K-medoidi in r: esempio passo passo
Il clustering è una tecnica di apprendimento automatico che tenta di trovare gruppi o cluster di osservazioni all’interno di un set di dati.
L’obiettivo è trovare cluster tali che le osservazioni all’interno di ciascun cluster siano abbastanza simili tra loro, mentre le osservazioni in cluster diversi siano abbastanza diverse l’una dall’altra.
Il clustering è una forma di apprendimento non supervisionato perché stiamo semplicemente cercando di trovare la struttura all’interno di un set di dati invece di prevedere il valore di una variabile di risposta .
Il clustering viene spesso utilizzato nel marketing quando le aziende hanno accesso a informazioni quali:
- Reddito familiare
- Dimensione della famiglia
- Capofamiglia Professione
- Distanza dall’area urbana più vicina
Quando queste informazioni sono disponibili, il clustering può essere utilizzato per identificare famiglie simili e che potrebbero avere maggiori probabilità di acquistare determinati prodotti o di rispondere meglio a un certo tipo di pubblicità.
Una delle forme più comuni di clustering è nota come clustering k-mean .
Sfortunatamente, questo metodo può essere influenzato da valori anomali, motivo per cui un’alternativa spesso utilizzata è il clustering k-medoids .
Cos’è il clustering K-Medoids?
Il clustering K-medoids è una tecnica in cui inseriamo ciascuna osservazione in un set di dati in uno dei cluster K.
L’obiettivo finale è quello di avere K cluster in cui le osservazioni all’interno di ciascun cluster sono abbastanza simili tra loro mentre le osservazioni nei diversi cluster sono abbastanza diverse l’una dall’altra.
In pratica, utilizziamo i seguenti passaggi per eseguire il clustering K-means:
1. Scegli un valore per K.
- Innanzitutto, dobbiamo decidere quanti cluster vogliamo identificare nei dati. Spesso dobbiamo semplicemente testare diversi valori diversi per K e analizzare i risultati per vedere quale numero di cluster sembra avere più senso per un dato problema.
2. Assegnare casualmente ciascuna osservazione a un cluster iniziale, da 1 a K.
3. Eseguire la seguente procedura finché le assegnazioni dei cluster non smettono di cambiare.
- Per ciascuno dei K cluster, calcola il centro di gravità del cluster. Questo è il vettore delle p mediane delle caratteristiche per le osservazioni del k -esimo ammasso.
- Assegna ciascuna osservazione al cluster con il baricentro più vicino. Qui, il più vicino è definito utilizzando la distanza euclidea .
Nota tecnica:
Poiché k-medoids calcola i centroidi del cluster utilizzando le mediane anziché le medie, tende ad essere più robusto rispetto ai valori anomali rispetto a k-means.
In pratica, se non sono presenti valori anomali estremi nel set di dati, k-medie e k-medoidi produrranno risultati simili.
Raggruppamento dei K-Medoidi in R
Il tutorial seguente fornisce un esempio passo passo di come eseguire il clustering k-medoids in R.
Passaggio 1: caricare i pacchetti necessari
Innanzitutto, caricheremo due pacchetti contenenti diverse funzioni utili per il clustering di k-medoid in R.
library (factoextra) library (cluster)
Passaggio 2: caricare e preparare i dati
Per questo esempio, utilizzeremo il set di dati USArrests integrato in R, che contiene il numero di arresti ogni 100.000 persone in ciascuno stato degli Stati Uniti nel 1973 per omicidio , aggressione e stupro , nonché la percentuale della popolazione di ciascuno stato che vive in aree urbane le zone. , UrbanPop .
Il codice seguente mostra come eseguire le seguenti operazioni:
- Carica il set di dati sugli arresti USA
- Rimuovi tutte le righe con valori mancanti
- Scalare ciascuna variabile nel set di dati in modo che abbia una media pari a 0 e una deviazione standard pari a 1
#load data df <-USArrests #remove rows with missing values df <- na. omitted (df) #scale each variable to have a mean of 0 and sd of 1 df <- scale(df) #view first six rows of dataset head(df) Murder Assault UrbanPop Rape Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473 Alaska 0.50786248 1.1068225 -1.2117642 2.484202941 Arizona 0.07163341 1.4788032 0.9989801 1.042878388 Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602 California 0.27826823 1.2628144 1.7589234 2.067820292 Colorado 0.02571456 0.3988593 0.8608085 1.864967207
Passaggio 3: trovare il numero ottimale di cluster
Per eseguire il clustering k-medoid in R, possiamo utilizzare la funzione pam() , che sta per “partitioning around medians” e utilizza la seguente sintassi:
pam(data, k, metrica = “euclidea”, stand = FALSE)
Oro:
- dati: nome del set di dati.
