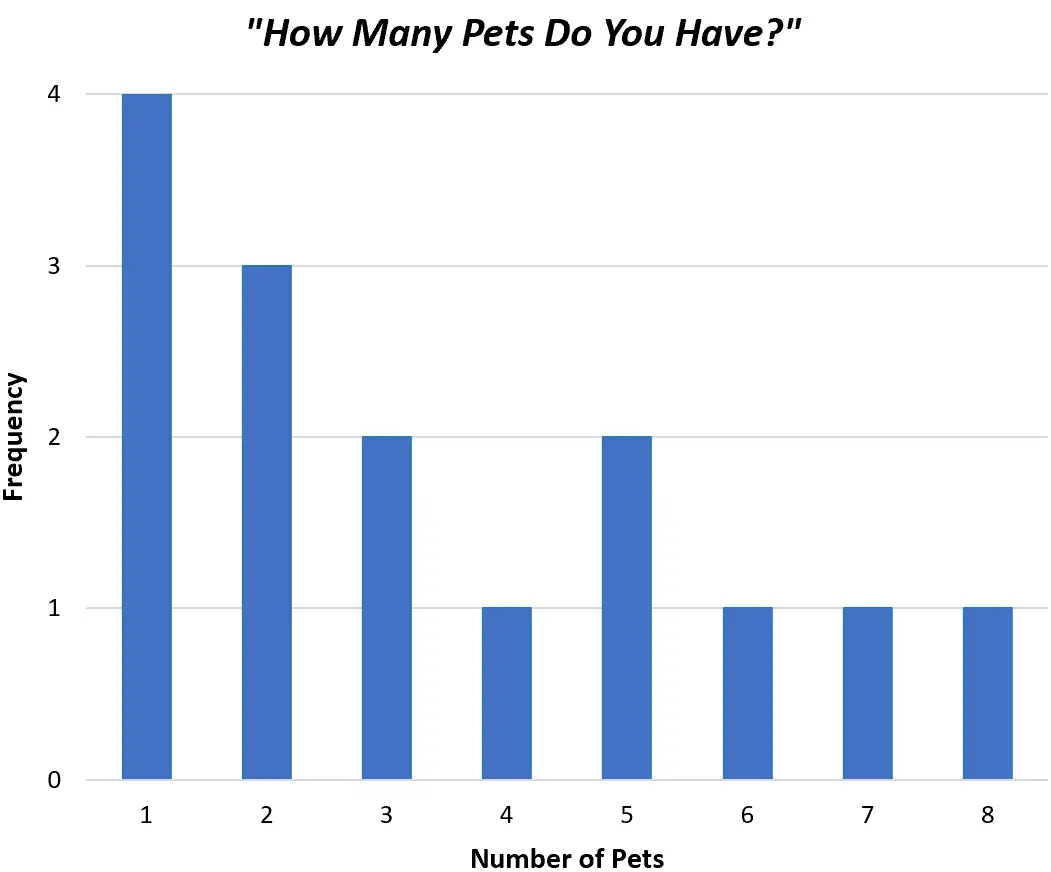
Entrambi i grafici ci consentono di comprendere rapidamente la distribuzione dei valori nel nostro set di dati.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più