Come calcolare la distanza di mahalanobis in spss
La distanza di Mahalanobis è la distanza tra due punti in uno spazio multivariato. Viene spesso utilizzato per rilevare valori anomali nelle analisi statistiche che coinvolgono più variabili.
Questo tutorial spiega come calcolare la distanza Mahalanobis in SPSS.
Esempio: Distanza Mahalanobis in SPSS
Supponiamo di avere il seguente set di dati che mostra i punteggi degli esami di 20 studenti insieme al numero di ore trascorse a studiare, il numero di esami pratici che hanno sostenuto e il voto attuale nel corso:
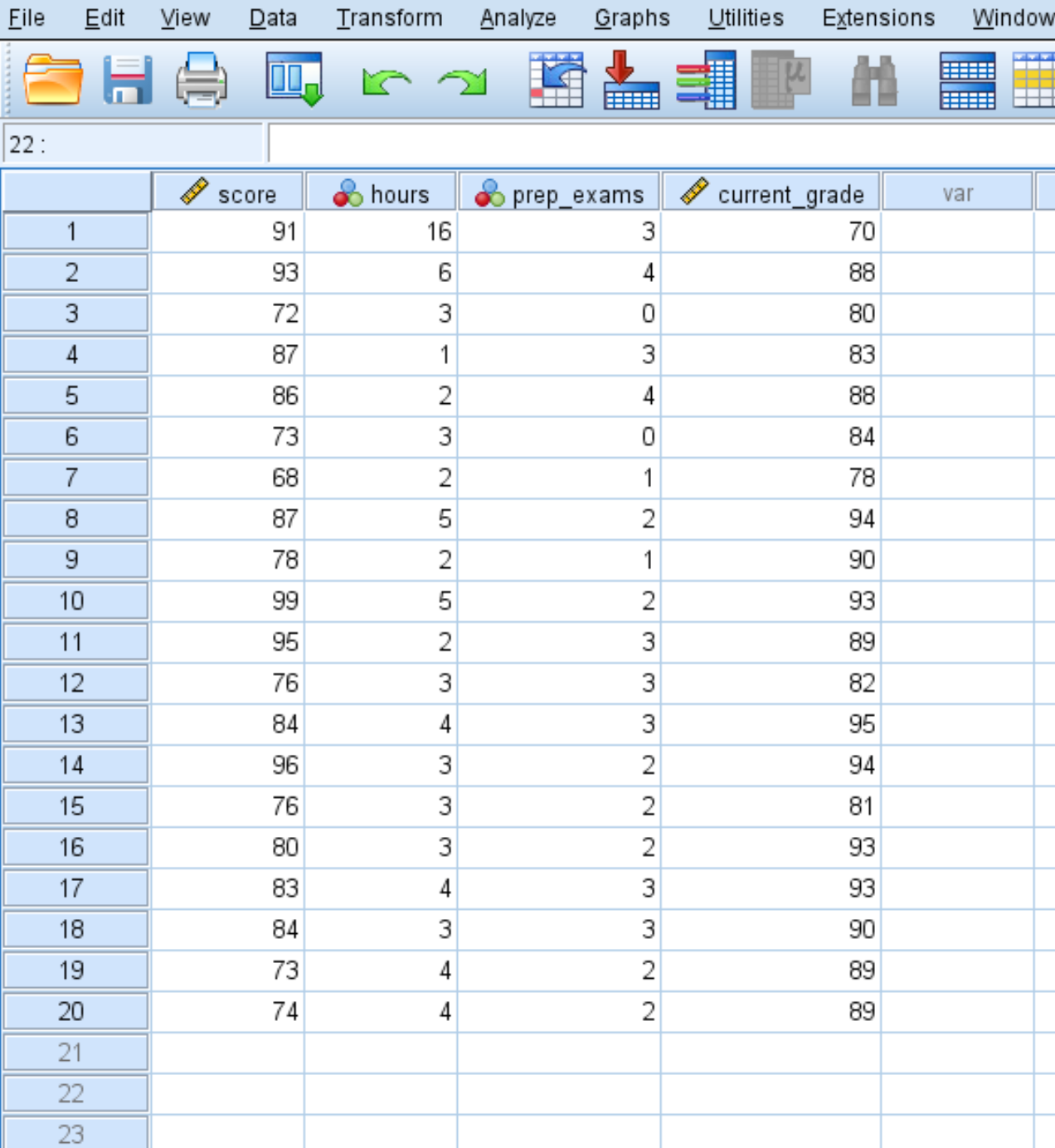
Possiamo utilizzare i seguenti passaggi per calcolare la distanza di Mahalanobis per ciascuna osservazione nel set di dati per determinare se sono presenti valori anomali multivariati.
