Sas: come utilizzare (in=a) nell'istruzione merge
Quando si uniscono due set di dati in SAS, è possibile utilizzare l’istruzione IN per restituire solo le righe in cui esiste un valore in un particolare set di dati.
Ecco alcuni modi comuni per utilizzare nella pratica l’istruzione IN :
Metodo 1: restituisce le righe in cui esiste un valore nel primo set di dati (in=a)
data final_data;
merge data1 (in=a) data2;
byID ;
if a;
run ;
Questo particolare esempio unisce i set di dati chiamati data1 e data2 e restituisce solo le righe in cui esiste un valore in data1 .
Metodo 2: restituisce le righe in cui esiste un valore nel secondo set di dati (in=b)
data final_data;
merge data1 data2 (in=b);
byID ;
if b;
run ;
Questo particolare esempio unisce i set di dati chiamati data1 e data2 e restituisce solo le righe per le quali esiste un valore in data2 .
Metodo 3: restituisce le righe in cui il valore esiste in entrambi i set di dati (in=a) e (in=b)
data final_data;
merge data1(in=a) data2(in=b);
byID ;
if a and b;
run ;
Questo particolare esempio unisce i set di dati chiamati data1 e data2 e restituisce solo le righe in cui esiste un valore sia in data1 che in data2 .
Gli esempi seguenti mostrano come utilizzare ciascun metodo nella pratica con i due set di dati seguenti:
/*create first dataset*/
data data1;
inputIDGender $;
datalines ;
1 Male
2 Male
3 Female
4 Male
5 Female
;
run ;
title "data1";
proc print data = data1;
/*create second dataset*/
data data2;
input IDSales;
datalines ;
1 22
2 15
4 29
6 31
7 20
8 13
;
run ;
title "data2";
proc print data = data2;
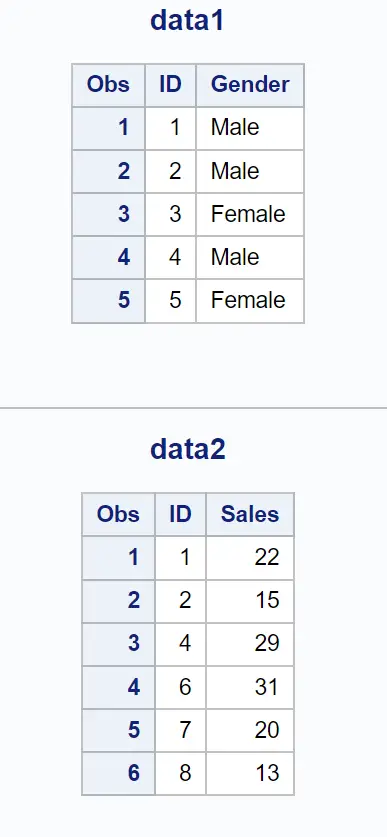
Esempio 1: restituisce tutte le righe
Possiamo utilizzare la seguente istruzione di unione senza alcuna istruzione IN per unire i due set di dati in base al valore della colonna ID e restituire tutte le righe da entrambi i set di dati:
/*perform merge*/
data final_data;
merge data1 data2;
byID ;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
Tieni presente che vengono restituite tutte le righe in entrambi i set di dati, anche se mancano dei valori a causa di un valore ID non esistente in entrambi i set di dati.
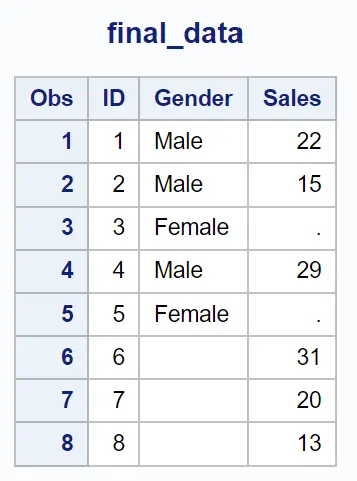
Esempio 2: restituisce le righe in cui esiste valore nel primo set di dati (in = a)
Possiamo utilizzare la seguente istruzione merge con (in=a) per unire i due set di dati in base al valore nella colonna ID e restituire solo le righe in cui esiste un valore nel primo set di dati:
/*perform merge*/
data final_data;
merge data1 (in = a) data2;
byID ;
if a;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
Tieni presente che vengono restituite solo le righe per le quali esiste un valore nel primo set di dati.
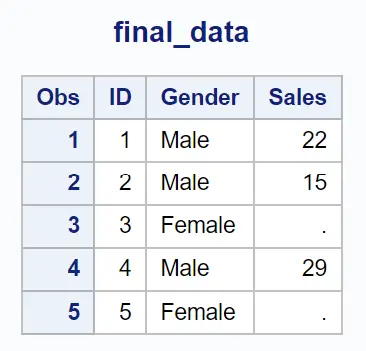
Esempio 3: restituisce le righe in cui esiste valore nel secondo set di dati (in=b)
Possiamo utilizzare la seguente istruzione merge con (in=b) per unire i due set di dati in base al valore nella colonna ID e restituire solo le righe in cui esiste un valore nel secondo set di dati:
/*perform merge*/
data final_data;
merge data1 data2(in=b);
byID ;
if b;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
Tieni presente che vengono restituite solo le righe per le quali esiste un valore nel secondo set di dati.
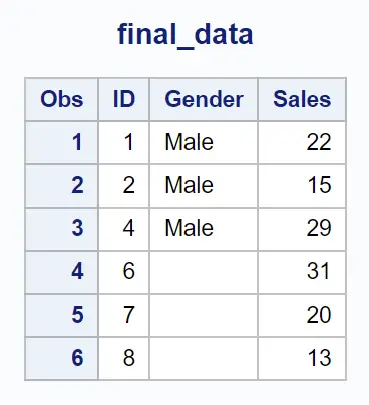
Esempio 4: restituisce le righe in cui il valore esiste in entrambi i set di dati (in = a) e (in = b)
Possiamo utilizzare la seguente istruzione di unione con (in=a) e (in=b) per unire i due set di dati in base al valore nella colonna ID e restituire solo le righe in cui esiste un valore in entrambi i set di dati:
/*perform merge*/
data final_data;
merge data1(in=a) data2(in=b);
byID ;
if a and b;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
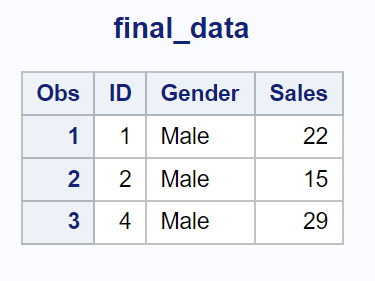
Tieni presente che vengono restituite solo le righe per le quali esiste un valore in entrambi i set di dati.
Nota : è possibile trovare la documentazione completa per l’istruzione di unione SAS qui .
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in SAS:
Come eseguire un join sinistro in SAS
Come eseguire un inner join in SAS
Come eseguire un join esterno in SAS
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più