Come tracciare la distribuzione dei valori delle colonne in pandas
È possibile utilizzare i seguenti metodi per tracciare una distribuzione dei valori delle colonne in un DataFrame panda:
Metodo 1: traccia la distribuzione dei valori in una colonna
df[' my_column ']. plot (kind=' kde ')
Metodo 2: traccia la distribuzione dei valori in una colonna, raggruppati in un’altra colonna
df. groupby (' group_column ')[' values_column ']. plot (kind=' kde ')
I seguenti esempi mostrano come utilizzare ciascun metodo nella pratica con i seguenti DataFrame panda:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], ' points ': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print (df) team points 0 to 3 1 to 3 2 to 4 3 to 5 4 to 4 5 TO 7 6 to 7 7 to 7 8 to 10 9 to 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
Esempio 1: traccia la distribuzione dei valori in una colonna
Il codice seguente mostra come tracciare la distribuzione dei valori nella colonna dei punti :
#plot distribution of values in points column df[' points ']. plot (kind=' kde ')
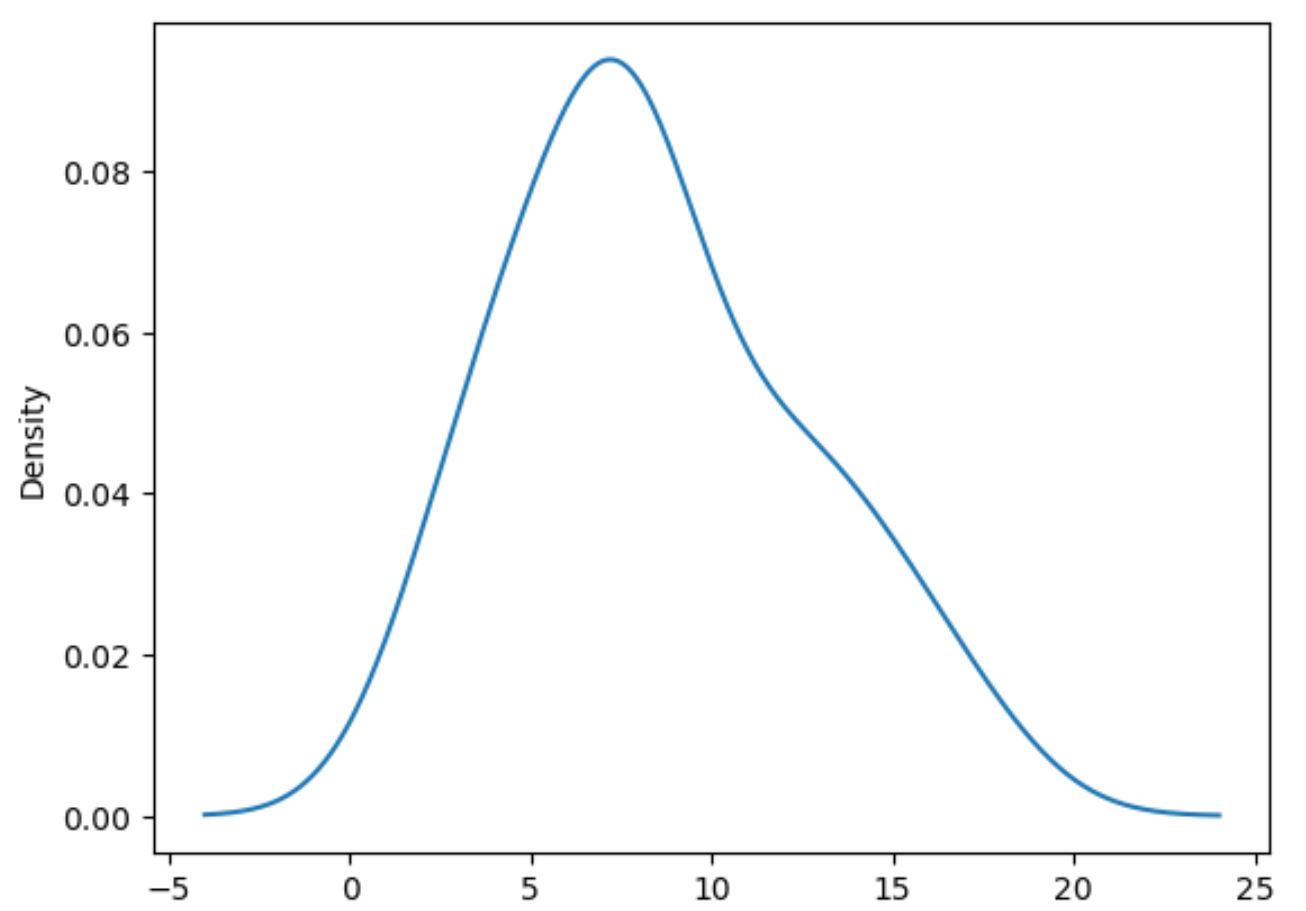
Tieni presente che kind=’kde’ dice ai panda di utilizzare la stima della densità del kernel , che produce una curva uniforme che riassume la distribuzione dei valori di una variabile.
