Come utilizzare pandas get dummies – pd.get_dummies
Spesso nelle statistiche i set di dati con cui lavoriamo includono variabili categoriali .
Queste sono variabili che prendono nomi o etichette. Esempi inclusi:
- Stato civile (“sposato”, “celibe”, “divorziato”)
- Stato di fumatore (“fumatore”, “non fumatore”)
- Colore degli occhi (“blu”, “verde”, “nocciola”)
- Livello di istruzione (es. “scuola superiore”, “laurea”, “laurea magistrale”)
Quando ottimizziamo gli algoritmi di machine learning (come la regressione lineare , la regressione logistica , le foreste casuali e così via), spesso convertiamo le variabili categoriali in variabili fittizie , ovvero variabili numeriche utilizzate per rappresentare i dati categoriali.
Ad esempio, supponiamo di avere un set di dati contenente la variabile categoriale Gender . Per utilizzare questa variabile come predittore in un modello di regressione, sarebbe prima necessario convertirla in una variabile fittizia.
Per creare questa variabile fittizia, possiamo scegliere uno dei valori (“Maschio”) per rappresentare 0 e l’altro valore (“Femmina”) per rappresentare 1:
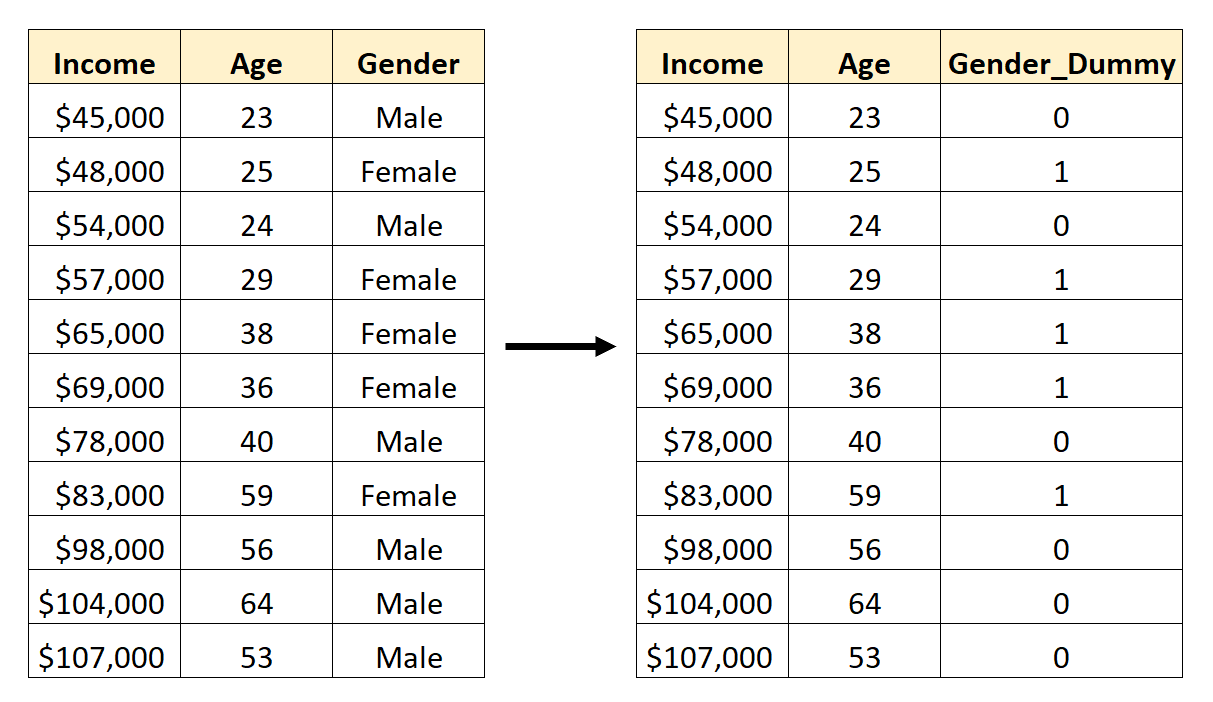
Come creare variabili fittizie in Pandas
Per creare dei manichini per una variabile in un DataFrame pandas, possiamo utilizzare la funzione pandas.get_dummies() , che utilizza la seguente sintassi di base:
pandas.get_dummies(dati, prefisso=Nessuno, colonne=Nessuno, drop_first=False)
Oro:
- data : il nome del DataFrame dei panda
- prefisso : una stringa da aggiungere all’inizio della nuova colonna della variabile fittizia
- colonne : il nome delle colonne da convertire in una variabile fittizia
- drop_first : se eliminare o meno la prima colonna della variabile fittizia
I seguenti esempi mostrano come utilizzare questa funzione nella pratica.
Esempio 1: creare una singola variabile fittizia
Supponiamo di avere i seguenti panda DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
Possiamo usare la funzione pd.get_dummies() per trasformare il genere in una variabile fittizia:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
La colonna sesso è ora una variabile fittizia dove:
- Un valore pari a 0 rappresenta “Femmina”
- Un valore pari a 1 rappresenta “Maschio”
Esempio 2: creare più variabili fittizie
Supponiamo di avere i seguenti panda DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
Possiamo usare la funzione pd.get_dummies() per convertire sesso e università in variabili fittizie:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
La colonna sesso è ora una variabile fittizia dove:
- Un valore pari a 0 rappresenta “Femmina”
- Un valore pari a 1 rappresenta “Maschio”
E la colonna del college ora è una variabile fittizia dove:
- Un valore pari a 0 rappresenta l’università “No”.
- Un valore pari a 1 rappresenta “Sì” al college
Risorse addizionali
Come utilizzare le variabili fittizie nell’analisi di regressione
Qual è la trappola della variabile fittizia?
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più