Qual è un'osservazione influente nelle statistiche?
In statistica, un’osservazione influente è un’osservazione in un set di dati che, una volta rimossa, modifica in modo significativo le stime dei coefficienti di un modello di regressione.
Il modo più comune per misurare l’influenza delle osservazioni è utilizzare la distanza di Cook , che quantifica quanto cambiano tutti i valori adattati in un modello di regressione quando viene rimossa l’i- esima osservazione.
Generalmente, qualsiasi osservazione con una distanza Cook maggiore di 1 è considerata un’osservazione ad alta leva.
L’esempio seguente mostra come calcolare e interpretare la distanza di Cook per un dato set di dati per rilevare potenziali osservazioni influenti.
Esempio: rilevamento di osservazioni influenti
Supponiamo di avere il seguente set di dati con 14 valori:
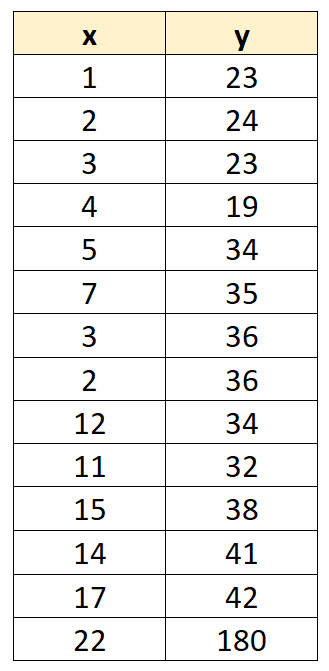
Supponiamo ora di adattare un semplice modello di regressione lineare . Il risultato della regressione è presentato di seguito:

Utilizzando un software statistico, possiamo calcolare i seguenti valori della distanza di Cook per ciascuna osservazione:
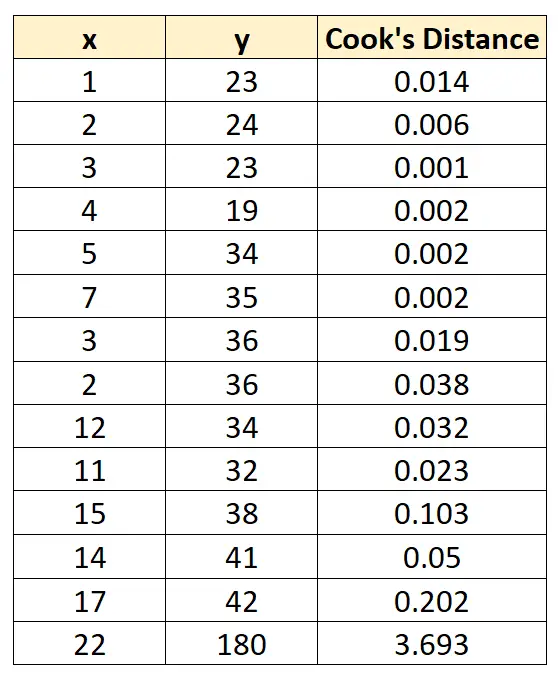
Si noti che l’ultima osservazione ha un valore significativamente maggiore di 1 per la distanza di Cook, il che ci dice che si tratta di un’osservazione influente.
Supponiamo di rimuovere questo valore dal set di dati e di adattare un nuovo modello di regressione lineare semplice. L’output di questo modello è mostrato di seguito:

Si noti che i coefficienti di regressione per l’intercetta e x sono entrambi cambiati radicalmente. Questo ci dice che la rimozione dell’osservazione influente dal set di dati ha cambiato completamente il modello di regressione adattato.
