Binning della frequenza uguale in python
In statistica, il raggruppamento è il processo di inserimento di valori numerici in gruppi .
La forma più comune di clustering è nota come clustering a larghezza uguale , in cui dividiamo un set di dati in k gruppi di uguale larghezza.
Una forma di clustering meno comunemente utilizzata è nota come clustering a frequenza uguale , in cui dividiamo un set di dati in k gruppi aventi tutti lo stesso numero di frequenze.
Questo tutorial spiega come eseguire il clustering a frequenza uguale in Python.
Binning della frequenza uguale in Python
Supponiamo di avere un set di dati contenente 100 valori:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Raggruppamento di uguale larghezza:
Se creiamo un istogramma per visualizzare questi valori, Python utilizzerà per impostazione predefinita il raggruppamento di uguale larghezza:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
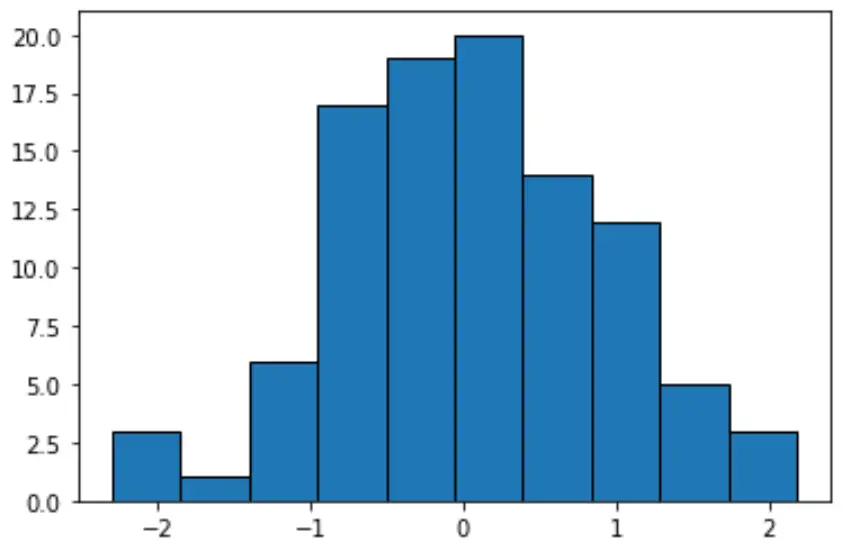
Ciascun gruppo ha una larghezza uguale di circa 0,4487, ma ciascun gruppo non contiene la stessa quantità di osservazioni. Per esempio:
- Il primo bin si estende da -2.3015387 a -1.8528279 e contiene 3 osservazioni.
- Il secondo contenitore si estende da -1,8528279 a -1,40411588 e contiene 1 osservazione.
- Il terzo bin si estende da -1,40411588 a -0,95540447 e contiene 6 osservazioni.
E così via.
Raggruppamento a frequenza uguale:
Per creare bucket contenenti un numero uguale di osservazioni, possiamo utilizzare la seguente funzione:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
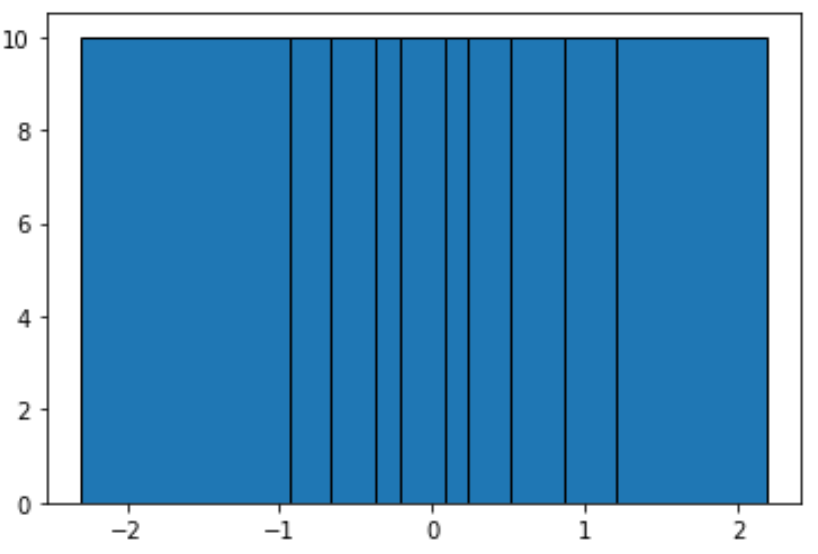
Ogni gruppo non ha la stessa larghezza, ma contiene la stessa quantità di osservazioni. Per esempio:
- Il primo contenitore si estende da -2,3015387 a -0,93576943 e contiene 10 osservazioni.
- Il secondo contenitore si estende da -0,93576943 a -0,67124613 e contiene 10 osservazioni.
- Il terzo bin si estende da -0,67124613 a -0,37528495 e contiene 10 osservazioni.
E così via.
Possiamo vedere dall’istogramma che ogni contenitore chiaramente non ha la stessa larghezza, ma ogni contenitore contiene lo stesso numero di osservazioni, il che è confermato dal fatto che l’altezza di ciascun contenitore è uguale.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più