Come calcolare dffit in r
In statistica, spesso vogliamo sapere quale influenza hanno le diverse osservazioni sui modelli di regressione.
Un modo per calcolare l’influenza delle osservazioni è utilizzare una metrica nota come DFITS , che sta per “differenza negli adattamenti”.
Questa metrica ci dice quanto cambiano le previsioni fatte da un modello di regressione quando omettiamo un’osservazione individuale.
Questo tutorial mostra un esempio passo passo di come calcolare e visualizzare DFFIT per ogni osservazione in un modello in R.
Passaggio 1: creare un modello di regressione
Innanzitutto, creeremo un modello di regressione lineare multipla utilizzando il set di dati mtcars integrato in R:
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
Passaggio 2: calcolare DFFIT per ciascuna osservazione
Successivamente, utilizzeremo la funzione integrata dffits() per calcolare il valore DFFITS per ciascuna osservazione nel modello:
#calculate DFFITS for each observation in the model dffits <- as . data . frame (dffits(model)) #display DFFITS for each observation challenges dffits(model) Mazda RX4 -0.14633456 Mazda RX4 Wag -0.14633456 Datsun 710 -0.19956440 Hornet 4 Drive 0.11540062 Hornet Sportabout 0.32140303 Valiant -0.26586716 Duster 360 0.06282342 Merc 240D -0.03521572 Merc 230 -0.09780612 Merc 280 -0.22680622 Merc 280C -0.32763355 Merc 450SE -0.09682952 Merc 450SL -0.03841129 Merc 450SLC -0.17618948 Cadillac Fleetwood -0.15860270 Lincoln Continental -0.15567627 Chrysler Imperial 0.39098449 Fiat 128 0.60265798 Honda Civic 0.35544919 Toyota Corolla 0.78230167 Toyota Corona -0.25804885 Dodge Challenger -0.16674639 AMC Javelin -0.20965432 Camaro Z28 -0.08062828 Pontiac Firebird 0.67858692 Fiat X1-9 0.05951528 Porsche 914-2 0.09453310 Lotus Europa 0.55650363 Ford Pantera L 0.31169050 Ferrari Dino -0.29539098 Maserati Bora 0.76464932 Volvo 142E -0.24266054
Tipicamente, osserviamo più da vicino le osservazioni con valori DFITS superiori alla soglia di 2√ p/n dove:
- p: numero di variabili predittive utilizzate nel modello
- n: numero di osservazioni utilizzate nel modello
In questo esempio, la soglia sarebbe 0,5 :
#find number of predictors in model p <- length (model$coefficients)-1 #find number of observations n <- nrow (mtcars) #calculate DFFITS threshold value thresh <- 2* sqrt (p/n) thresh [1] 0.5
Possiamo ordinare le osservazioni in base ai loro valori DFITS per vedere se qualcuna di esse supera la soglia:
#sort observations by DFFITS, descending dffits[ order (-dffits[' dffits(model) ']), ] [1] 0.78230167 0.76464932 0.67858692 0.60265798 0.55650363 0.39098449 [7] 0.35544919 0.32140303 0.31169050 0.11540062 0.09453310 0.06282342 [13] 0.05951528 -0.03521572 -0.03841129 -0.08062828 -0.09682952 -0.09780612 [19] -0.14633456 -0.14633456 -0.15567627 -0.15860270 -0.16674639 -0.17618948 [25] -0.19956440 -0.20965432 -0.22680622 -0.24266054 -0.25804885 -0.26586716 [31] -0.29539098 -0.32763355
Possiamo vedere che le prime cinque osservazioni hanno un valore DFITS maggiore di 0,5, il che significa che potremmo voler studiare queste osservazioni più da vicino per determinare se hanno una grande influenza sul modello.
Passaggio 3: Visualizza i DFFIT per ciascuna osservazione
Infine, possiamo creare un rapido grafico per visualizzare i DFFIT per ciascuna osservazione:
#plot DFFITS values for each observation plot(dffits(model), type = ' h ') #add horizontal lines at absolute values for threshold abline(h = thresh, lty = 2) abline(h = -thresh, lty = 2)
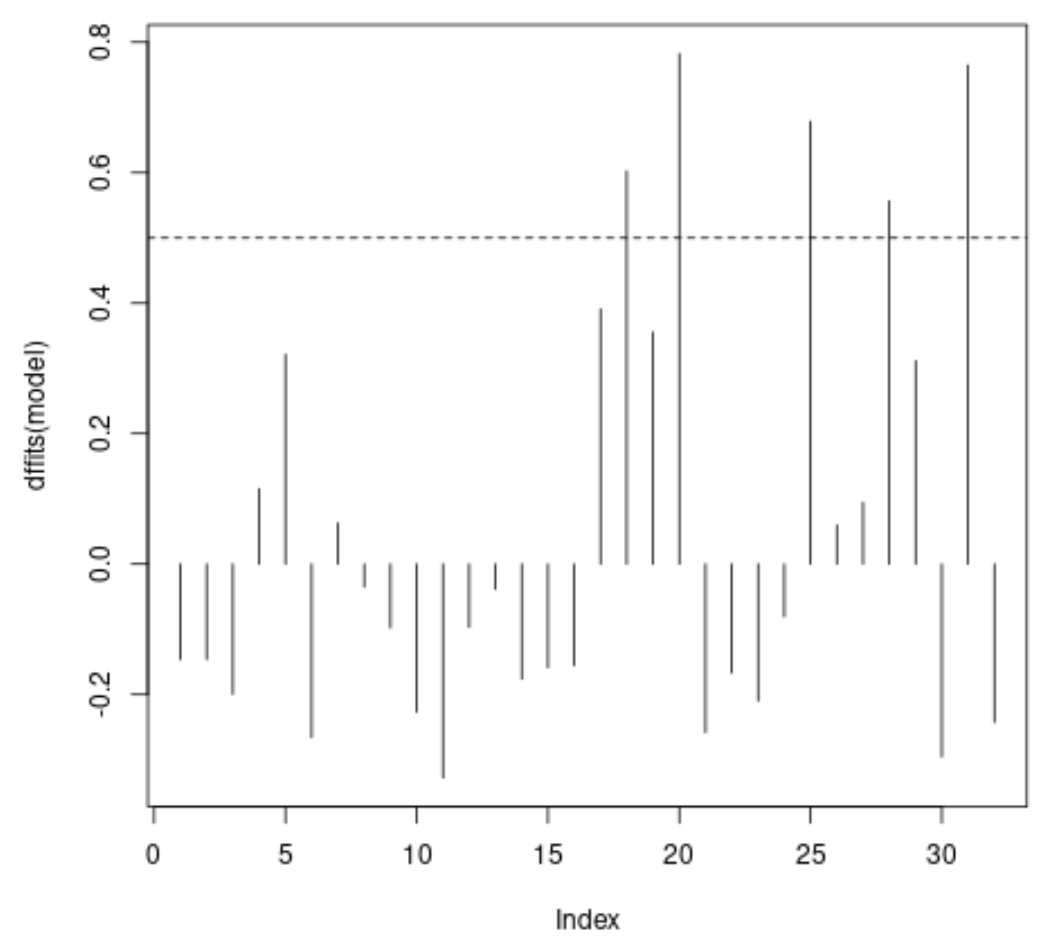
L’asse x mostra l’indice di ciascuna osservazione nel set di dati e il valore y mostra il valore DFITS corrispondente per ciascuna osservazione.
Risorse addizionali
Come eseguire una regressione lineare semplice in R
Come eseguire la regressione lineare multipla in R
Come calcolare le statistiche sulla leva finanziaria in R
Come creare una trama residua in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più