Matplotlib: come colorare un grafico a dispersione in base al valore
Spesso potresti voler ombreggiare il colore dei punti in un grafico a dispersione matplotlib basato su una terza variabile. Fortunatamente, questo è facile da fare utilizzando la funzione matplotlib.pyplot.scatter() , che accetta la seguente sintassi:
matplotlib.pyplot.scatter(x, y, s=Nessuno, c=Nessuno, cmap=Nessuno)
Oro:
- x: Tabella dei valori da utilizzare per le posizioni dell’asse x nel grafico.
- y: array di valori da utilizzare per le posizioni dell’asse y nel grafico.
- s: la dimensione del marcatore.
- c: Tabella dei valori da utilizzare per i colori dei marcatori.
- cmap: una mappa di colori da utilizzare nella stampa.
Puoi usare c per specificare una variabile da usare per i valori di colore e puoi usare cmap per specificare i colori effettivi da usare per i marcatori nella nuvola di punti.
Questo tutorial spiega diversi esempi di utilizzo pratico di questa funzione.
Esempio 1: punti del grafico a dispersione colorati per valore
Supponiamo di avere i seguenti panda DataFrame:
import pandas as pd #createDataFrame df = pd.DataFrame({'x': [25, 12, 15, 14, 19, 23, 25, 29], 'y': [5, 7, 7, 9, 12, 9, 9, 4], 'z': [3, 4, 4, 5, 7, 8, 8, 9]}) #view DataFrame df X Y Z 0 25 5 3 1 12 7 4 2 15 7 4 3 14 9 5 4 19 12 7 5 23 9 8 6 25 9 8 7 29 4 9
Il codice seguente mostra come creare una nuvola di punti utilizzando una tavolozza di colori grigi e utilizzando i valori della variabile z come sfumatura della tavolozza di colori:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (df.x, df.y, s=200, c=df.z, cmap=' gray ')
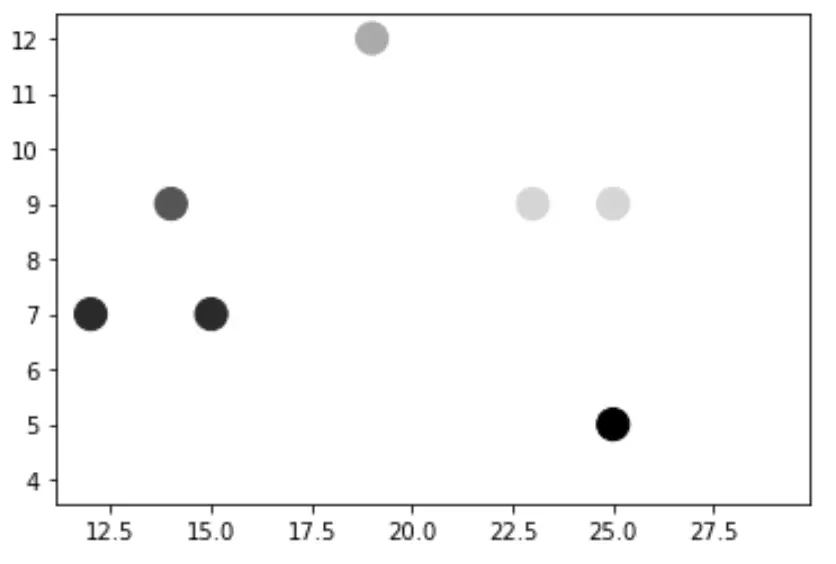
Per questo esempio particolare, scegliamo la tavolozza dei colori “grigio”, ma puoi trovare un elenco completo delle tavolozze dei colori disponibili da utilizzare nella documentazione delle tavolozze dei colori matplotlib .