- k: il numero di cluster.
- metrica: la metrica da utilizzare per calcolare la distanza. Il valore predefinito è Euclidean ma è anche possibile specificare manhattan .
- stand: se normalizzare o meno ciascuna variabile nel set di dati. Il valore predefinito è falso.
Poiché non sappiamo in anticipo quale numero di cluster è ottimale, creeremo due diversi grafici che possono aiutarci a decidere:
1. Numero di cluster rispetto al totale nella somma dei quadrati
Innanzitutto, utilizzeremo la funzione fviz_nbclust() per creare un grafico del numero di cluster rispetto al totale nella somma dei quadrati:
fviz_nbclust(df, pam, method = “ wss ”)
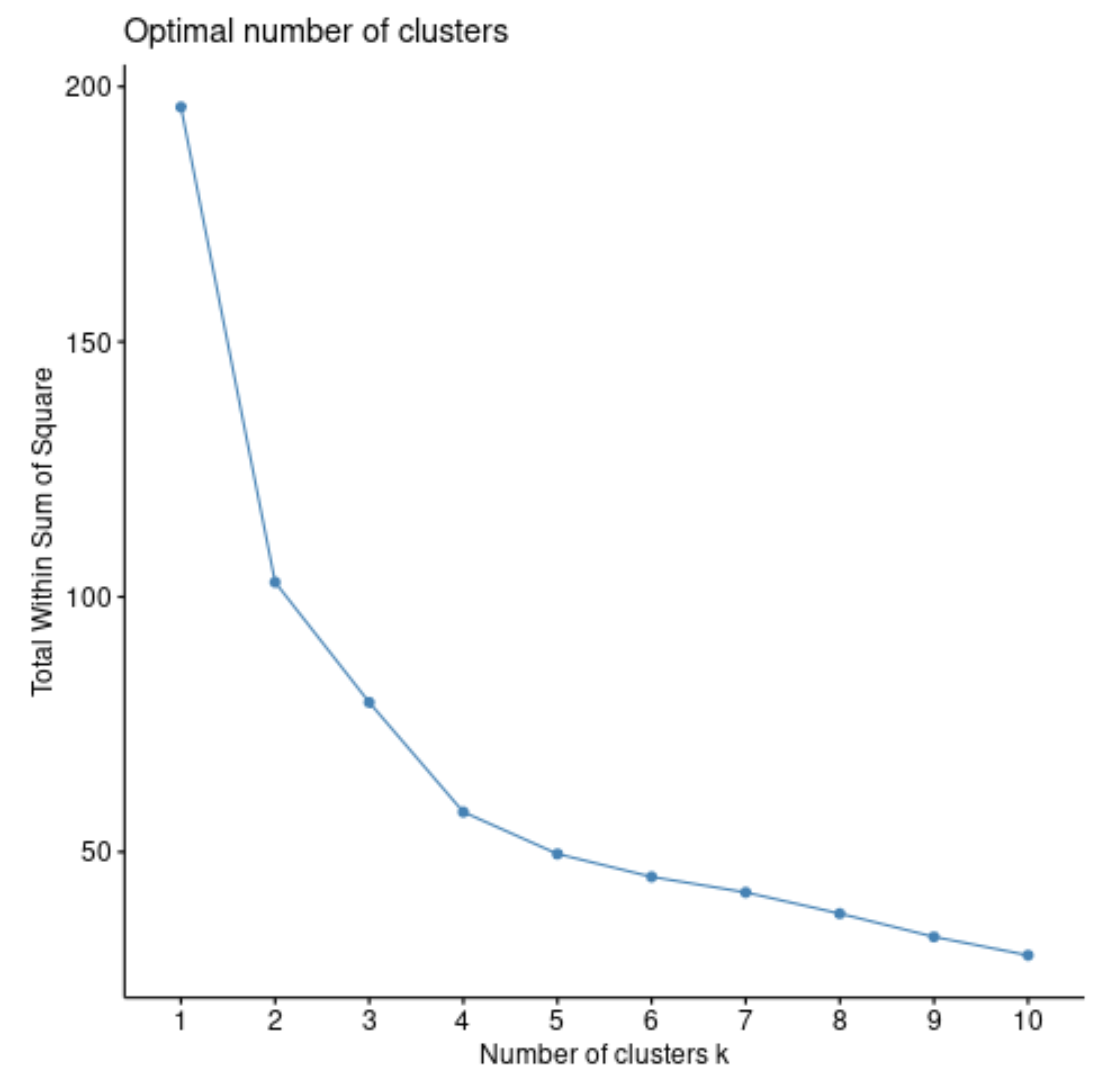
Il totale nella somma dei quadrati generalmente aumenterà sempre all’aumentare del numero di cluster. Quindi, quando creiamo questo tipo di trama, cerchiamo un “ginocchio” in cui la somma dei quadrati inizia a “piegarsi” o a livellarsi.