Se invece vuoi creare un istogramma, puoi specificare kind=’hist’ come segue:
#plot distribution of values in points column using histogram df[' points ']. plot (kind=' hist ', edgecolor=' black ')
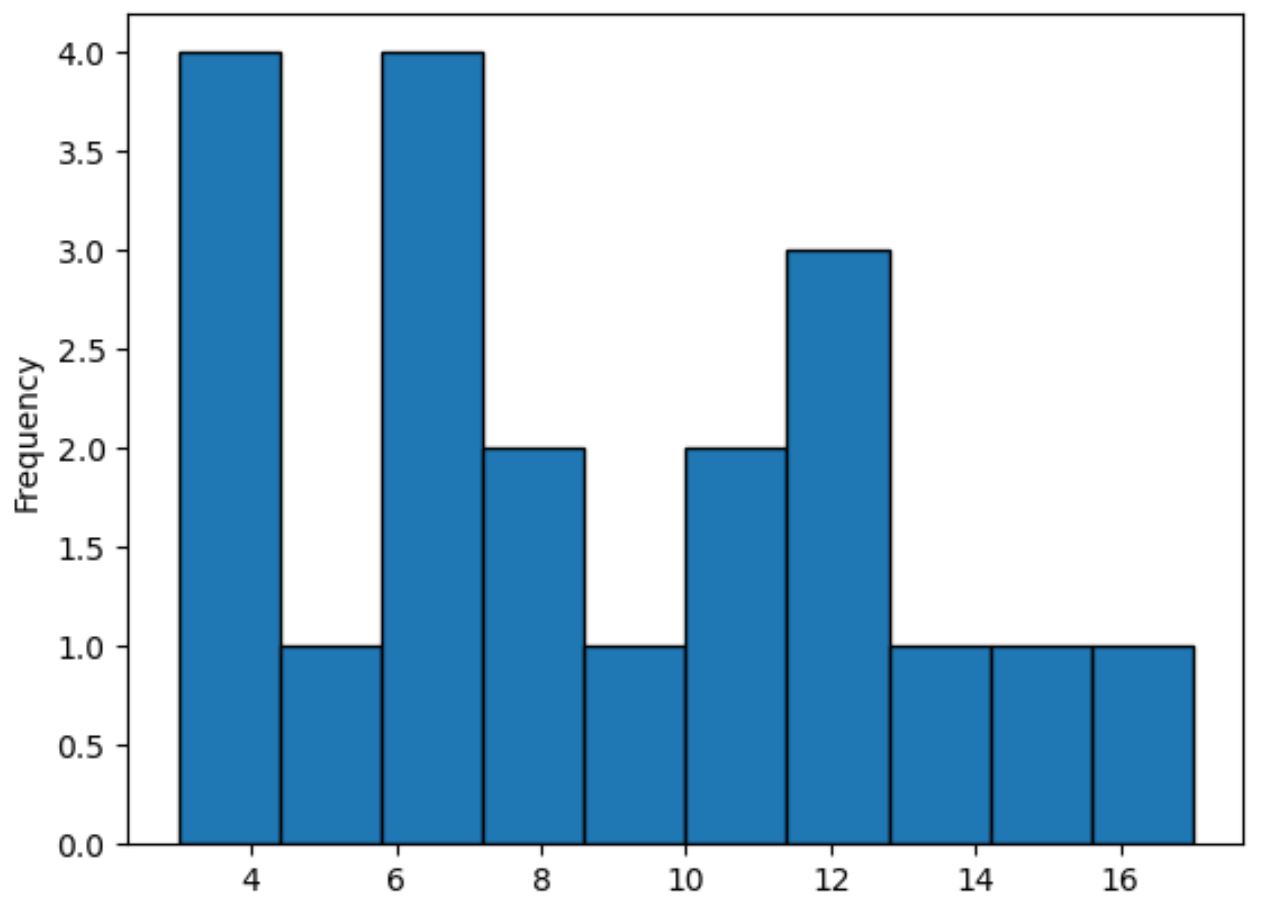
Questo metodo utilizza le barre per rappresentare le frequenze dei valori nella colonna di punti , al contrario di una linea liscia che riassume la forma della distribuzione.