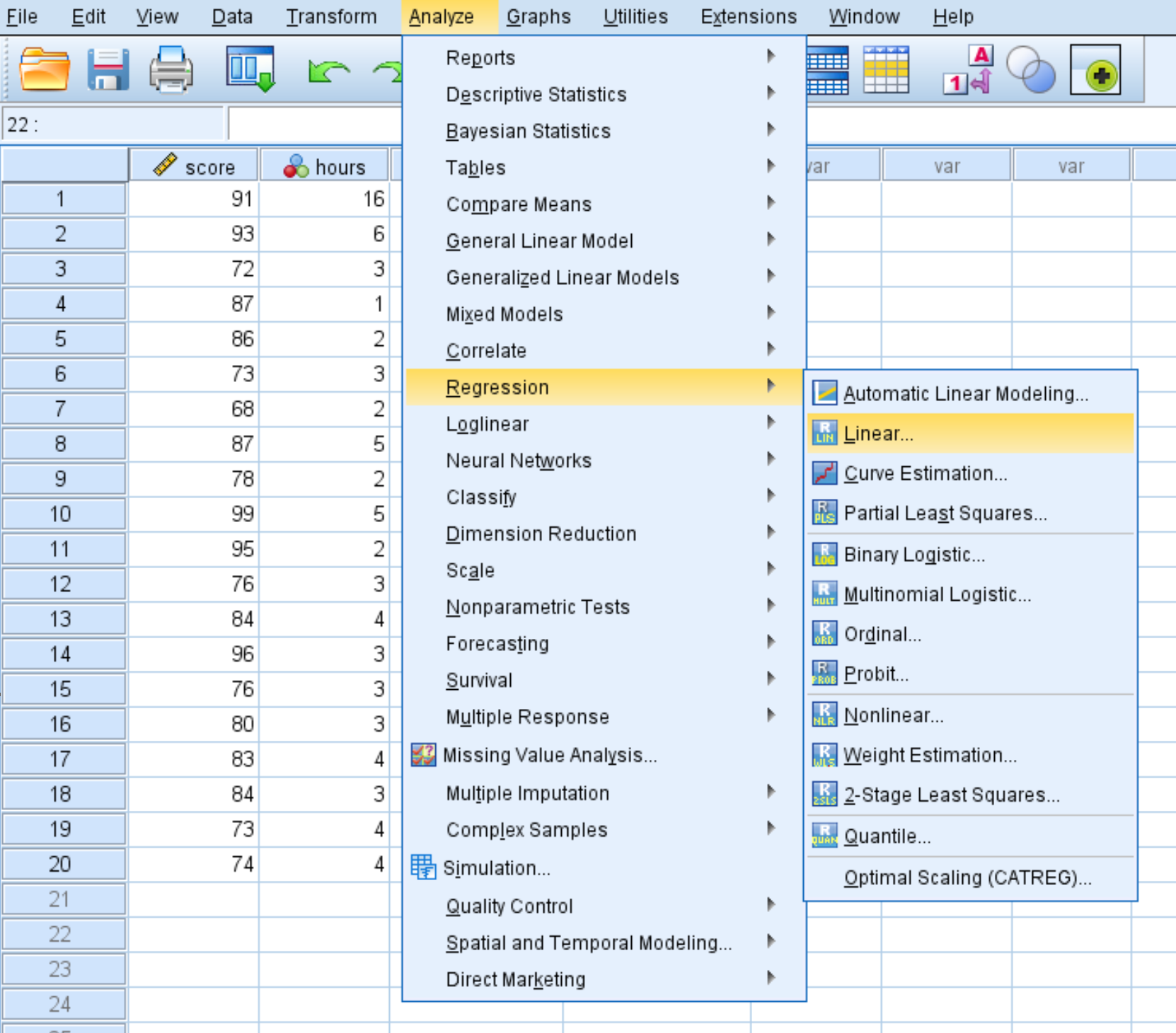
Passaggio 1: seleziona l’opzione Regressione lineare.
Fare clic sulla scheda Analizza , quindi su Regressione e infine su Lineare :
Passaggio 2: seleziona l’opzione Mahalanobis.