Il punto di curvatura del grafico corrisponde generalmente al numero ottimale di cluster. Al di là di questa cifra, è probabile che si verifichi un overfitting .
Per questo grafico, sembra che ci sia una piccola piega o “piegatura” in k = 4 cluster.
2. Numero di cluster rispetto alle statistiche del gap
Un altro modo per determinare il numero ottimale di cluster è utilizzare una metrica chiamata statistica di deviazione , che confronta la variazione totale intra-cluster per diversi valori di k con i loro valori attesi per una distribuzione senza clustering.
Possiamo calcolare la statistica del gap per ciascun numero di cluster utilizzando la funzione clusGap() dal pacchetto cluster , nonché un grafico dei cluster rispetto alle statistiche del gap utilizzando la funzione fviz_gap_stat() :
#calculate gap statistic based on number of clusters gap_stat <- clusGap(df, FUN = pam, K.max = 10, #max clusters to consider B = 50) #total bootstrapped iterations #plot number of clusters vs. gap statistic fviz_gap_stat(gap_stat)
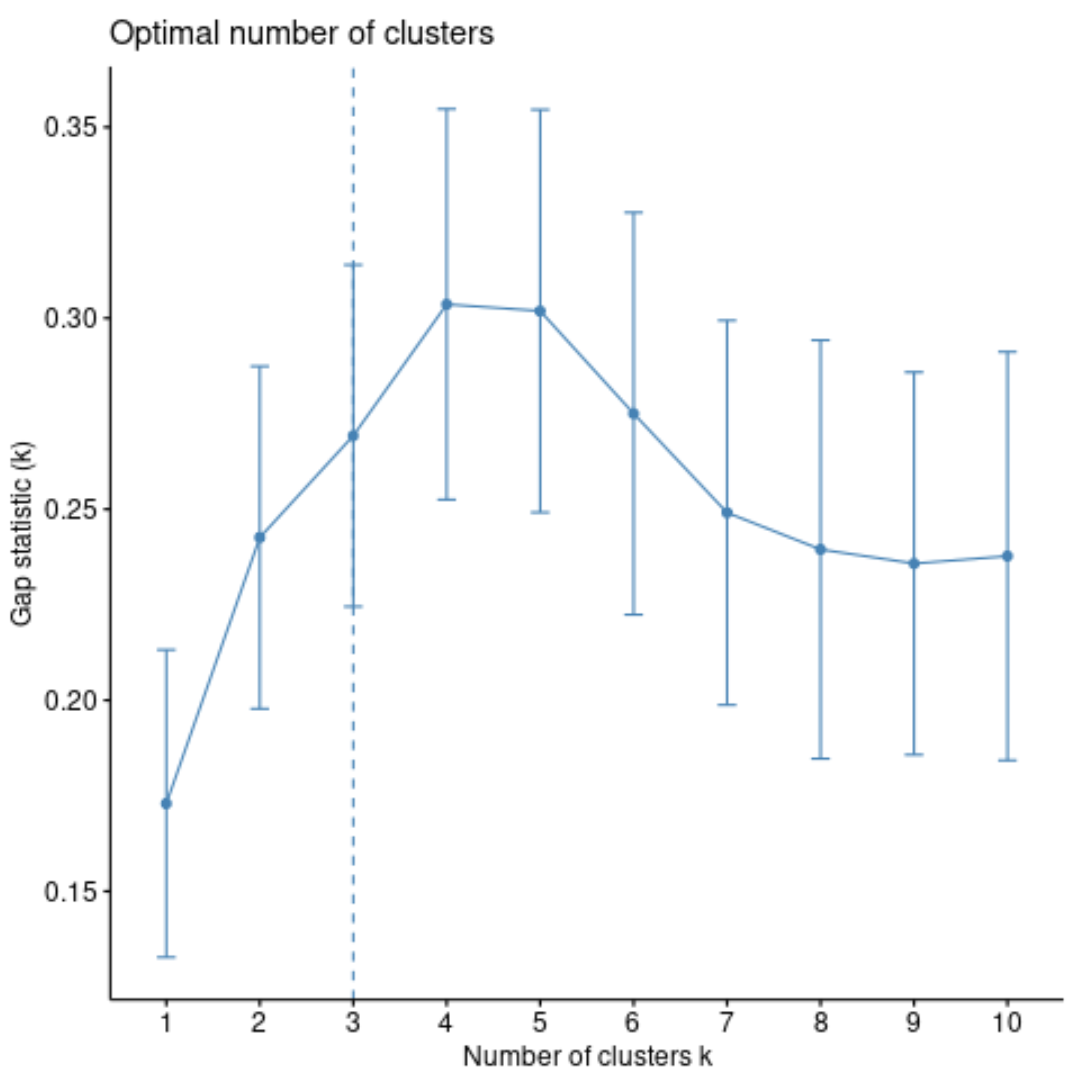
Dal grafico possiamo vedere che la statistica del gap è massima con k = 4 cluster, che corrisponde al metodo del gomito utilizzato in precedenza.