Esempio 2: traccia la distribuzione dei valori in una colonna, raggruppati in un’altra colonna
Il codice seguente mostra come tracciare la distribuzione dei valori nella colonna dei punti , raggruppati per colonna della squadra :
import matplotlib.pyplot as plt #plot distribution of points by team df. groupby (' team ')[' points ']. plot (kind=' kde ') #add legend plt. legend ([' A ',' B '], title=' Team ') #add x-axis label plt. xlabel (' Points ')
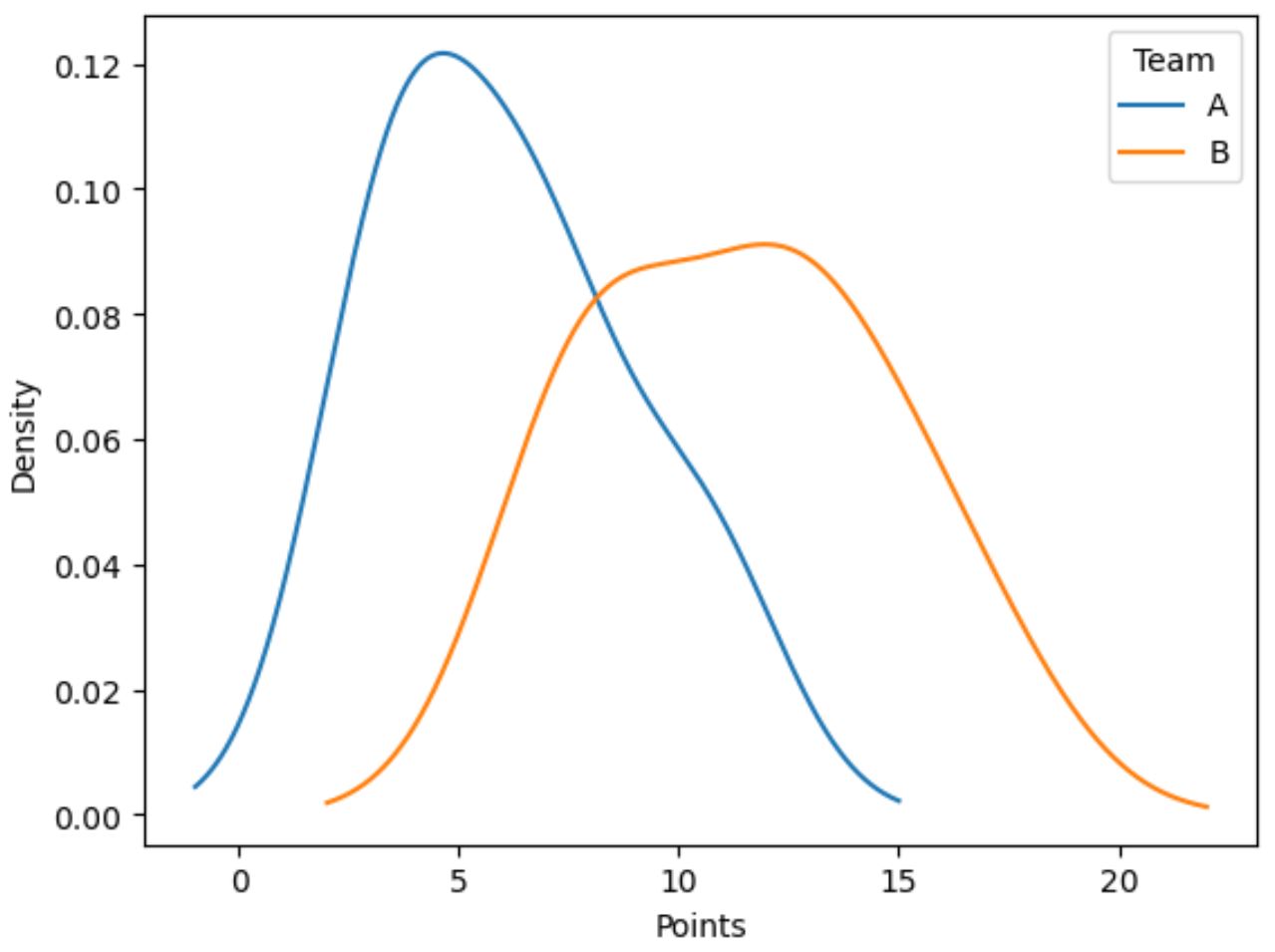
La linea blu mostra la distribuzione dei punti dei giocatori della squadra A mentre la linea arancione mostra la distribuzione dei punti dei giocatori della squadra B.
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni nei panda:
Come aggiungere titoli alle trame in Pandas
Come regolare la dimensione della figura di una trama di panda
Come tracciare più Pandas DataFrames in sottotrame
Come creare e personalizzare le legende della trama in Pandas
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più