Come eseguire una manova in stata
Un’ANOVA unidirezionale viene utilizzata per determinare se diversi livelli di una variabile esplicativa portano o meno a risultati statisticamente diversi in determinate variabili di risposta.
Ad esempio, potremmo essere interessati a capire se tre livelli di istruzione (laurea, laurea triennale, laurea magistrale) portano o meno a guadagni annuali statisticamente diversi. In questo caso abbiamo una variabile esplicativa e una variabile di risposta.
- Variabile esplicativa: livello di istruzione
- Variabile di risposta: reddito annuo
Una MANOVA è un’estensione dell’ANOVA unidirezionale in cui è presente più di una variabile di risposta. Ad esempio, potremmo essere interessati a capire se il livello di istruzione porta o meno a diversi redditi annuali e a diversi importi del debito studentesco. In questo caso, abbiamo una variabile esplicativa e due variabili di risposta:
- Variabile esplicativa: livello di istruzione
- Variabili di risposta: reddito annuo, debito studentesco
Poiché abbiamo più di una variabile di risposta, in questo caso sarebbe opportuno utilizzare una MANOVA.
Successivamente spiegheremo come eseguire una MANOVA in Stata.
Esempio: MANOVA in Stata
Per illustrare come eseguire una MANOVA in Stata, utilizzeremo il seguente set di dati che contiene le seguenti tre variabili per 24 persone:
- educ: livello di studio (0 = Associate, 1 = Bachelor, 2 = Master)
- reddito: reddito annuo
- debito: debito totale del prestito studentesco
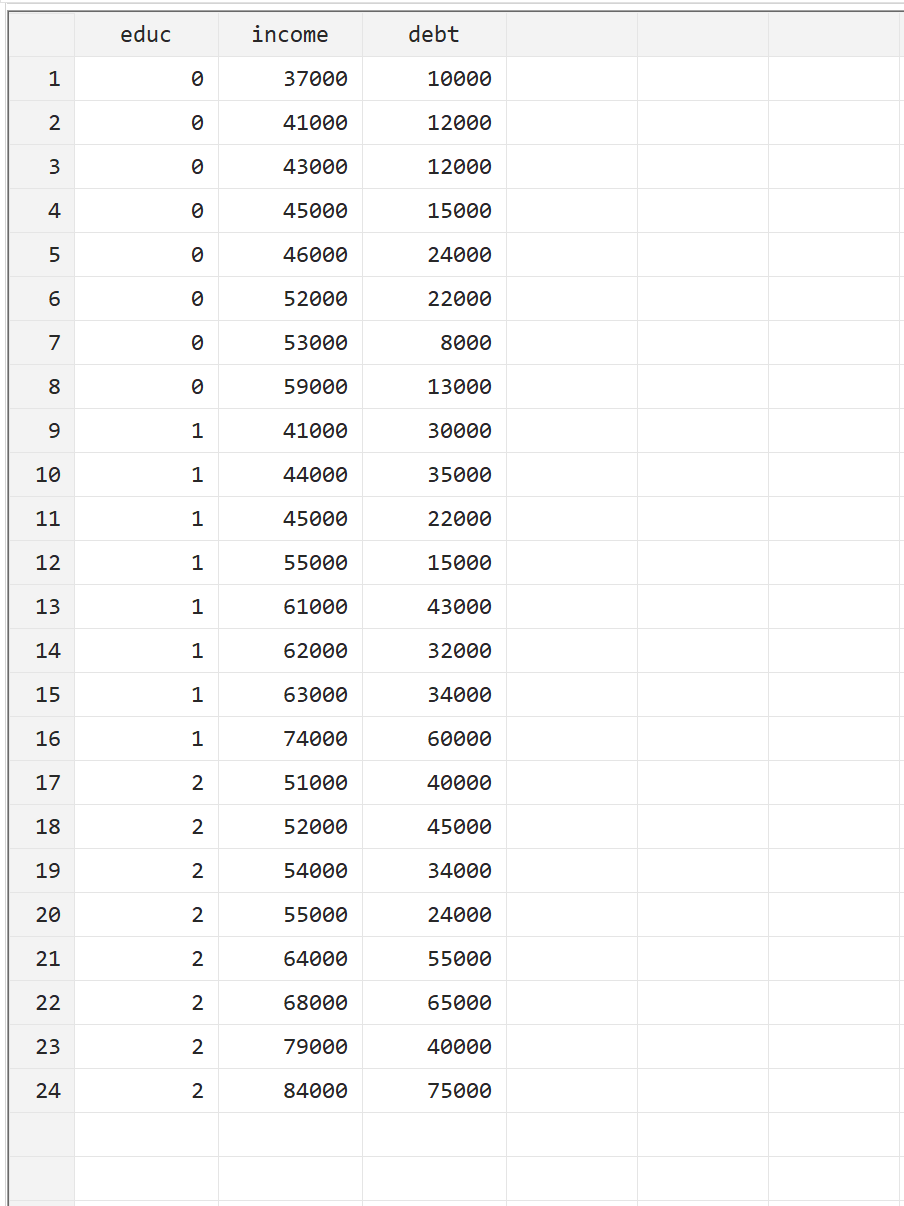
Puoi riprodurre questo esempio inserendo manualmente i dati accedendo a Dati > Editor dati > Editor dati (Modifica) nella barra dei menu in alto.
Per eseguire la MANOVA utilizzando l’istruzione come variabile esplicativa e reddito e debito come variabili di risposta, possiamo utilizzare il seguente comando:
reddito debito manova = educ

Stata produce quattro statistiche di test uniche insieme ai corrispondenti valori p:
Lambda di Wilks: statistica F = 5,02, valore P = 0,0023.
Traccia Pillai: statistica F = 4,07, valore P = 0,0071.
Traccia Lawley-Hotelling: statistica F = 5,94, valore P = 0,0008.
Radice di Roy più grande: statistica F = 13,10, valore P = 0,0002.
Per una spiegazione dettagliata di come viene calcolata ciascuna statistica del test, fare riferimento a questo articolo del Penn State Eberly College of Science.
Il valore p per ciascuna statistica del test è inferiore a 0,05, quindi l’ipotesi nulla verrà rifiutata indipendentemente da quale si utilizza. Ciò significa che abbiamo prove sufficienti per affermare che il livello di istruzione causa differenze statisticamente significative nel reddito annuale e nel debito studentesco totale.
Nota sui valori p: la lettera accanto al valore p nella tabella di output indica come è stata calcolata la statistica F (e = calcolo esatto, a = calcolo approssimativo, u = limite superiore).
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più