Passaggio 4: eseguire il clustering K-Medoids con Optimal K
Infine, possiamo eseguire il clustering di k-medoidi sul set di dati utilizzando il valore ottimale per k di 4:
#make this example reproducible set.seed(1) #perform k-medoids clustering with k = 4 clusters kmed <- pam(df, k = 4) #view results kmed ID Murder Assault UrbanPop Rape Alabama 1 1.2425641 0.7828393 -0.5209066 -0.003416473 Michigan 22 0.9900104 1.0108275 0.5844655 1.480613993 Oklahoma 36 -0.2727580 -0.2371077 0.1699510 -0.131534211 New Hampshire 29 -1.3059321 -1.3650491 -0.6590781 -1.252564419 Vector clustering: Alabama Alaska Arizona Arkansas California 1 2 2 1 2 Colorado Connecticut Delaware Florida Georgia 2 3 3 2 1 Hawaii Idaho Illinois Indiana Iowa 3 4 2 3 4 Kansas Kentucky Louisiana Maine Maryland 3 3 1 4 2 Massachusetts Michigan Minnesota Mississippi Missouri 3 2 4 1 3 Montana Nebraska Nevada New Hampshire New Jersey 3 3 2 4 3 New Mexico New York North Carolina North Dakota Ohio 2 2 1 4 3 Oklahoma Oregon Pennsylvania Rhode Island South Carolina 3 3 3 3 1 South Dakota Tennessee Texas Utah Vermont 4 1 2 3 4 Virginia Washington West Virginia Wisconsin Wyoming 3 3 4 4 3 Objective function: build swap 1.035116 1.027102 Available components: [1] "medoids" "id.med" "clustering" "objective" "isolation" [6] "clusinfo" "silinfo" "diss" "call" "data"
