Come calcolare gli intervalli di confidenza in sas
Un intervallo di confidenza è un intervallo di valori che probabilmente contiene un parametro della popolazione con un certo livello di confidenza.
Questo tutorial spiega come calcolare i seguenti intervalli di confidenza in R:
1. Intervallo di confidenza per la media della popolazione
2. Intervallo di confidenza per una differenza nelle medie della popolazione
Andiamo!
Esempio 1: intervallo di confidenza per la media della popolazione in SAS
Supponiamo di avere il seguente set di dati contenente l’altezza (in pollici) di un campione casuale di 12 piante appartenenti tutte alla stessa specie:
/*create dataset*/ data my_data; inputHeight ; datalines ; 14 14 16 13 12 17 15 14 15 13 15 14 ; run ; /*view dataset*/ proc print data =my_data;
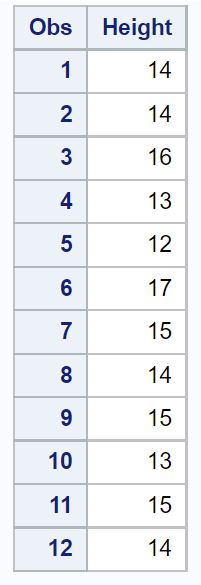
Supponiamo di voler calcolare un livello di confidenza del 95% per la reale dimensione media della popolazione di questa specie.
Possiamo usare il seguente codice in SAS per fare questo:
/*generate 95% confidence interval for population mean*/ proc ttest data =my_data alpha = 0.05 ; varHeight ; run ;
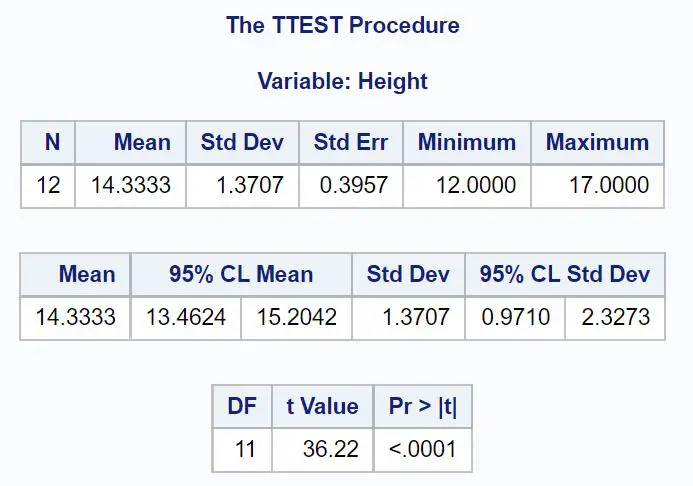
Il valore di Mean indica la media del campione e valori inferiori al 95% CL Mean mostrano l’intervallo di confidenza del 95% per la media della popolazione.
Dai risultati, possiamo vedere che l’intervallo di confidenza al 95% per il peso medio delle piante di questa popolazione è [13,4624 pollici, 15,2042 pollici] .
Esempio 2: intervallo di confidenza per la differenza nelle medie della popolazione in SAS
Supponiamo di avere il seguente set di dati contenente l’altezza (in pollici) di un campione casuale di piante appartenenti a due specie diverse:
/*create dataset*/
data my_data2;
input Species $Height;
datalines ;
At 14
At 14
At 16
At 13
AT 12
At 17
At 15
At 14
At 15
At 13
B15
B14
B 19
B 19
B17
B 18
B20
B 19
B17
B15
;
run ;
/*view dataset*/
proc print data =my_data2;
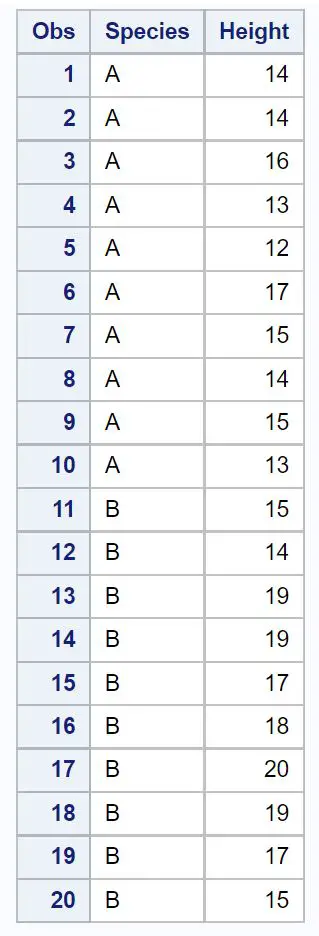
Supponiamo di voler calcolare un livello di confidenza del 95% per la differenza nella dimensione media della popolazione tra la specie A e la specie B.
