Adattamento della curva in r (con esempi)
Spesso potresti voler trovare l’equazione che meglio si adatta a una curva di R.
Il seguente esempio passo passo spiega come adattare le curve ai dati in R utilizzando la funzione poly() e come determinare quale curva si adatta meglio ai dati.
Passaggio 1: creare e visualizzare i dati
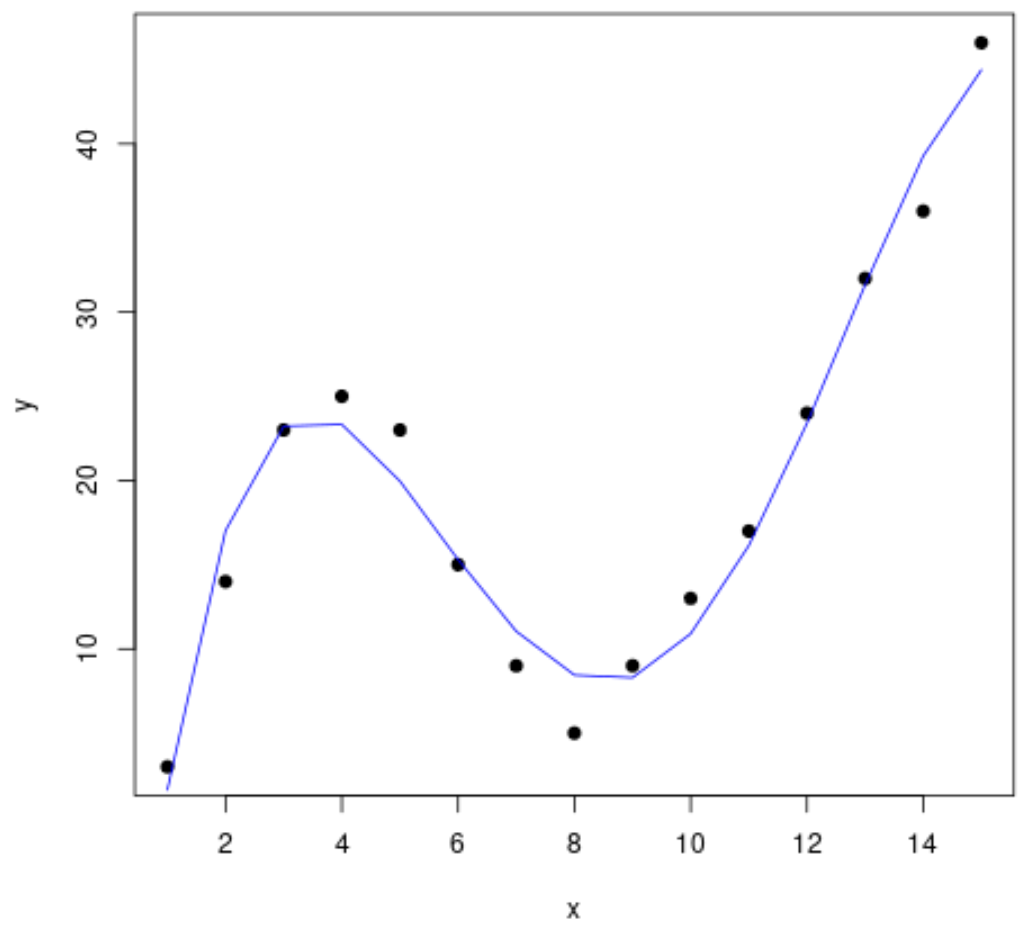
Iniziamo creando un set di dati falso, quindi creiamo un grafico a dispersione per visualizzare i dati:
#create data frame df <- data. frame (x=1:15, y=c(3, 14, 23, 25, 23, 15, 9, 5, 9, 13, 17, 24, 32, 36, 46)) #create a scatterplot of x vs. y plot(df$x, df$y, pch= 19 , xlab=' x ', ylab=' y ')
Passaggio 2: regola più curve
Adattiamo quindi diversi modelli di regressione polinomiale ai dati e visualizziamo la curva di ciascun modello nello stesso grafico:
#fit polynomial regression models up to degree 5 fit1 <- lm(y~x, data=df) fit2 <- lm(y~poly(x,2,raw= TRUE ), data=df) fit3 <- lm(y~poly(x,3,raw= TRUE ), data=df) fit4 <- lm(y~poly(x,4,raw= TRUE ), data=df) fit5 <- lm(y~poly(x,5,raw= TRUE ), data=df) #create a scatterplot of x vs. y plot(df$x, df$y, pch=19, xlab=' x ', ylab=' y ') #define x-axis values x_axis <- seq(1, 15, length= 15 ) #add curve of each model to plot lines(x_axis, predict(fit1, data. frame (x=x_axis)), col=' green ') lines(x_axis, predict(fit2, data. frame (x=x_axis)), col=' red ') lines(x_axis, predict(fit3, data. frame (x=x_axis)), col=' purple ') lines(x_axis, predict(fit4, data. frame (x=x_axis)), col=' blue ') lines(x_axis, predict(fit5, data. frame (x=x_axis)), col=' orange ')
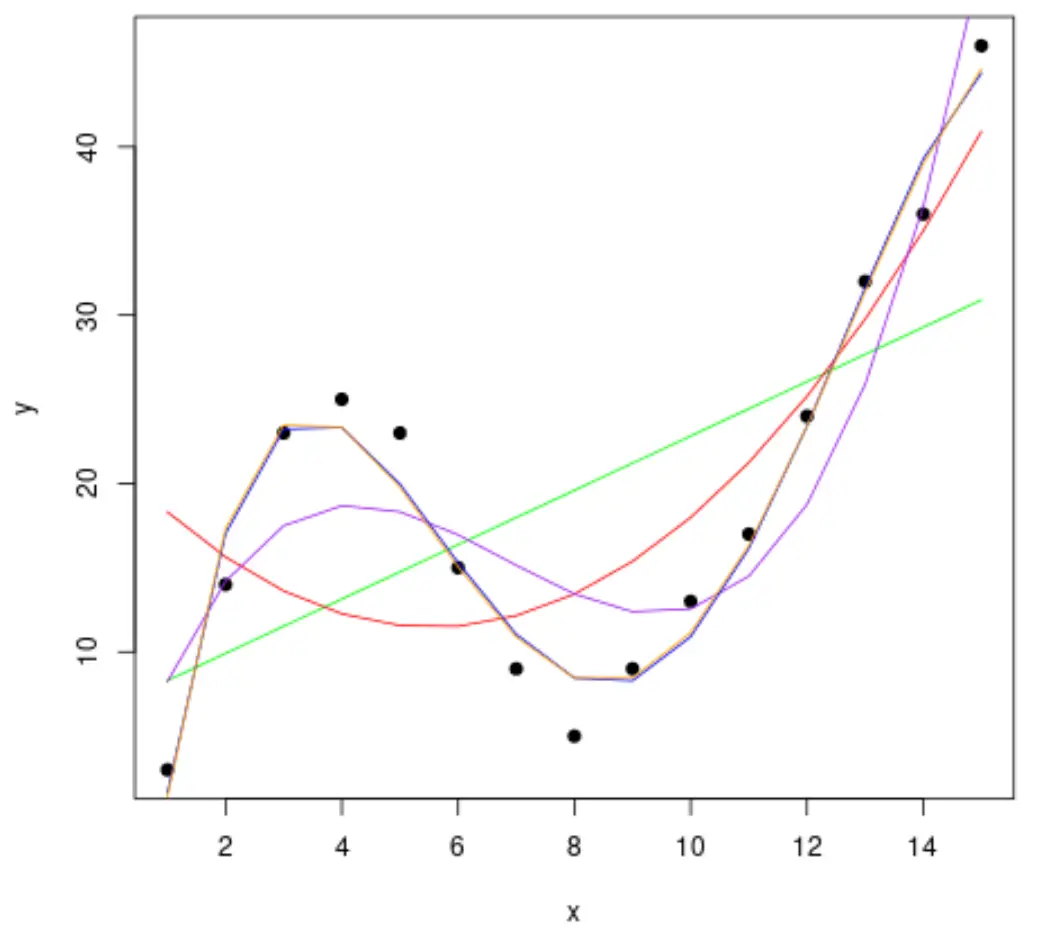
Per determinare quale curva si adatta meglio ai dati, possiamo osservare il quadrato R corretto di ciascun modello.
Questo valore indica la percentuale di variazione nella variabile di risposta che può essere spiegata dalle variabili predittive nel modello, adattata al numero di variabili predittive.
