Introduzione alla regressione lazo
Nella regressione lineare multipla ordinaria, utilizziamo un insieme di variabili predittive p e una variabile di risposta per adattare un modello della forma:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Oro:
- Y : la variabile di risposta
- X j : la j- esima variabile predittiva
- β j : L’effetto medio su Y di un aumento di un’unità in X j , mantenendo fissi tutti gli altri predittori
- ε : Il termine di errore
I valori di β 0 , β 1 , B 2 , …, β p vengono scelti utilizzando il metodo dei minimi quadrati , che minimizza la somma dei quadrati dei residui (RSS):
RSS = Σ(y i – ŷ i ) 2
Oro:
- Σ : simbolo greco che significa somma
- y i : il valore di risposta effettivo per l’ i-esima osservazione
- ŷ i : il valore di risposta previsto basato sul modello di regressione lineare multipla
Tuttavia, quando le variabili predittive sono altamente correlate, la multicollinearità può diventare un problema. Ciò può rendere inaffidabili le stime dei coefficienti del modello e presentare una varianza elevata. Cioè, quando il modello viene applicato a un nuovo set di dati mai visto prima, è probabile che funzioni in modo scarso.
Un modo per aggirare questo problema è utilizzare un metodo noto come regressione lazo , che cerca invece di ridurre al minimo quanto segue:
RSS + λΣ|β j |
dove j va da 1 a p e λ ≥ 0.
Questo secondo termine nell’equazione è noto come penalità di ritiro .
Quando λ = 0, questo termine di penalità non ha alcun effetto e la regressione al lazo produce le stesse stime dei coefficienti dei minimi quadrati.
Tuttavia, quando λ si avvicina all’infinito, la penalità di rimozione diventa più influente e le variabili predittive che non sono importabili nel modello vengono ridotte a zero e alcune vengono addirittura rimosse dal modello.
Perché utilizzare la regressione Lazo?
Il vantaggio della regressione con lazo rispetto alla regressione dei minimi quadrati è il compromesso bias-varianza .
Ricordiamo che l’errore quadratico medio (MSE) è una metrica che possiamo utilizzare per misurare l’accuratezza di un determinato modello e viene calcolata come segue:
MSE = Var( f̂( x 0 )) + [Bias( f̂( x 0 ))] 2 + Var(ε)
MSE = Varianza + Bias 2 + Errore irriducibile
L’idea di base della regressione lazo è quella di introdurre una piccola distorsione in modo che la varianza possa essere significativamente ridotta, portando a un MSE complessivo inferiore.
Per illustrare ciò, si consideri il seguente grafico:

Si noti che all’aumentare di λ, la varianza diminuisce in modo significativo con un aumento molto piccolo della distorsione. Tuttavia, oltre un certo punto, la varianza diminuisce meno rapidamente e la diminuzione dei coefficienti porta ad una loro significativa sottostima, che porta ad un forte aumento della distorsione.
Possiamo vedere dal grafico che l’MSE del test è più basso quando scegliamo un valore per λ che produca un compromesso ottimale tra bias e varianza.
Quando λ = 0, il termine di penalità nella regressione con lazo non ha alcun effetto e quindi produce le stesse stime dei coefficienti dei minimi quadrati. Tuttavia, aumentando λ fino a un certo punto, possiamo ridurre l’MSE complessivo del test.
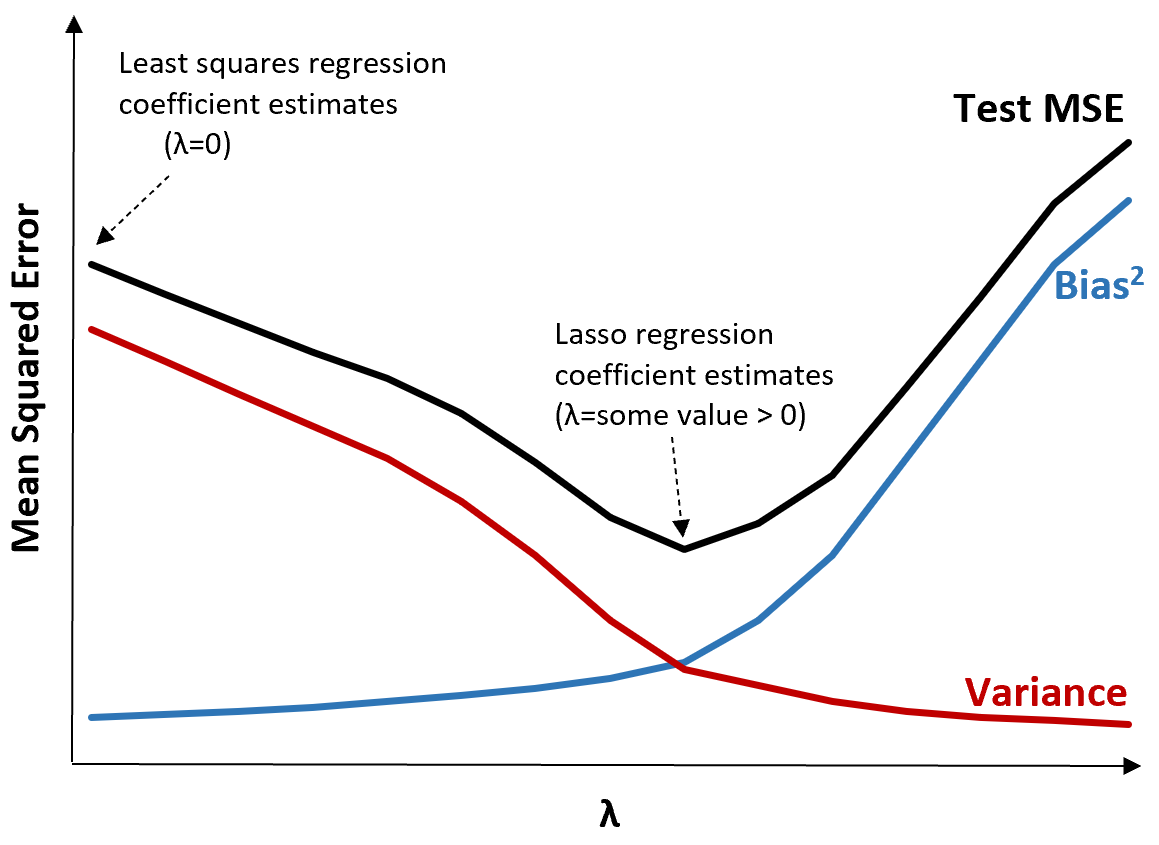
Ciò significa che l’adattamento del modello mediante la regressione con lazo produrrà errori di test minori rispetto all’adattamento del modello mediante la regressione dei minimi quadrati.