Possiamo usare il seguente codice in SAS per fare questo:
/*sort data by Species to ensure confidence interval is calculated correctly*/
proc sort data =my_data2;
by Species;
run ;
/*generate 95% confidence interval for difference in population means*/
proc ttest data =my_data2 alpha = 0.05 ;
class Species;
varHeight ;
run ;
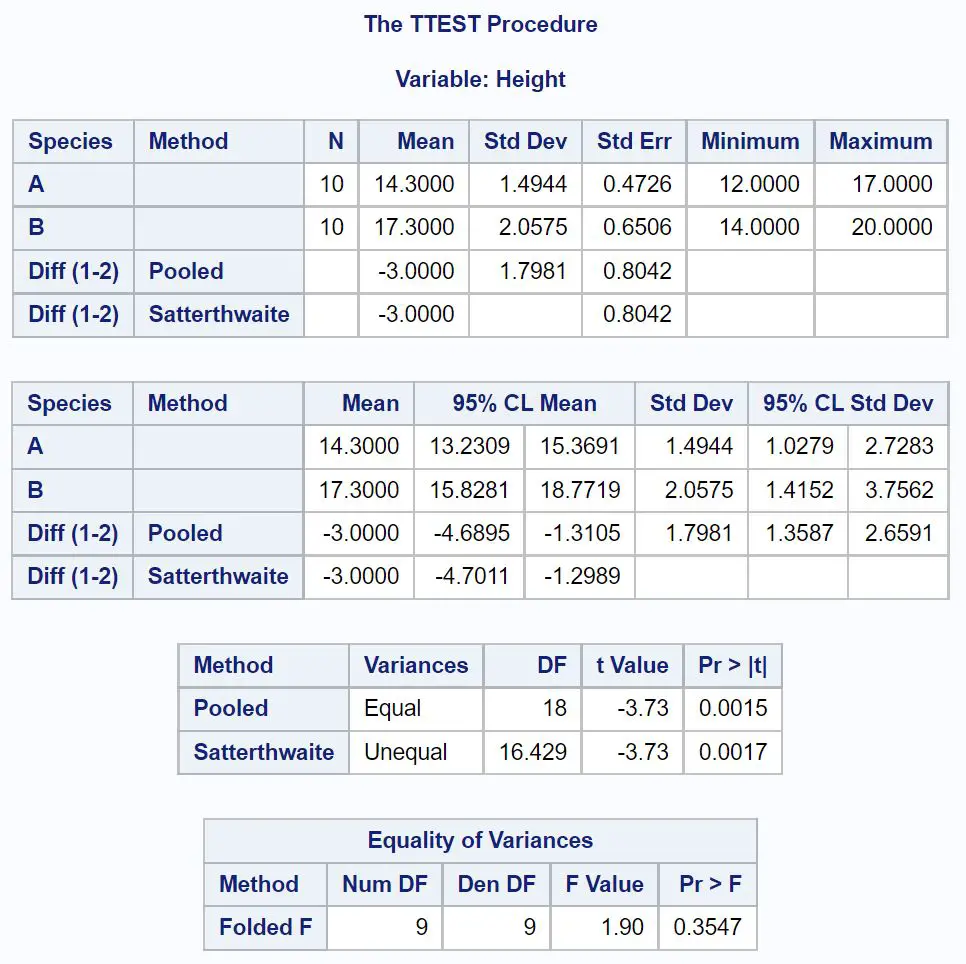
La prima tabella che dobbiamo osservare nel risultato è Uguaglianza delle varianze , che verifica se la varianza tra ciascun campione è uguale o meno.
Poiché in questa tabella il valore p non è inferiore a 0,05, possiamo supporre che le differenze tra i due gruppi siano uguali.
Quindi possiamo guardare la linea che utilizza la varianza aggregata per trovare l’intervallo di confidenza al 95% per la differenza nelle medie della popolazione.
Dal risultato, possiamo vedere che l’intervallo di confidenza al 95% per la differenza tra le medie della popolazione è [-4,6895 pollici, -1,1305 pollici] .
Questo ci dice che possiamo essere sicuri al 95% che la vera differenza tra l’altezza media delle piante della specie A e della specie B è compresa tra -4,6895 pollici e -1,1305 pollici.
Poiché 0 non rientra in questo intervallo di confidenza , ciò indica che esiste una differenza statisticamente significativa tra le medie delle due popolazioni.
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in SAS:
Come eseguire un test t per un campione in SAS
Come eseguire un t-test a due campioni in SAS
Come eseguire un t-test per campioni accoppiati in SAS
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più