Una guida completa al dataset dei diamanti in r
Il set di dati Diamond è un set di dati integrato nel pacchetto ggplot2 in R.
Contiene misurazioni su 10 diverse variabili (come prezzo, colore, purezza, ecc.) per 53.940 diamanti diversi.
Questo tutorial spiega come esplorare, riepilogare e visualizzare il set di dati del diamante in R.
Carica il set di dati del diamante
Poiché il set di dati del diamante è un set di dati integrato in ggplot2, dobbiamo prima installare (se non già) e caricare il pacchetto ggplot2:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
Una volta caricato ggplot2, possiamo utilizzare la funzione data() per caricare il dataset del diamante :
data(diamonds)
Possiamo dare un’occhiata alle prime sei righe del set di dati utilizzando la funzione head() :
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Riassumere il set di dati del diamante
Possiamo utilizzare la funzione summary() per riassumere rapidamente ogni variabile nel set di dati:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
Per ciascuna delle variabili numeriche possiamo vedere le seguenti informazioni:
- Min : il valore minimo.
- 1° Qu : il valore del primo quartile (25° percentile).
- Mediana : il valore mediano.
- Media : il valore medio.
- 3° Qu : Il valore del terzo quartile (75° percentile).
- Max : il valore massimo.
Per le variabili categoriali nel set di dati (taglio, colore e chiarezza), vediamo un conteggio della frequenza di ciascun valore.
Ad esempio, per la variabile cut :
- Giusto : questo valore appare 1.610 volte.
- Buono : questo valore appare 4.906 volte.
- Molto buono : questo valore appare 12.082 volte.
- Premium : questo valore appare 13.791 volte.
- Ideale : questo valore appare 21.551 volte.
Possiamo usare la funzione dim() per ottenere le dimensioni del set di dati in termini di numero di righe e colonne:
#display rows and columns
dim(diamonds)
[1] 53940 10
Possiamo vedere che il set di dati ha 53.940 righe e 10 colonne.
Possiamo anche usare la funzionenames () per visualizzare i nomi delle colonne del data frame:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Visualizza il dataset dei diamanti