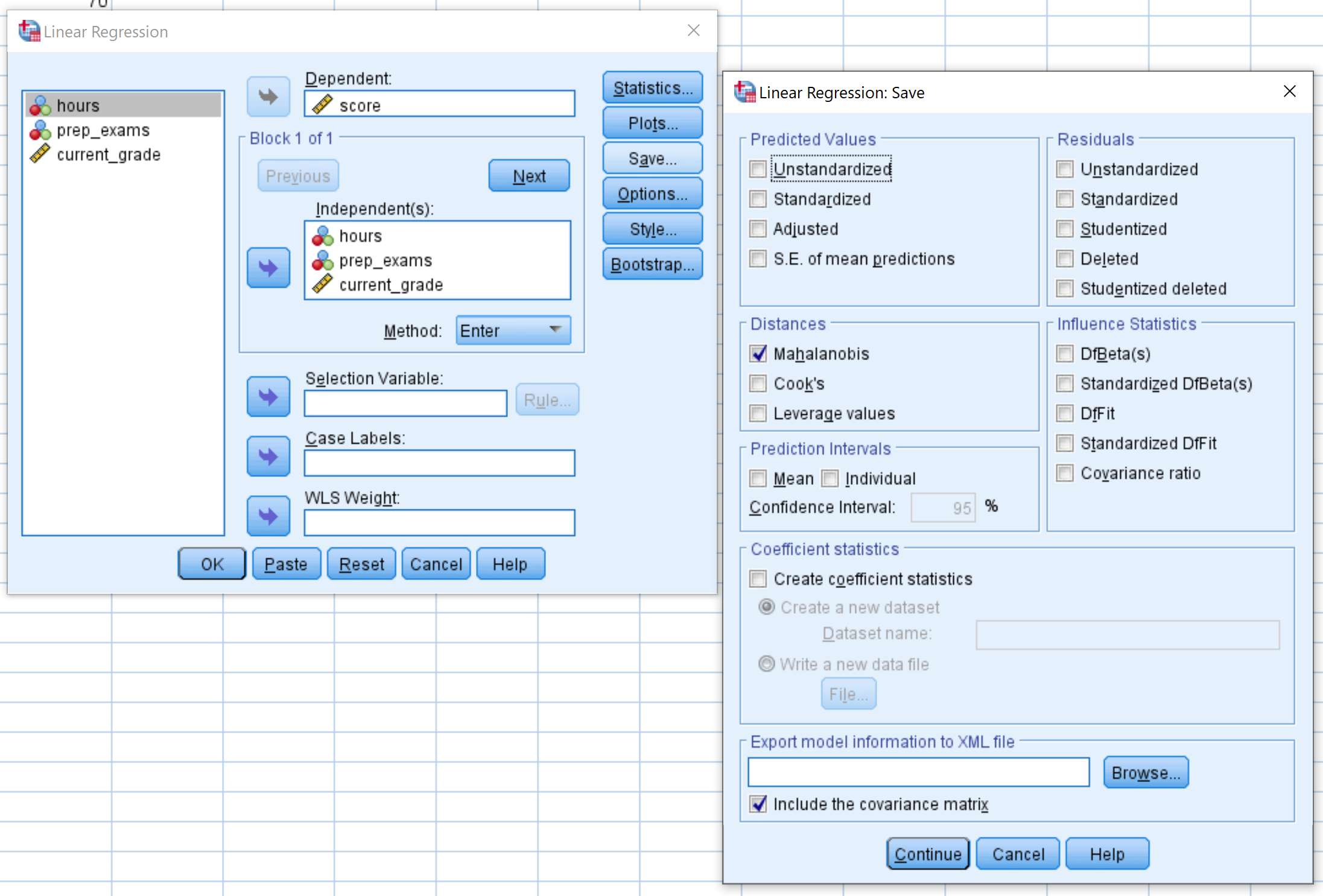
Trascina il punteggio della variabile di risposta nella casella denominata Dipendente. Trascina le altre tre variabili predittive nella casella denominata Indipendente/i. Quindi fare clic sul pulsante Salva . Nella nuova finestra che appare, assicurati che la casella accanto a Mahalanobis sia selezionata. Quindi fare clic su Continua . Quindi fare clic su OK .
