Come calcolare la distanza di cook in python
La distanza di Cook viene utilizzata per identificare le osservazioni influenti in un modello di regressione.
La formula per la distanza di Cook è:
d i = (r i 2 / p*MSE) * (h ii / (1-h ii ) 2 )
Oro:
- r i è l’i- esimo residuo
- p è il numero di coefficienti nel modello di regressione
- MSE è l’errore quadratico medio
- h ii è l’ iesimo valore della leva finanziaria
In sostanza, la distanza di Cook misura quanto cambiano tutti i valori adattati del modello quando viene rimossa l’i- esima osservazione.
Maggiore è il valore della distanza di Cook, più influente è una data osservazione.
Come regola generale, si ritiene che qualsiasi osservazione con una distanza di Cook maggiore di 4/n (dove n = osservazioni totali) abbia una grande influenza.
Questo tutorial fornisce un esempio passo passo di come calcolare la distanza di Cook per un dato modello di regressione in Python.
Passaggio 1: inserisci i dati
Per prima cosa creeremo un piccolo set di dati con cui lavorare in Python:
import pandas as pd #create dataset df = pd. DataFrame ({' x ': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], ' y ': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
Passaggio 2: adattare il modello di regressione
Successivamente, adatteremo un semplice modello di regressione lineare :
import statsmodels. api as sm
#define response variable
y = df[' y ']
#define explanatory variable
x = df[' x ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
Passaggio 3: calcolare la distanza di cottura
Successivamente, calcoleremo la distanza di Cook per ciascuna osservazione nel modello:
#suppress scientific notation
import numpy as np
n.p. set_printoptions (suppress= True )
#create instance of influence
influence = model. get_influence ()
#obtain Cook's distance for each observation
cooks = influence. cooks_distance
#display Cook's distances
print (cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
Per impostazione predefinita, la funzione cooks_distance() visualizza un array di valori per la distanza di Cook per ciascuna osservazione seguito da un array di valori p corrispondenti.
Per esempio:
- Distanza di Cook per l’osservazione n. 1: 0,368 (valore p: 0,701)
- Distanza di Cook per l’osservazione n. 2: 0,061 (valore p: 0,941)
- Distanza di Cook per l’osservazione n. 3: 0,001 (valore p: 0,999)
E così via.
Passaggio 4: Visualizza le distanze del cuoco
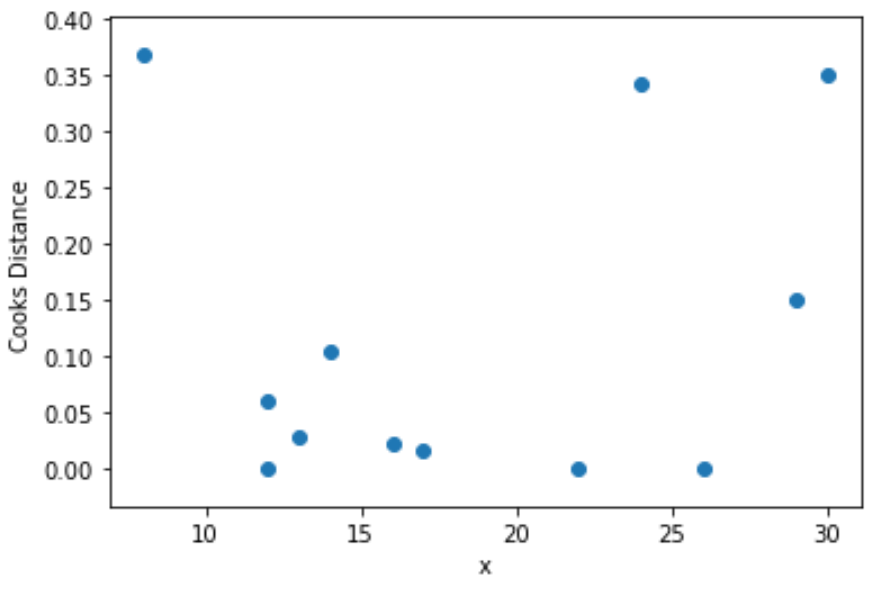
Infine, possiamo creare un grafico a dispersione per visualizzare i valori della variabile predittrice in funzione della distanza di Cook per ciascuna osservazione:
import matplotlib. pyplot as plt
plt. scatter (df.x, cooks[0])
plt. xlabel (' x ')
plt. ylabel (' Cooks Distance ')
plt. show ()
Pensieri finali
È importante notare che la distanza di Cook dovrebbe essere utilizzata per identificare osservazioni potenzialmente influenti. Solo perché un’osservazione è influente non significa che debba essere rimossa dal set di dati.
Per prima cosa bisogna verificare che l’osservazione non sia il risultato di un errore di inserimento dati o di altro evento strano. Se risulta essere un valore legittimo, puoi decidere se è opportuno rimuoverlo, lasciarlo così com’è o semplicemente sostituirlo con un valore alternativo come la mediana.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più