Si noti che tutti e quattro i centroidi del cluster sono osservazioni effettive nel set di dati. Nella parte superiore dell’output, possiamo vedere che i quattro centroidi si trovano nei seguenti stati:
- Alabama
- Michigan
- Oklahoma
- New Hampshire
Possiamo visualizzare i cluster su un grafico a dispersione che mostra le prime due componenti principali sugli assi utilizzando la funzione fivz_cluster() :
#plot results of final k-medoids model
fviz_cluster(kmed, data = df)
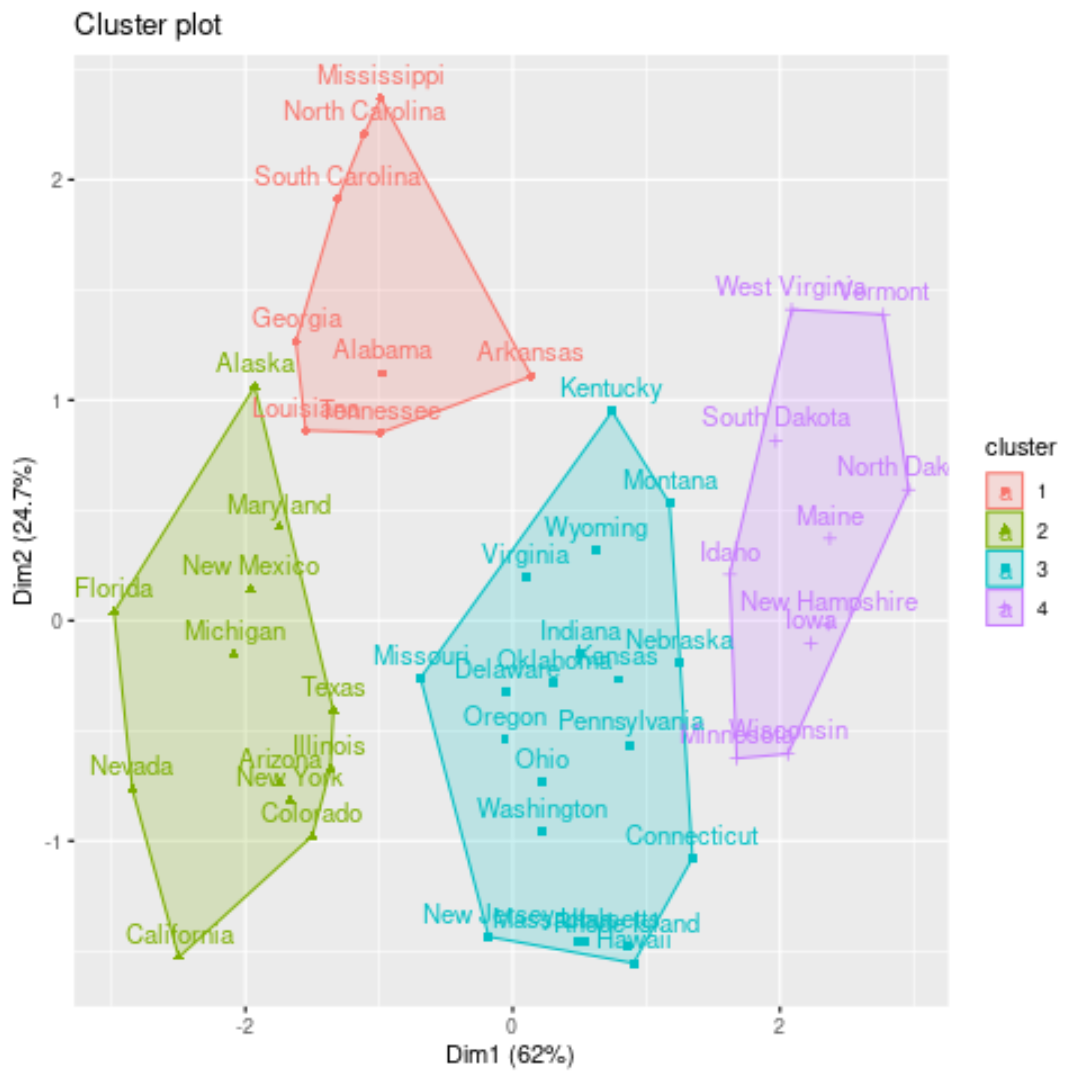
Possiamo anche aggiungere le assegnazioni dei cluster di ciascuno stato al set di dati originale:
#add cluster assignment to original data
final_data <- cbind(USArrests, cluster = kmed$cluster)
#view final data
head(final_data)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 1
Alaska 10.0 263 48 44.5 2
Arizona 8.1 294 80 31.0 2
Arkansas 8.8 190 50 19.5 1
California 9.0 276 91 40.6 2
Colorado 7.9 204 78 38.7 2
Puoi trovare il codice R completo utilizzato in questo esempio qui .
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più