Dopo aver fatto clic su OK , la distanza Mahalanobis per ciascuna osservazione nel set di dati verrà visualizzata in una nuova colonna intitolata MAH_1 :
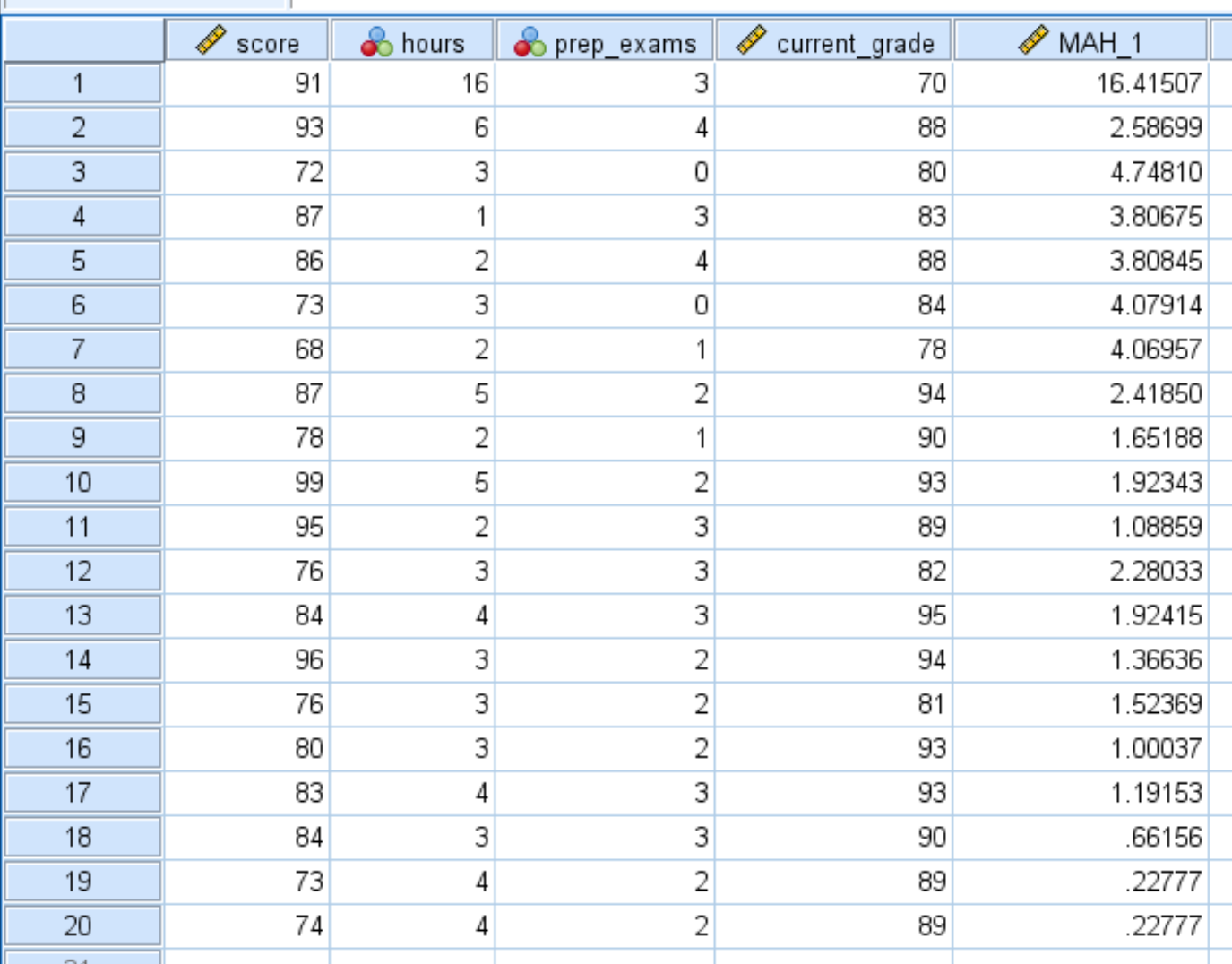
Possiamo vedere che alcune distanze sono molto maggiori di altre. Per determinare se qualcuna delle distanze è statisticamente significativa, dobbiamo calcolare i loro valori p.
Passaggio 3: calcolare i valori p di ciascuna distanza Mahalanobis.
Fare clic sulla scheda Trasformazione , quindi su Calcola variabile .
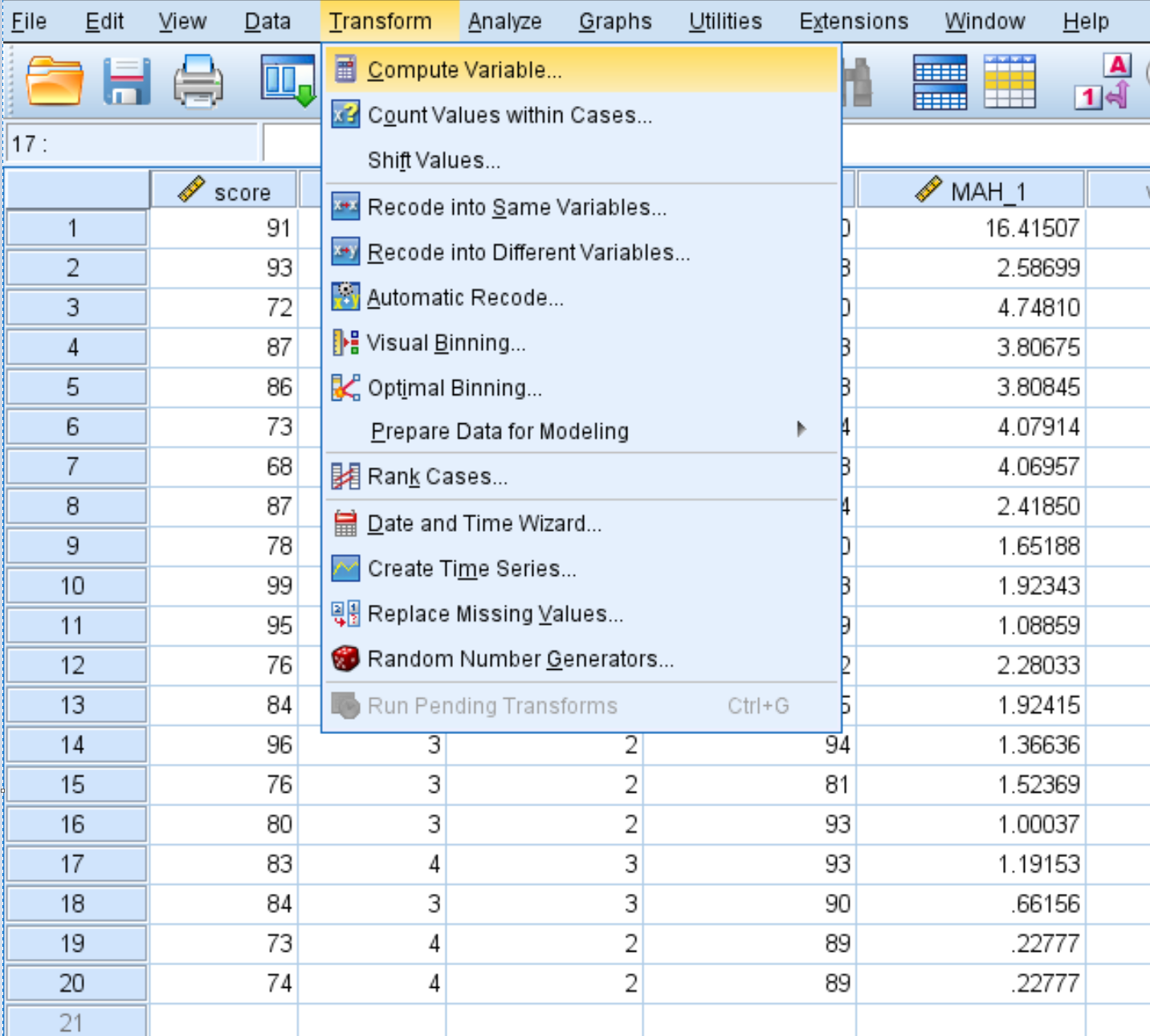