Possiamo anche creare grafici per visualizzare i valori del set di dati.
Ad esempio, possiamo utilizzare la funzione geom_histogram() per creare un istogramma dei valori di una determinata variabile:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
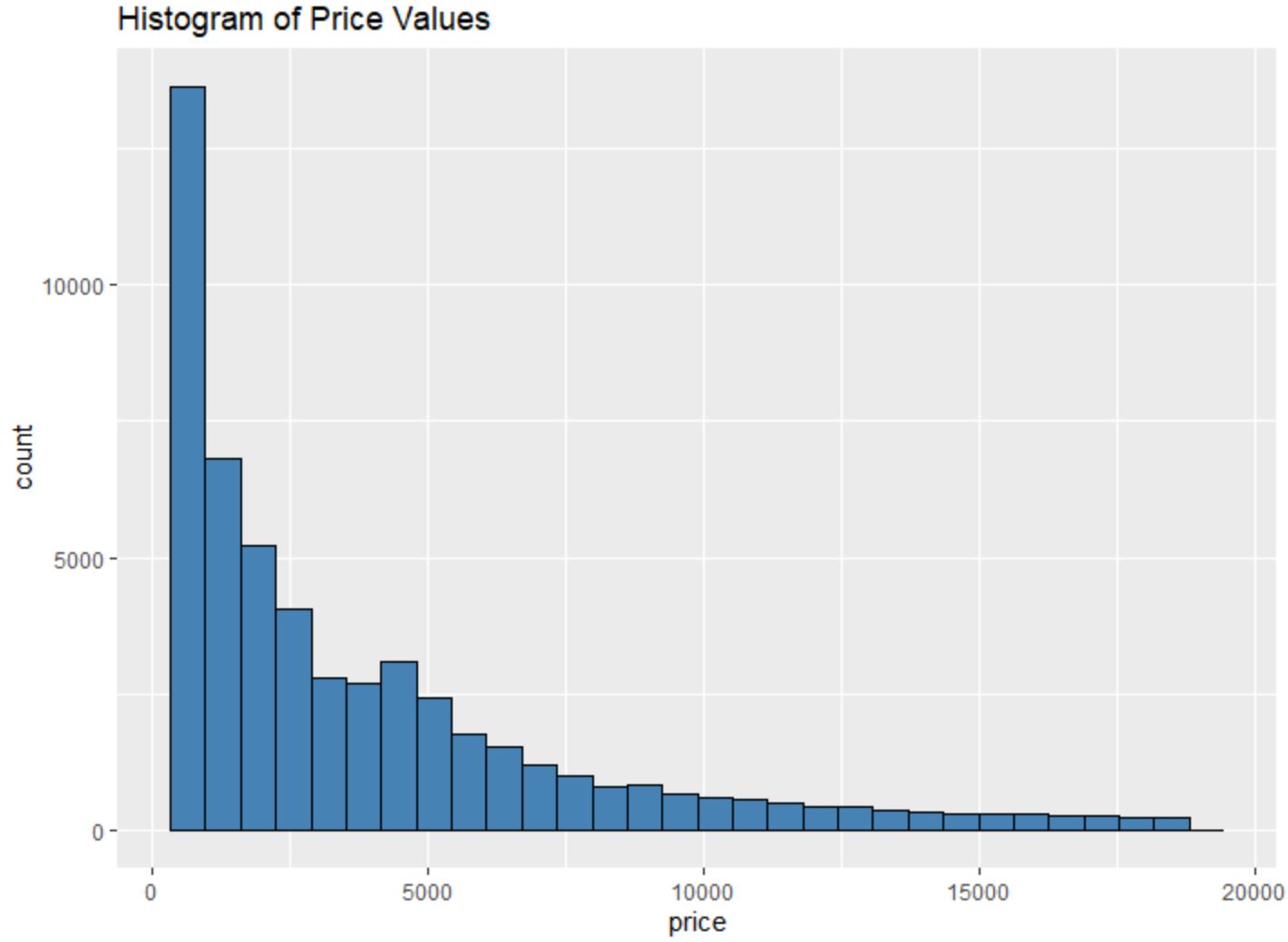
Possiamo anche utilizzare la funzione geom_point() per creare una nuvola di punti di qualsiasi combinazione di variabili a coppie:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
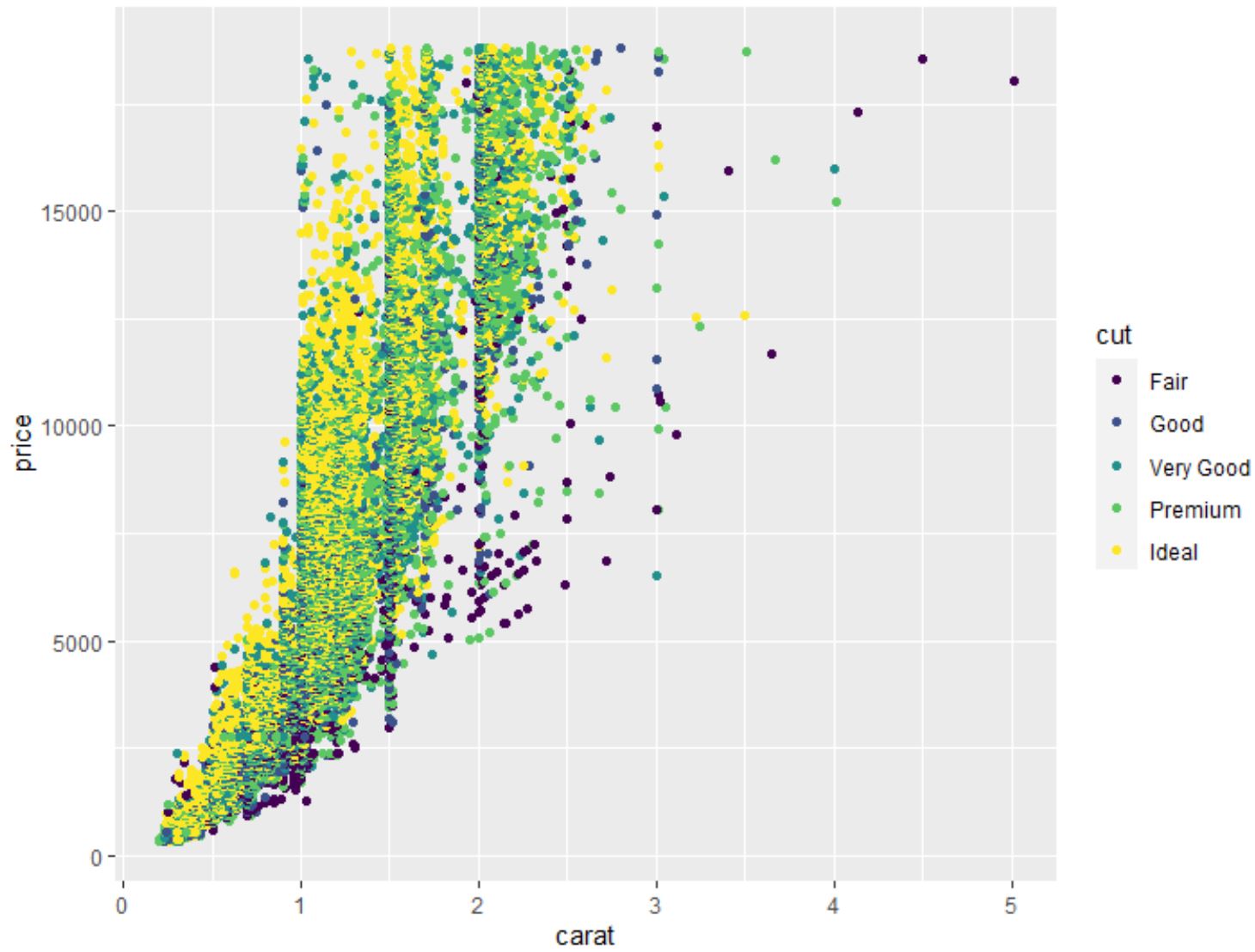
Possiamo anche usare la funzione geom_boxplot() per creare un boxplot di una variabile raggruppata da un’altra variabile:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
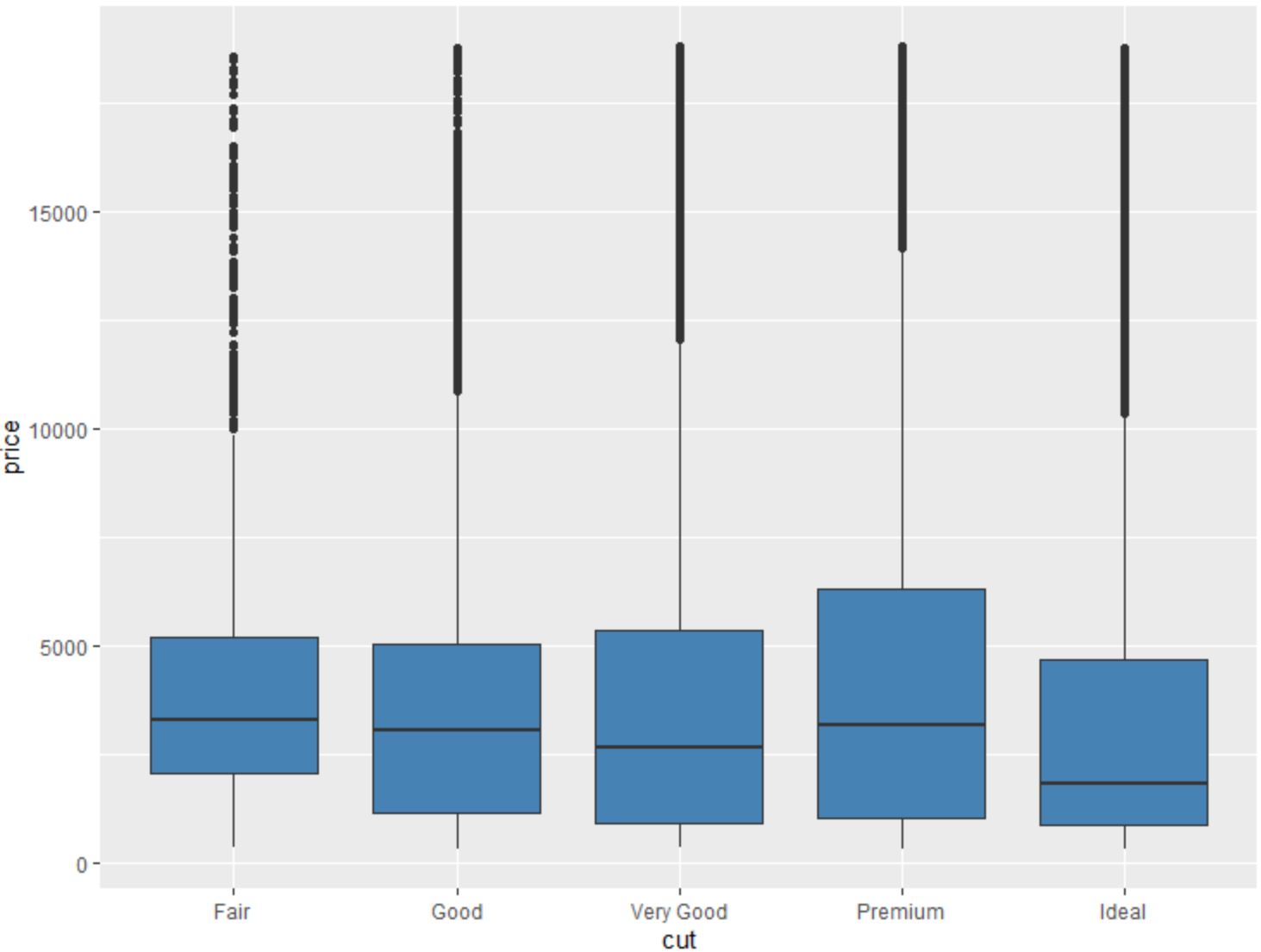
Usando queste funzioni ggplot2, possiamo imparare molto sulle variabili nel set di dati del diamante .
Risorse addizionali
I seguenti tutorial spiegano come esplorare altri set di dati in R:
Una guida completa al set di dati Iris in R
Una guida completa al set di dati mtcars in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più