Ad esempio, potremmo invece specificare “Verdi” come tavolozza dei colori:
plt. scatter (df.x, df.y, s=200, c=df.z, cmap=' Greens ')
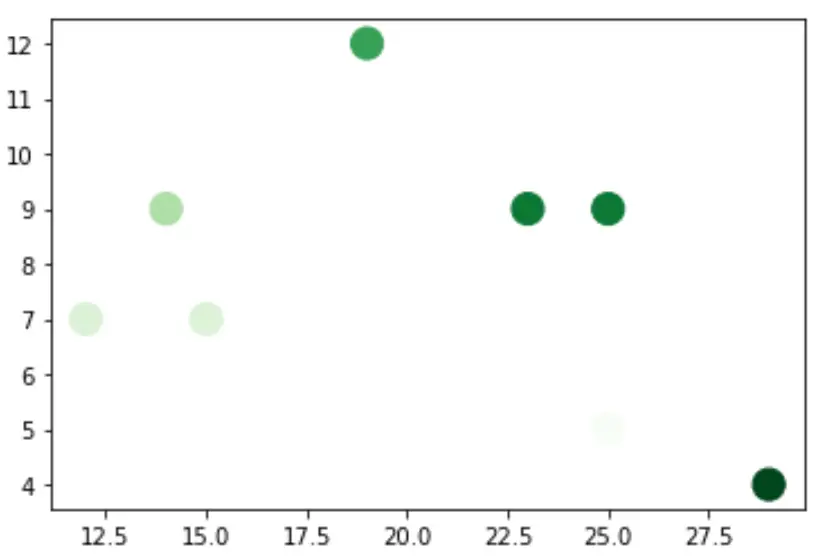
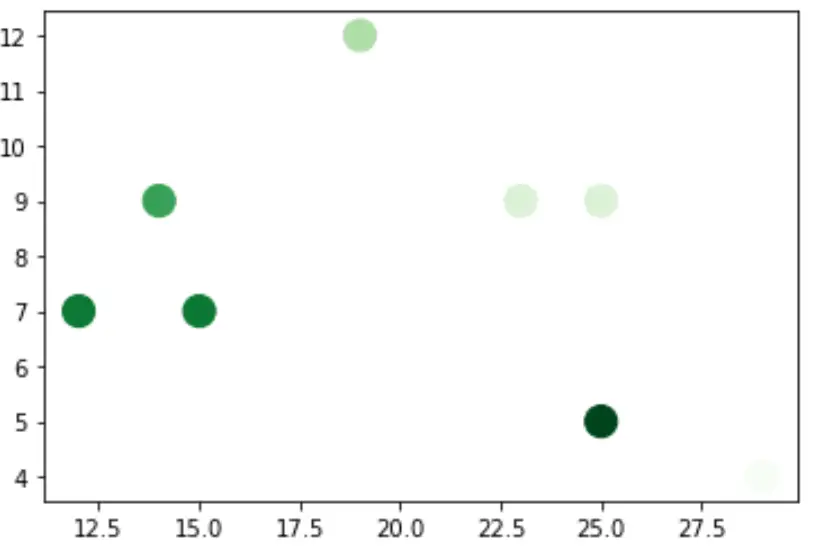
Per impostazione predefinita, i marcatori con valori più grandi per l’argomento c sono ombreggiati più scuri, ma puoi invertire questa tendenza semplicemente aggiungendo _r al nome cmap:
plt. scatter (df.x, df.y, s=200, c=df.z, cmap=' Greens_r ')
Esempio 2: punti colorati del grafico a dispersione per categoria
Supponiamo di avere i seguenti panda DataFrame:
import pandas as pd #createDataFrame df = pd.DataFrame({'x': [25, 12, 15, 14, 19, 23, 25, 29], 'y': [5, 7, 7, 9, 12, 9, 9, 4], 'z': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C']}) #view DataFrame df X Y Z 0 25 5 A 1 12 7 A 2 15 7 B 3 14 9 B 4 19 12 B 5 23 9 C 6 25 9 C 7 29 4 C
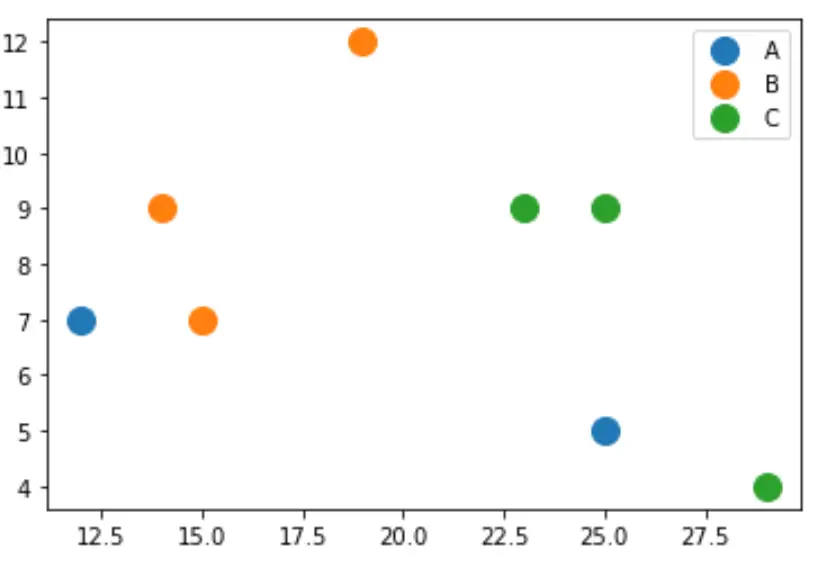
Il codice seguente mostra come creare un grafico a dispersione utilizzando la variabile z per colorare i marcatori in base alla categoria:
import matplotlib.pyplot as plt groups = df. groupby ('z') for name, group in groups: plt. plot (group.x, group.y, marker=' o ', linestyle='', markersize=12, label=name) plt. legend ()
Puoi trovare altri tutorial su Python qui .
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più