#calculated adjusted R-squared of each model summary(fit1)$adj. r . squared summary(fit2)$adj. r . squared summary(fit3)$adj. r . squared summary(fit4)$adj. r . squared summary(fit5)$adj. r . squared [1] 0.3144819 [1] 0.5186706 [1] 0.7842864 [1] 0.9590276 [1] 0.9549709
Dal risultato, possiamo vedere che il modello con l’R quadrato corretto più alto è il polinomio di quarto grado, che ha un R quadrato corretto di 0,959 .
Passaggio 3: Visualizza la curva finale
Infine, possiamo creare un grafico a dispersione con la curva del modello polinomiale di quarto grado:
#create a scatterplot of x vs. y plot(df$x, df$y, pch=19, xlab=' x ', ylab=' y ') #define x-axis values x_axis <- seq(1, 15, length= 15 ) #add curve of fourth-degree polynomial model lines(x_axis, predict(fit4, data. frame (x=x_axis)), col=' blue ')
Possiamo anche ottenere l’equazione per questa riga utilizzando la funzione summary() :
summary(fit4)
Call:
lm(formula = y ~ poly(x, 4, raw = TRUE), data = df)
Residuals:
Min 1Q Median 3Q Max
-3.4490 -1.1732 0.6023 1.4899 3.0351
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -26.51615 4.94555 -5.362 0.000318 ***
poly(x, 4, raw = TRUE)1 35.82311 3.98204 8.996 4.15e-06 ***
poly(x, 4, raw = TRUE)2 -8.36486 0.96791 -8.642 5.95e-06 ***
poly(x, 4, raw = TRUE)3 0.70812 0.08954 7.908 1.30e-05 ***
poly(x, 4, raw = TRUE)4 -0.01924 0.00278 -6.922 4.08e-05 ***
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.424 on 10 degrees of freedom
Multiple R-squared: 0.9707, Adjusted R-squared: 0.959
F-statistic: 82.92 on 4 and 10 DF, p-value: 1.257e-07
L’equazione della curva è la seguente:
y = -0,0192x 4 + 0,7081x 3 – 8,3649x 2 + 35,823x – 26,516
Possiamo utilizzare questa equazione per prevedere il valore della variabile di risposta in base alle variabili predittive nel modello. Ad esempio, se x = 4, allora dovremmo prevedere che y = 23,34 :
y = -0,0192(4) 4 + 0,7081(4) 3 – 8,3649(4) 2 + 35,823(4) – 26,516 = 23,34
Risorse addizionali
Un’introduzione alla regressione polinomiale
Regressione polinomiale in R (passo dopo passo)
Come utilizzare la funzione seq in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più