Randomizzazione in statistica: definizione ed esempio
Nel campo della statistica, la randomizzazione si riferisce all’atto di assegnare in modo casuale i soggetti dello studio a diversi gruppi di trattamento.
Ad esempio, supponiamo che i ricercatori reclutino 100 soggetti per partecipare a uno studio in cui sperano di capire se due pillole diverse hanno o meno effetti diversi sulla pressione sanguigna.
Possono decidere di utilizzare un generatore di numeri casuali per assegnare casualmente a ciascun soggetto l’uso della pillola n. 1 o della pillola n. 2.
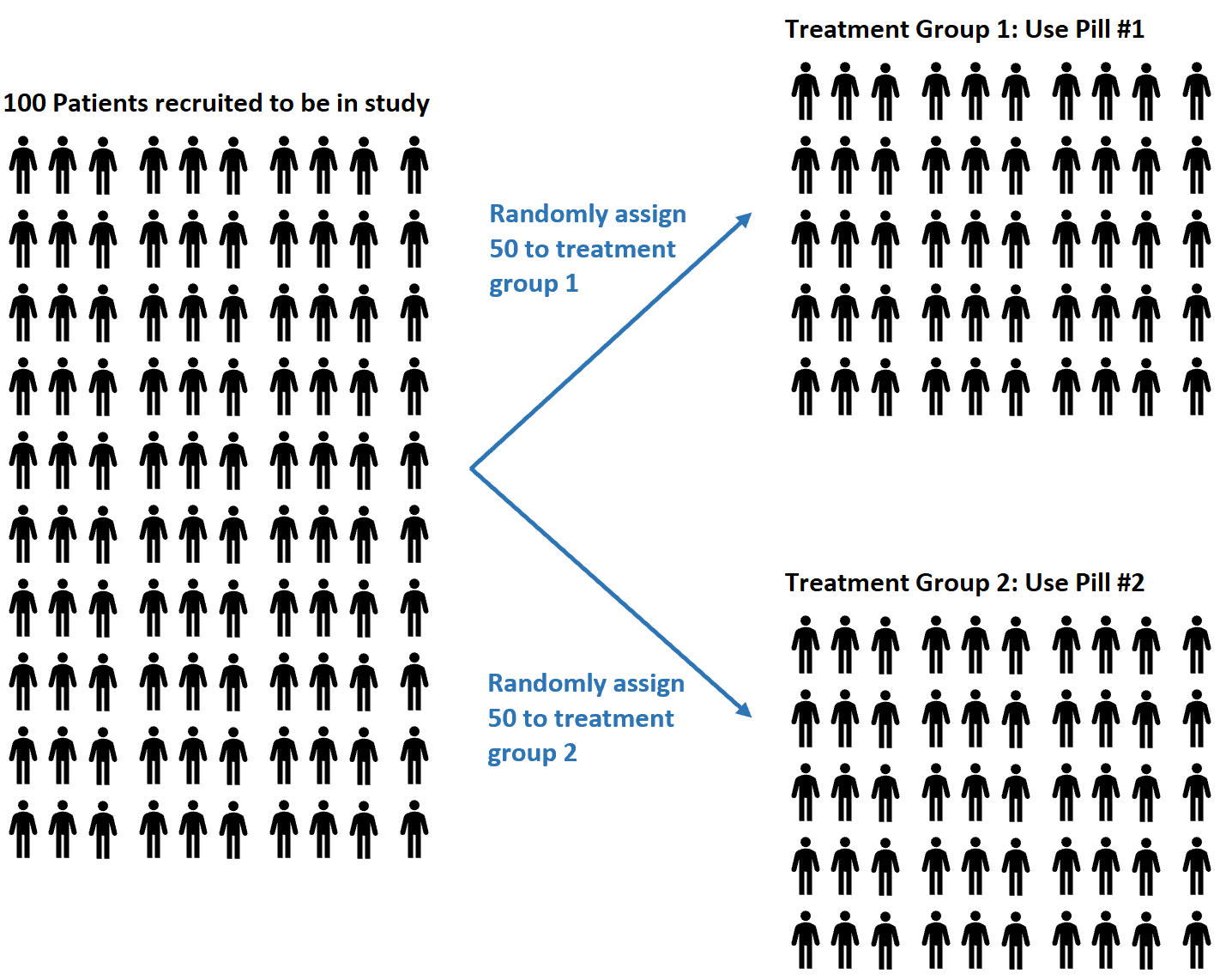
Vantaggi della randomizzazione
Lo scopo della randomizzazione è controllare le variabili nascoste , ovvero variabili che non sono direttamente incluse in un’analisi, ma che tuttavia influiscono in qualche modo sull’analisi.
Ad esempio, se i ricercatori studiassero gli effetti di due diverse pillole sulla pressione sanguigna, le seguenti variabili nascoste potrebbero influenzare l’analisi:
- Abiti da smoking
- Dieta
- Esercizio
Assegnando casualmente i soggetti ai gruppi di trattamento, massimizziamo la possibilità che le variabili nascoste influenzino allo stesso modo entrambi i gruppi di trattamento.
Ciò significa che qualsiasi differenza nella pressione sanguigna può essere attribuita al tipo di pillola piuttosto che all’effetto di una variabile nascosta.
