Qualità di vestibilità
Questo articolo spiega cos’è la bontà di adattamento nelle statistiche. Allo stesso modo, mostra come misurare la bontà di adattamento di un modello di regressione e, inoltre, sarà possibile vedere un esercizio di bontà di adattamento risolto.
Cos’è la bontà di adattamento?
Nelle statistiche, la bontà di adattamento indica quanto bene un modello di regressione si adatta al campione di dati. In altre parole, la bontà di adattamento di un modello di regressione si riferisce al livello di accoppiamento tra l’insieme delle osservazioni e i valori ottenuti attraverso la regressione.
Pertanto, quanto migliore è l’adattamento di un modello di regressione, tanto meglio esso spiega i dati studiati. Pertanto, vogliamo che il modello statistico si adatti meglio, meglio è.
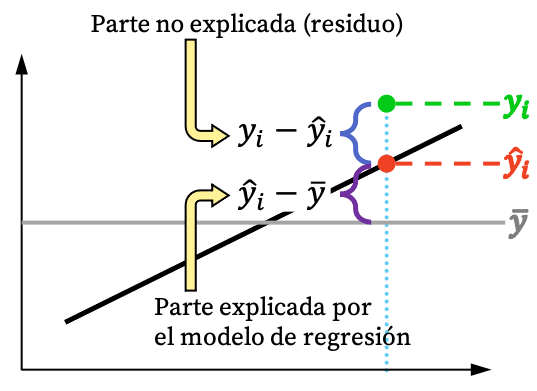
Come puoi vedere dall’immagine sopra, il valore di un’osservazione di solito non può essere completamente spiegato dal modello di regressione. Ma logicamente, quanto più il modello di regressione riesce a spiegare il set di dati, tanto meglio si adatterà. In breve, siamo interessati a un modello di regressione il più restrittivo possibile.
Bontà di adattamento di un modello di regressione
Per determinare la bontà dell’adattamento di un modello di regressione, si utilizza tipicamente il coefficiente di determinazione , che è un coefficiente statistico che indica la percentuale spiegata dal modello di regressione. Pertanto, quanto più alto è il coefficiente di determinazione di un modello, tanto meglio il modello sarà adattato al campione di dati.

Tuttavia, va notato che maggiore è il numero di variabili di un modello di regressione, maggiore sarà il suo coefficiente di determinazione. Per questo motivo, il coefficiente di determinazione corretto viene spesso utilizzato anche per misurare la bontà di adattamento di un modello. Il coefficiente di determinazione aggiustato è una variazione del coefficiente precedente che indica la percentuale spiegata dal modello di regressione, penalizzando per ciascuna variabile esplicativa inclusa nel modello.

È quindi preferibile utilizzare il coefficiente di determinazione aggiustato per confrontare due modelli con un numero di variabili diverse, perché tiene conto del numero di variabili incluse nel modello.
Infine, va notato che il test del Chi-quadrato può essere utilizzato anche per misurare la bontà di adattamento di un modello di regressione, sebbene solitamente vengano utilizzati i valori dei due coefficienti precedenti.
Esempio concreto di buona vestibilità
Infine, assisteremo ad un esercizio di qualità dell’aggiustamento per completare l’assimilazione di questo concetto statistico.
- Con la stessa serie di dati vengono eseguiti due diversi modelli di regressione lineare, i cui risultati potete vedere nella tabella seguente. Quale modello è meglio utilizzare?
| Modello di regressione 1 | Modello di regressione 2 | |
|---|---|---|
| Coefficiente di determinazione | 57% | 64% |
| Coefficiente di determinazione rettificato | 49% | 43% |
| Numero di variabili esplicative | 3 | 7 |
In questo caso, assumiamo che entrambi i modelli soddisfino le precedenti ipotesi dei modelli di regressione lineare e, pertanto, dobbiamo solo analizzare la bontà di adattamento dei modelli.
Il modello di regressione 2 ha un coefficiente di determinazione più elevato rispetto al modello di regressione 1, quindi a priori sembra essere un modello di regressione migliore poiché è in grado di spiegare meglio il campione di dati.
Tuttavia, il modello di regressione 2 ha 7 variabili indipendenti nel modello, mentre il modello di regressione 1 ne ha solo 3. Quindi il modello 2 sarà molto più complicato e più difficile da interpretare rispetto al primo modello.
Inoltre, se osserviamo il coefficiente di determinazione corretto, che tiene conto del numero di variabili nel modello, il modello di regressione 1 ha un coefficiente di determinazione corretto più elevato rispetto al modello di regressione 2.
In conclusione, sebbene sia meglio utilizzare il modello di regressione 1, poiché il suo coefficiente di determinazione corretto è superiore a quello del modello di regressione 2. Il modello di regressione 2 ha un coefficiente di determinazione non corretto più elevato, è perché includevano molte più variabili nella regressione modello 1. modello, che aumenta il valore di detto coefficiente ma rende più difficile l’interpretazione del modello e, sicuramente, peggiore la previsione di un nuovo valore.
Per confrontare modelli con un numero diverso di variabili, è meglio utilizzare il coefficiente di determinazione corretto perché penalizza per ogni variabile aggiunta al modello. Come hai visto in questo esempio, secondo il coefficiente di determinazione non corretto, il modello di regressione 2 è migliore, tuttavia, attraverso il coefficiente di determinazione corretto possiamo sapere che il modello di regressione 1 è effettivamente migliore.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più