I seguenti grafici mostrano la differenza tra queste due equazioni di regressione adattate:
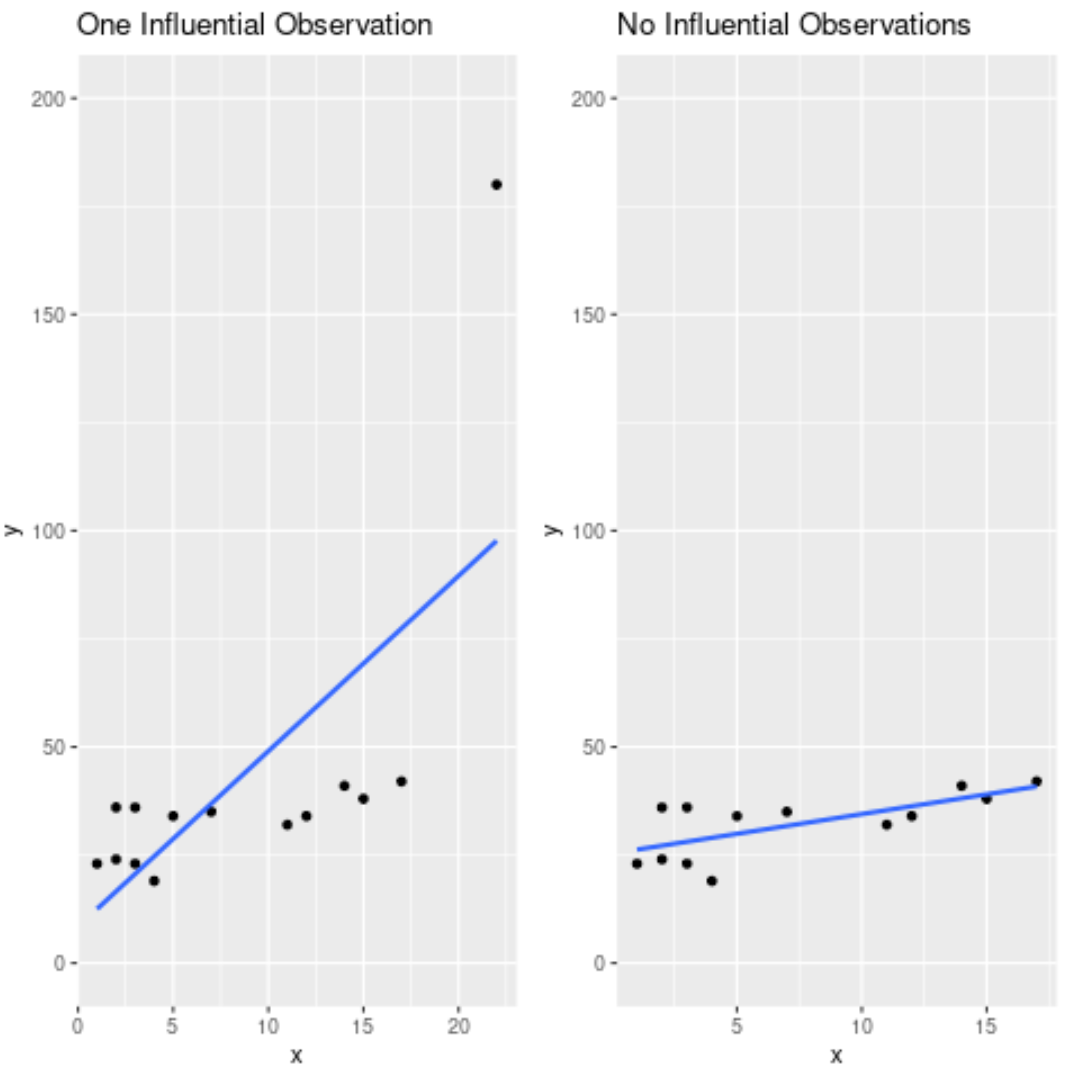
Nota quanto la singola osservazione influente cambia la retta di regressione. Eliminando questa osservazione, siamo riusciti a trovare una linea di regressione che si adattava molto più fedelmente ai dati.
Commenti
È importante notare che la distanza di Cook dovrebbe essere utilizzata per identificare osservazioni potenzialmente influenti. Tuttavia, solo perché un’osservazione è influente non significa necessariamente che debba essere rimossa dal set di dati.
Per prima cosa bisogna verificare che l’osservazione non sia il risultato di un errore di inserimento dati o di altro evento strano. Se risulta essere un valore legittimo, allora puoi decidere di trattarlo in uno dei seguenti modi:
- Rimuovilo dal set di dati.
- Lasciarlo nel set di dati.
- Sostituiscilo con un valore alternativo come la media o la mediana.
A seconda dello scenario specifico, una di queste opzioni potrebbe avere più senso delle altre.
Come calcolare in pratica la distanza del cuoco
I seguenti tutorial spiegano come calcolare la distanza di Cook per un dato set di dati in Python e R:
Come calcolare la distanza di Cook in Python
Come calcolare la distanza di Cook in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più