Nella casella Variabile di destinazione , scegli un nuovo nome per la variabile che stai creando. Per noi è “pvalue”. Nella casella Espressione numerica , inserisci quanto segue:
1 – CDF.CHISQ(MAH_1, 3)
Quindi fare clic su OK .
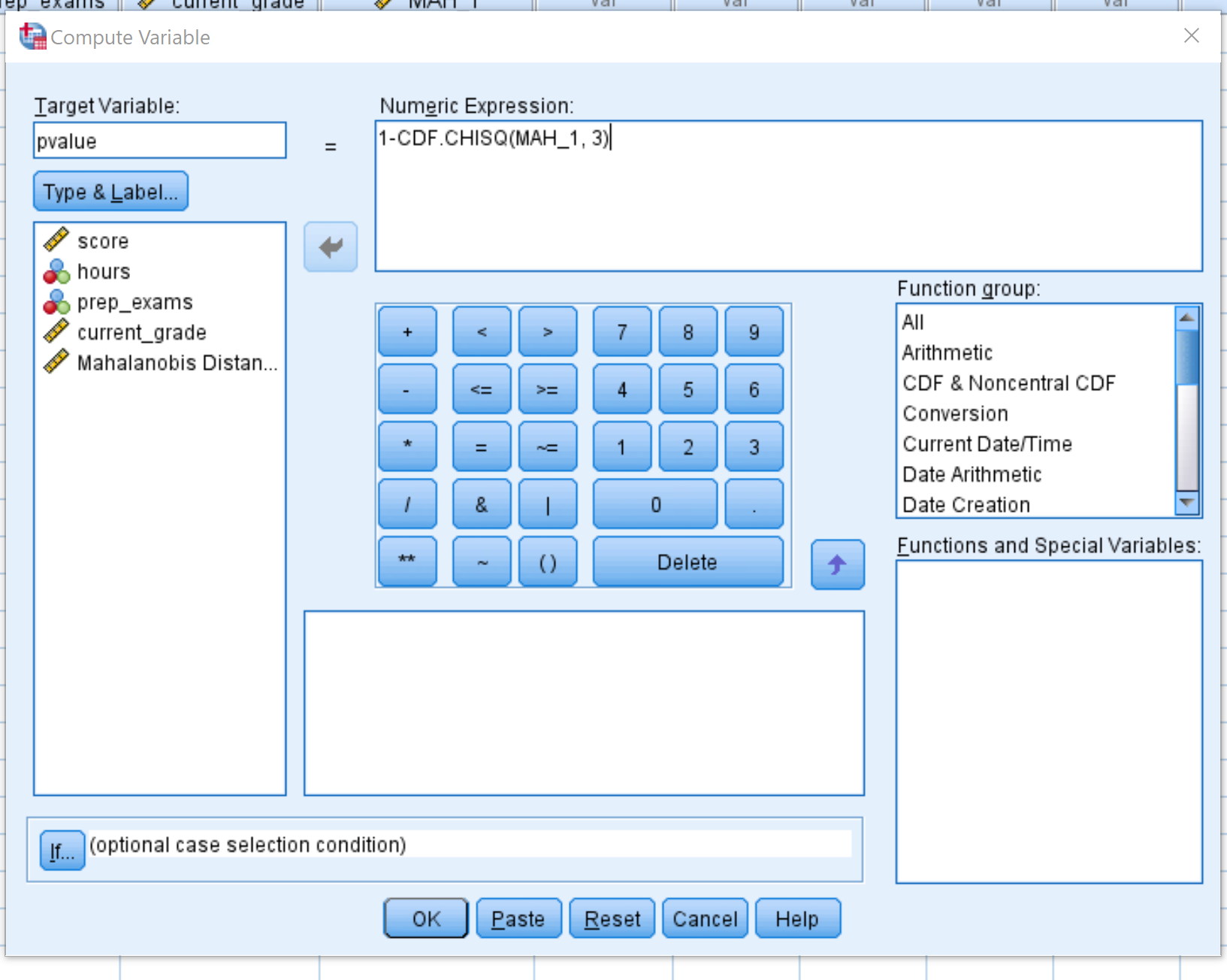
Ciò produrrà un valore p che corrisponde al valore Chi-quadrato con 3 gradi di libertà. Usiamo 3 gradi di libertà perché ci sono 3 variabili predittive nel nostro modello di regressione.
