Come leggere righe specifiche da un file csv in r
È possibile utilizzare i seguenti metodi per leggere righe specifiche da un file CSV in R:
Metodo 1: importa un file CSV da una riga specifica
df <- read. csv (" my_data.csv ", skip= 2 )
Questo particolare esempio salterà le prime due righe del file CSV e importerà tutte le altre righe del file a partire dalla terza riga.
Metodo 2: importa un file CSV in cui le righe soddisfano la condizione
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
Questo particolare esempio importerà solo le righe dal file CSV il cui valore nella colonna “punti” è maggiore di 90.
I seguenti esempi mostrano come utilizzare nella pratica ciascuno di questi metodi con il seguente file CSV chiamato my_data.csv :
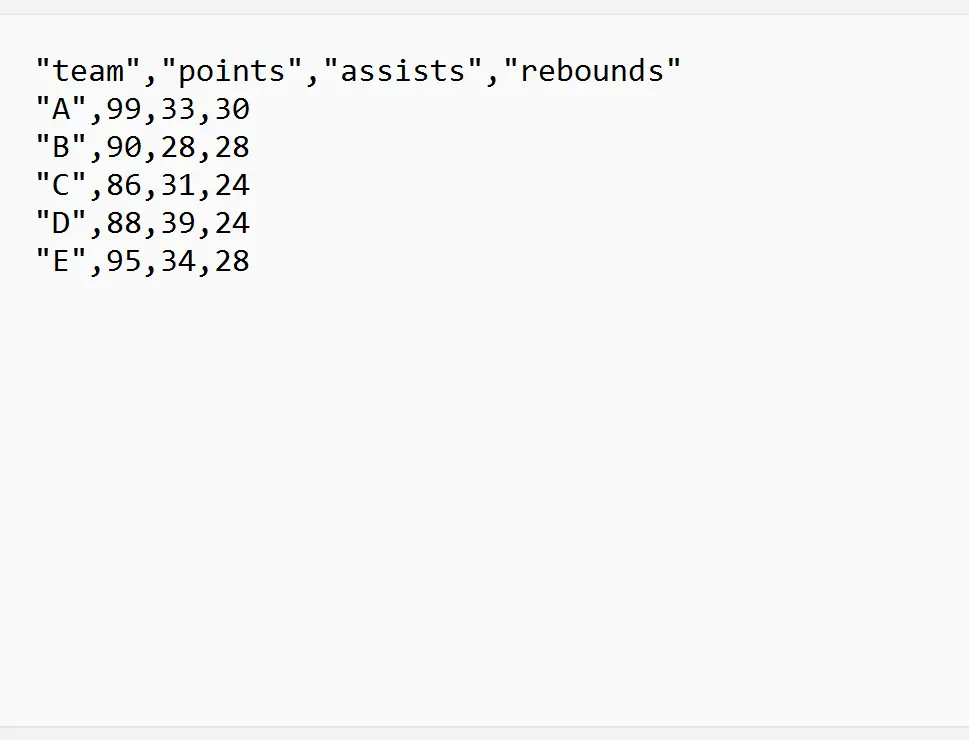
Esempio 1: importa un file CSV da una riga specifica
Il codice seguente mostra come importare il file CSV e ignorare le prime due righe del file:
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Tieni presente che le prime due righe (con le squadre A e B) sono state ignorate durante l’importazione del file CSV.
Per impostazione predefinita, R tenta di utilizzare i valori della successiva riga disponibile come nomi di colonna.
Per rinominare le colonne, puoi utilizzare la funzionenames() come segue:
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Esempio 2: importa un file CSV in cui le righe soddisfano la condizione
Supponiamo di voler importare solo quelle righe dal file CSV il cui valore nella colonna punti è maggiore di 90.
Possiamo usare la funzione read.csv.sql dal pacchetto sqldf per fare questo:
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
Da notare che sono state importate solo le due righe del file CSV il cui valore nella colonna “punti” è maggiore di 90.
Nota n. 1 : in questo esempio, abbiamo utilizzato l’argomento eol per specificare che la “fine riga” nel file è indicata da \n , che rappresenta una nuova riga.
Nota n.2: in questo esempio abbiamo utilizzato una semplice query SQL, ma puoi scrivere query più complesse per filtrare le righe in base a un numero ancora maggiore di condizioni.
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in R:
Come leggere un CSV da un URL in R
Come unire più file CSV in R
Come esportare un frame di dati in un file CSV in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più