Blocca la randomizzazione
Un’estensione della randomizzazione è nota come randomizzazione a blocchi . Questo è il processo di separazione dei soggetti in blocchi e quindi di utilizzo della randomizzazione per assegnare i soggetti all’interno dei blocchi a trattamenti diversi.
Se, ad esempio, i ricercatori vogliono sapere se due diverse pillole influenzano la pressione sanguigna in modo diverso, possono prima separare tutti i soggetti in due blocchi in base al sesso: maschio o femmina.
Quindi, in ciascun blocco, possono utilizzare la randomizzazione per assegnare casualmente i soggetti a utilizzare la pillola n. 1 o la pillola n. 2.
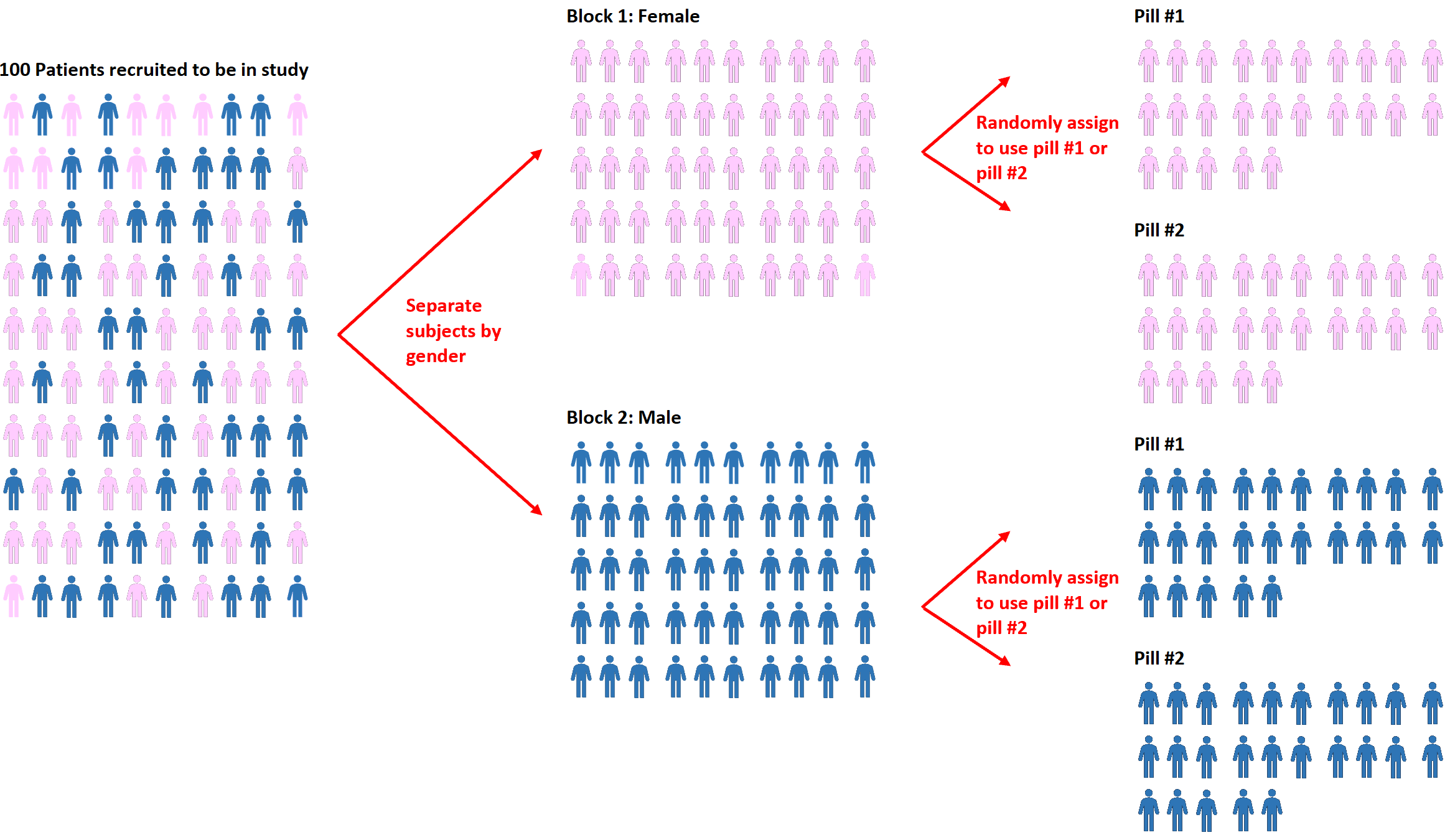
Il vantaggio di questo approccio è che i ricercatori possono controllare direttamente qualsiasi effetto che il genere possa avere sulla pressione sanguigna, poiché sappiamo che è probabile che uomini e donne rispondano in modo diverso a ciascuna pillola.
Utilizzando il genere come blocco, siamo in grado di eliminare questa variabile come potenziale fonte di variazione. Se ci sono differenze nella pressione sanguigna tra le due pillole, allora possiamo sapere che il sesso non è la causa alla base di queste differenze.
Risorse addizionali
Il blocco in statistica: definizione ed esempio
Randomizzazione dei blocchi permutati: definizione ed esempio
Variabili nascoste: definizione ed esempi
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più