Passaggio 4: interpretare i valori p.
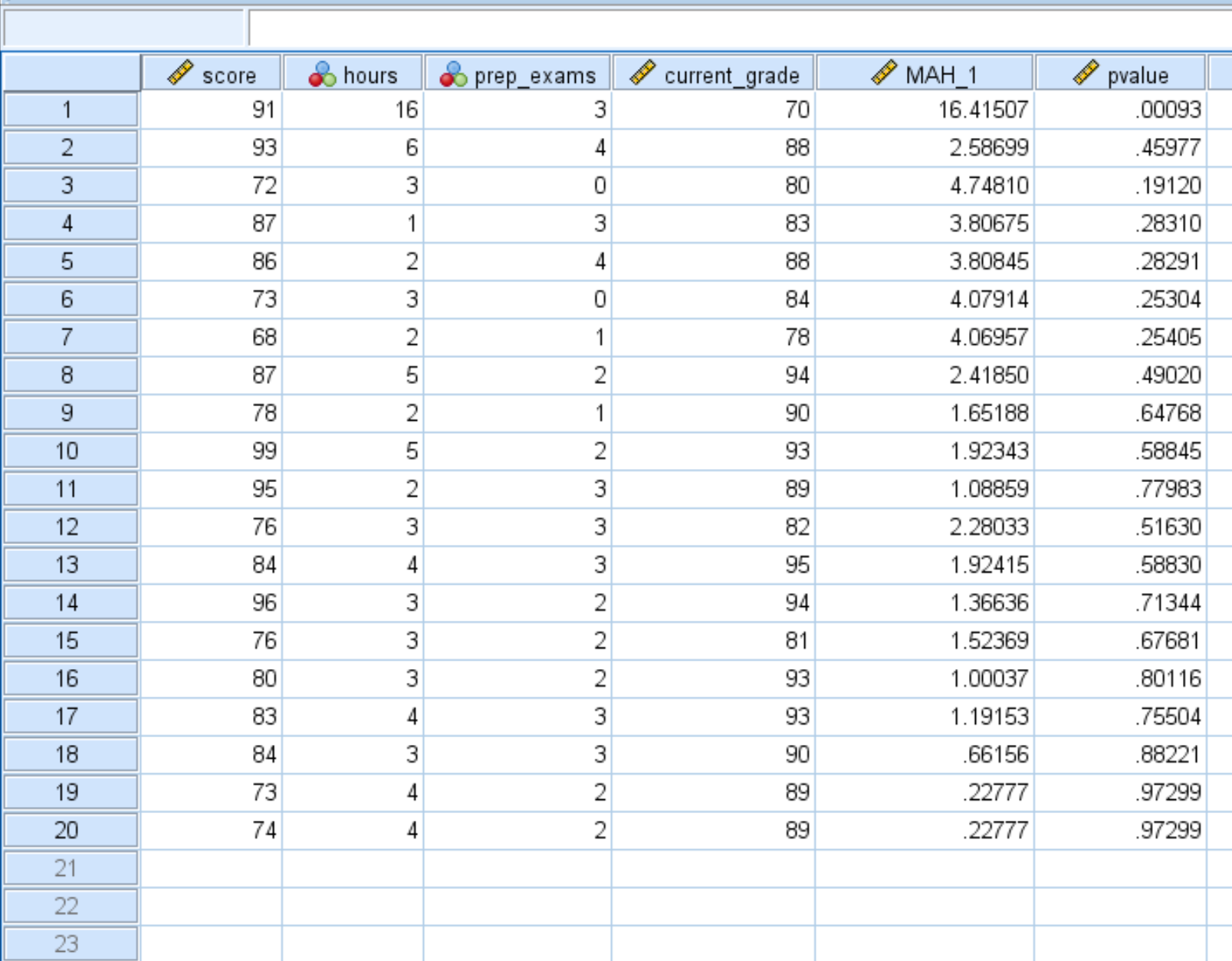
Dopo aver fatto clic su OK , il valore p per ciascuna distanza Mahalanobis verrà visualizzato in una nuova colonna:
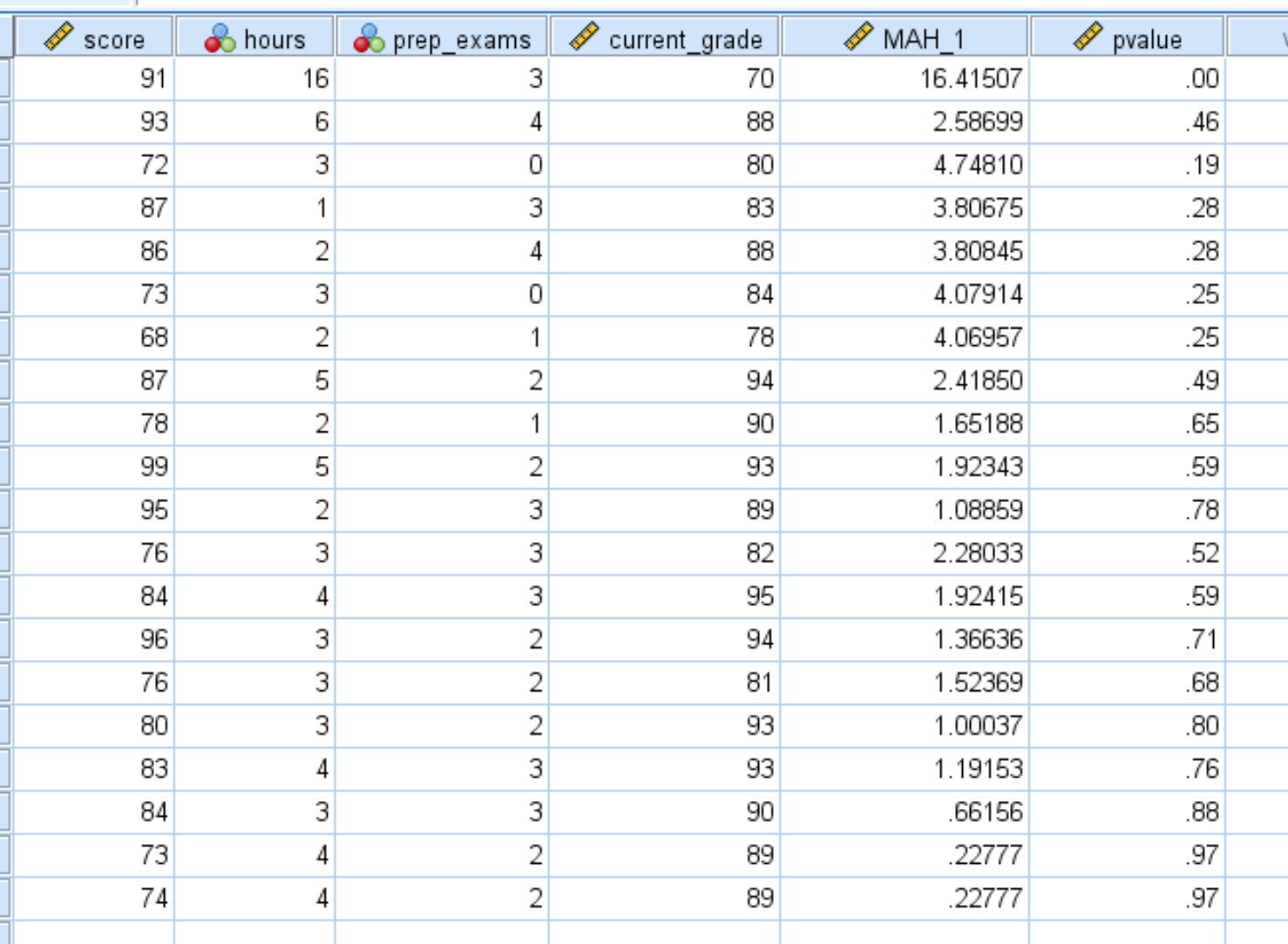
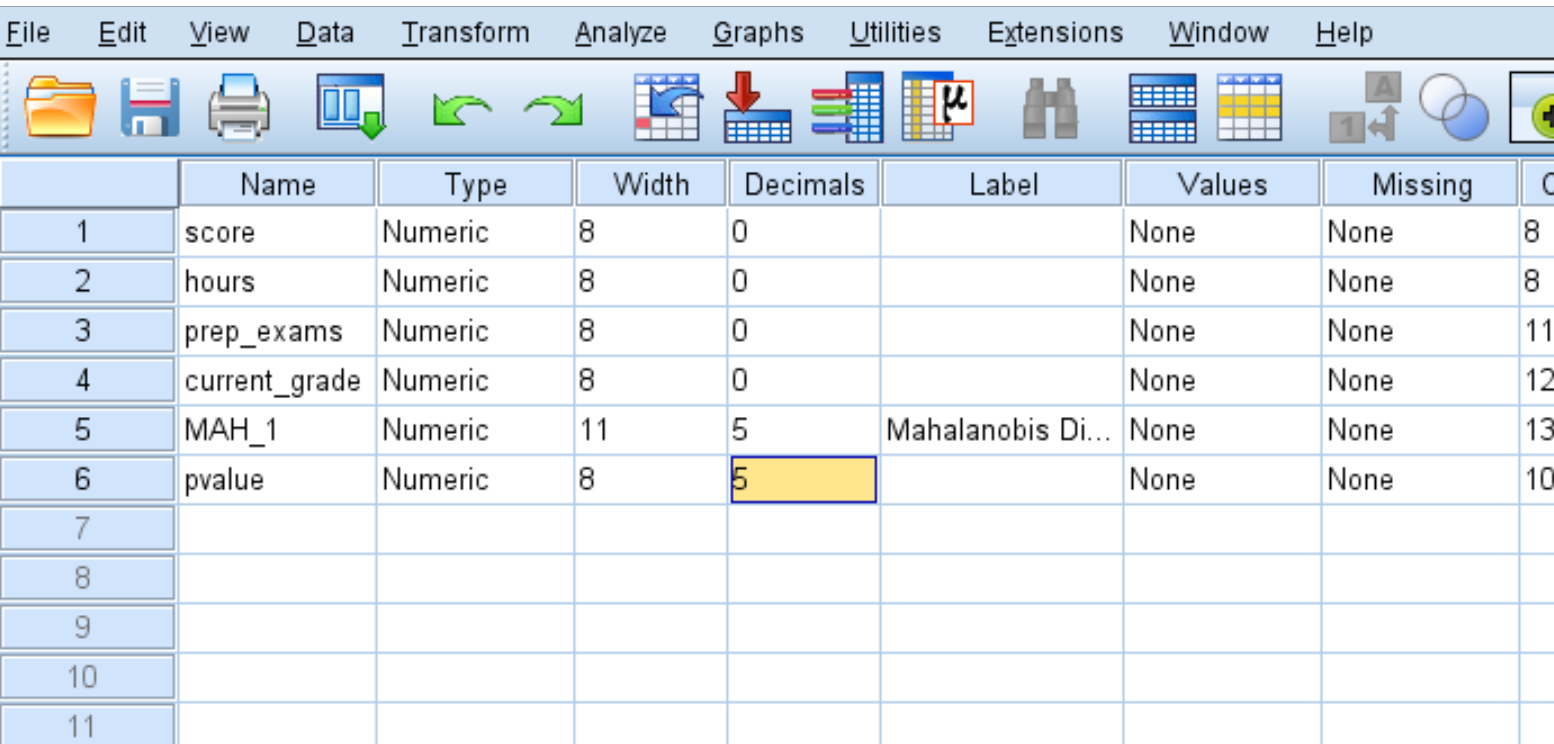
Per impostazione predefinita, SPSS visualizza solo i valori p con due cifre decimali. È possibile aumentare il numero di posizioni decimali facendo clic su Visualizza variabili nella parte inferiore di SPSS e aumentando il numero nella colonna Posizioni decimali :
Una volta tornato alla visualizzazione Dati , puoi vedere ciascun valore p visualizzato con cinque cifre decimali. Qualsiasi valore p inferiore a 0,001 è considerato un valore anomalo.
Possiamo vedere che la prima osservazione è l’unico valore anomalo nel set di dati perché ha un valore p inferiore a 0,001:
Come gestire i valori anomali
Se nei tuoi dati è presente un valore anomalo, hai diverse opzioni:
1. Assicurarsi che il valore anomalo non sia il risultato di un errore di immissione dei dati.
A volte un individuo inserisce semplicemente il valore dei dati errato durante il salvataggio dei dati. Se è presente un valore anomalo, verificare innanzitutto che il valore dei dati sia stato immesso correttamente e che non si tratti di un errore.
2. Rimuovere il valore anomalo.
Se il valore è davvero un valore anomalo, puoi scegliere di rimuoverlo se avrà un impatto significativo sull’analisi complessiva. Assicurati solo di menzionare nel rapporto finale o nell’analisi che hai rimosso un valore anomalo.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più