Regressione lazo vs regressione Ridge
La regressione Lazo e la regressione Ridge sono entrambi noti come metodi di regolarizzazione perché entrambi tentano di ridurre al minimo la somma residua dei quadrati (RSS) nonché un determinato termine di penalità.
In altre parole, vincolano o regolarizzano le stime dei coefficienti del modello.
Tuttavia, i termini di penalità utilizzati sono leggermente diversi:
- La regressione al lazo tenta di minimizzare RSS + λΣ|β j |
- La regressione della cresta tenta di minimizzare RSS + λΣβ j 2
Quando utilizziamo la regressione ridge, i coefficienti di ciascun predittore vengono ridotti a zero ma nessuno di essi può arrivare completamente a zero .
Al contrario, quando usiamo la regressione con lazo, è possibile che alcuni coefficienti diventino completamente pari a zero quando λ diventa sufficientemente grande.
In termini tecnici, la regressione lazo è in grado di produrre modelli “sparsi”, ovvero modelli che includono solo un sottoinsieme di variabili predittive.
Ciò solleva la domanda: è migliore la regressione della cresta o la regressione del lazo?
La risposta: dipende!
Nei casi in cui solo un numero limitato di variabili predittive sono significative, la regressione lazo tende a funzionare meglio perché è in grado di ridurre completamente a zero le variabili insignificanti e rimuoverle dal modello.
Tuttavia, quando molte variabili predittive sono significative nel modello e i relativi coefficienti sono approssimativamente uguali, la regressione ridge tende a funzionare meglio perché mantiene tutti i predittori nel modello.
Per determinare quale modello è più efficace nel fare previsioni, eseguiamo una convalida incrociata k-fold . Qualunque modello produca l’errore quadratico medio (MSE) più basso è il modello migliore da utilizzare.
Passaggi per eseguire nella pratica una regressione con il lazo
È possibile utilizzare i seguenti passaggi per eseguire una regressione lazo:
Passaggio 1: calcolare la matrice di correlazione e i valori VIF per le variabili predittive.
Innanzitutto, dobbiamo produrre una matrice di correlazione e calcolare i valori VIF (fattore di inflazione della varianza) per ciascuna variabile predittrice.
Se rileviamo una forte correlazione tra le variabili predittive e valori VIF elevati (alcuni testi definiscono un valore VIF “alto” come 5 mentre altri usano 10), allora la regressione lazo è probabilmente appropriata.
Tuttavia, se nei dati non è presente multicollinearità, potrebbe non essere necessario eseguire innanzitutto la regressione lazo. Invece, possiamo eseguire la regressione ordinaria dei minimi quadrati.
Passaggio 2: adattare il modello di regressione lazo e scegliere un valore per λ.
Una volta determinato che la regressione lazo è appropriata, possiamo adattare il modello (utilizzando linguaggi di programmazione popolari come R o Python) utilizzando il valore ottimale per λ.
Per determinare il valore ottimale per λ, possiamo adattare più modelli utilizzando valori diversi per λ e scegliere λ come valore che produce il test MSE più basso.
Passaggio 3: confrontare la regressione con lazo con la regressione di cresta e con la regressione dei minimi quadrati ordinari.
Infine, possiamo confrontare il nostro modello di regressione lazo con un modello di regressione ridge e un modello di regressione dei minimi quadrati per determinare quale modello produce il test MSE più basso utilizzando la convalida incrociata k-fold.
A seconda della relazione tra le variabili predittive e la variabile di risposta, è del tutto possibile che uno di questi tre modelli superi gli altri in scenari diversi.
Regressione lazo in R e Python
I seguenti tutorial spiegano come eseguire la regressione lazo in R e Python:
Regressione lazo in R (passo dopo passo)
Regressione lazo in Python (passo dopo passo)
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più