Panda: importa csv con un numero diverso di colonne per riga
È possibile utilizzare la seguente sintassi di base per importare un file CSV in panda quando è presente un numero diverso di colonne per riga:
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
Il valore all’interno della funzione range() dovrebbe essere il numero di colonne nella riga con il numero massimo di colonne.
L’esempio seguente mostra come utilizzare questa sintassi nella pratica.
Esempio: importa CSV in Panda con un numero diverso di colonne per riga
Supponiamo di avere il seguente file CSV chiamato uneven_data.csv :
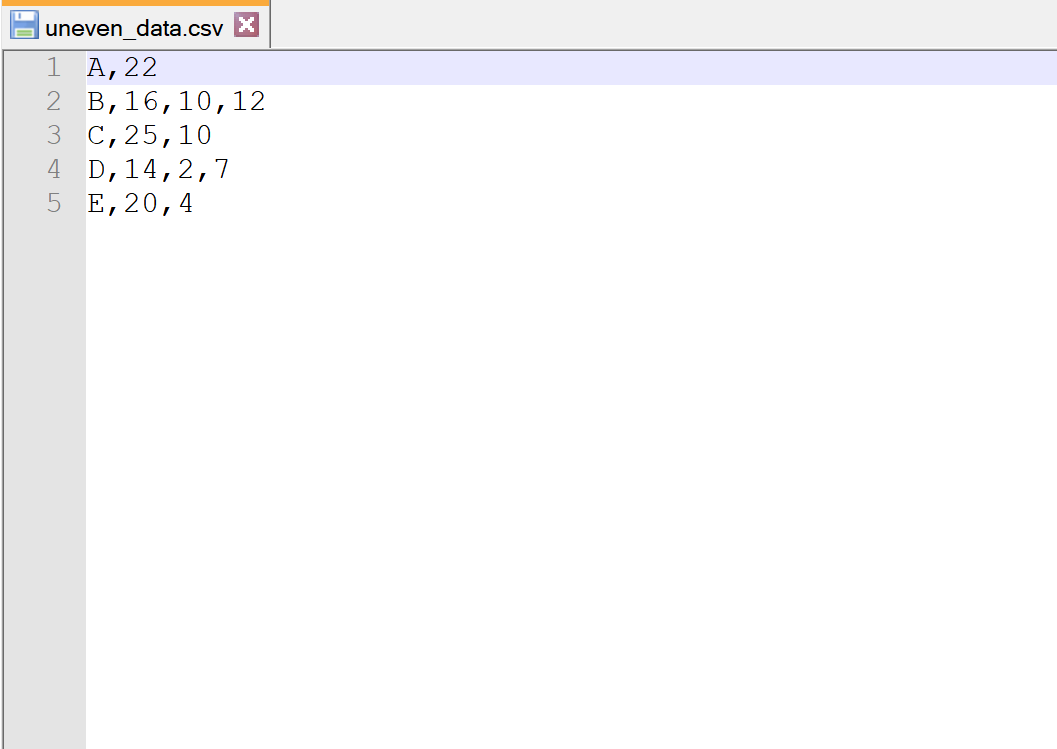
Tieni presente che ogni riga non ha lo stesso numero di colonne.
Se proviamo a utilizzare la funzione read_csv() per importare questo file CSV in un DataFrame panda, riceveremo un errore:
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
Riceviamo un ParserError che ci dice che pandas si aspettava 2 campi (poiché quello era il numero di colonne nella prima riga) ma ne ha visti 4 .
Questo errore ci dice che il numero massimo di colonne in una determinata riga è 4 .
Quindi, possiamo importare il file CSV e fornire un valore range(4) all’argomento dei nomi :
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
Tieni presente che siamo in grado di importare con successo il file CSV in un DataFrame panda senza errori poiché abbiamo detto esplicitamente ai panda di aspettarsi 4 colonne.
Per impostazione predefinita, Panda riempie tutti i valori mancanti in ciascuna riga con NaN.
Se vuoi che i valori mancanti appaiano come zero, puoi utilizzare la funzione fillna() come segue:
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
Ogni valore NaN nel DataFrame è stato ora sostituito con uno zero.
Nota : puoi trovare la documentazione completa della funzione panda read_csv() qui .
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in Python:
Panda: come saltare le righe durante la lettura di un file CSV
Panda: come aggiungere dati a un file CSV esistente
Panda: come specificare i tipi durante l’importazione di un file CSV
Panda: imposta i nomi delle colonne durante l’importazione di un file CSV
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più