Come eseguire una regressione lineare semplice in r (passo dopo passo)
La regressione lineare semplice è una tecnica che possiamo utilizzare per comprendere la relazione tra una singola variabile esplicativa e una singola variabile di risposta .
In poche parole, questa tecnica trova la linea che meglio “si adatta” ai dati e assume la seguente forma:
ŷ = b 0 + b 1 x
Oro:
- ŷ : il valore di risposta stimato
- b 0 : L’origine della retta di regressione
- b 1 : La pendenza della retta di regressione
Questa equazione può aiutarci a comprendere la relazione tra la variabile esplicativa e la variabile di risposta e (supponendo che sia statisticamente significativa) può essere utilizzata per prevedere il valore di una variabile di risposta dato il valore della variabile esplicativa.
Questo tutorial fornisce una spiegazione passo passo su come eseguire una regressione lineare semplice in R.
Passaggio 1: caricare i dati
Per questo esempio, creeremo un set di dati falso contenente le seguenti due variabili per 15 studenti:
- Numero totale di ore studiate per determinati esami
- Risultato dell’esame
Cercheremo di adattare un semplice modello di regressione lineare utilizzando le ore come variabile esplicativa e i risultati dell’esame come variabile di risposta.
Il codice seguente mostra come creare questo set di dati falso in R:
#create dataset df <- data.frame(hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #view first six rows of dataset head(df) hours score 1 1 64 2 2 66 3 4 76 4 5 73 5 5 74 6 6 81 #attach dataset to make it more convenient to work with attach(df)
Passaggio 2: visualizzare i dati
Prima di adattare un semplice modello di regressione lineare, dobbiamo prima visualizzare i dati per comprenderli.
Innanzitutto, vogliamo assicurarci che la relazione tra ore e punteggio sia approssimativamente lineare, poiché si tratta di un enorme presupposto di base di una semplice regressione lineare. Possiamo creare un semplice grafico a dispersione per visualizzare la relazione tra le due variabili:
scatter.smooth(hours, score, main=' Hours studied vs. Exam Score ')
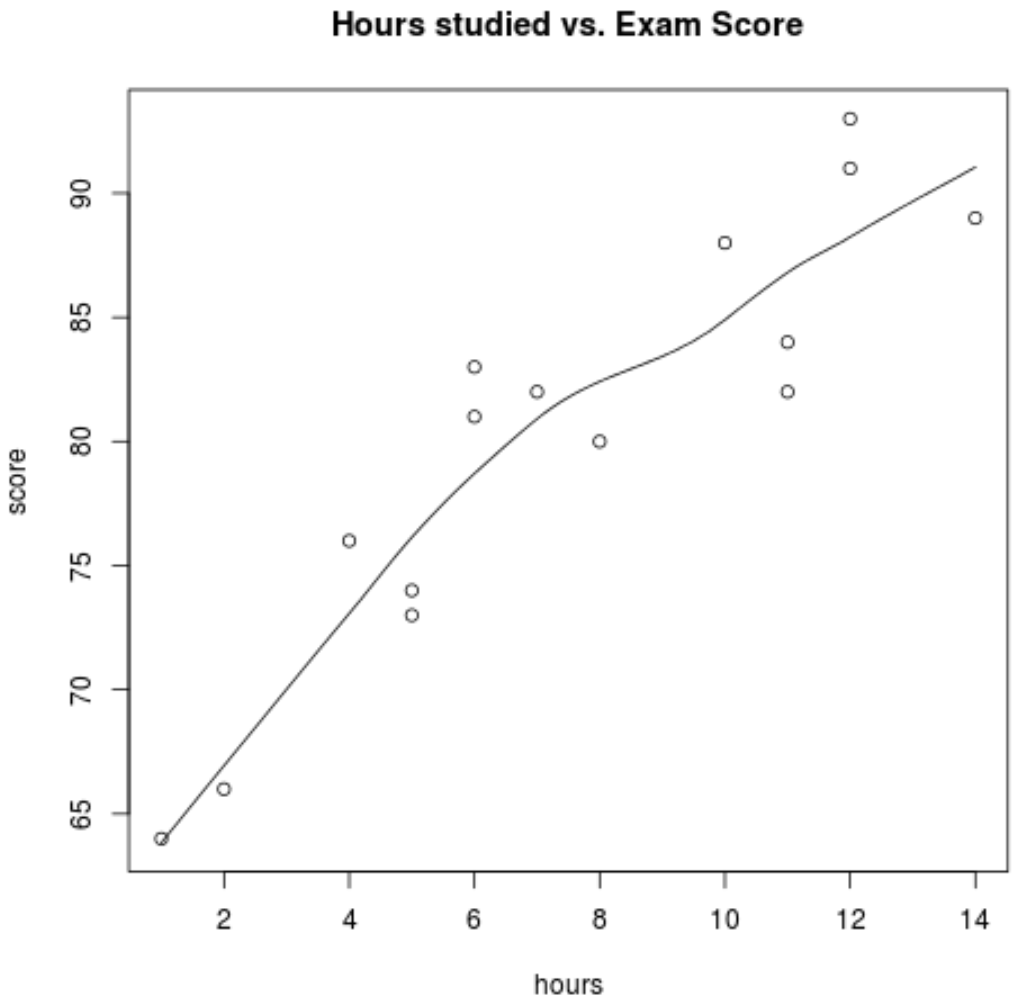
Dal grafico possiamo vedere che la relazione appare lineare. All’aumentare del numero di ore , anche il punteggio tende ad aumentare in modo lineare.
Quindi possiamo creare un boxplot per visualizzare la distribuzione dei risultati dell’esame e verificare la presenza di valori anomali . Per impostazione predefinita, R definisce un’osservazione come valore anomalo se è 1,5 volte l’intervallo interquartile al di sopra del terzo quartile (Q3) o 1,5 volte l’intervallo interquartile al di sotto del primo quartile (Q1).
Se un’osservazione è anomala, nel boxplot apparirà un piccolo cerchio:
boxplot(score)
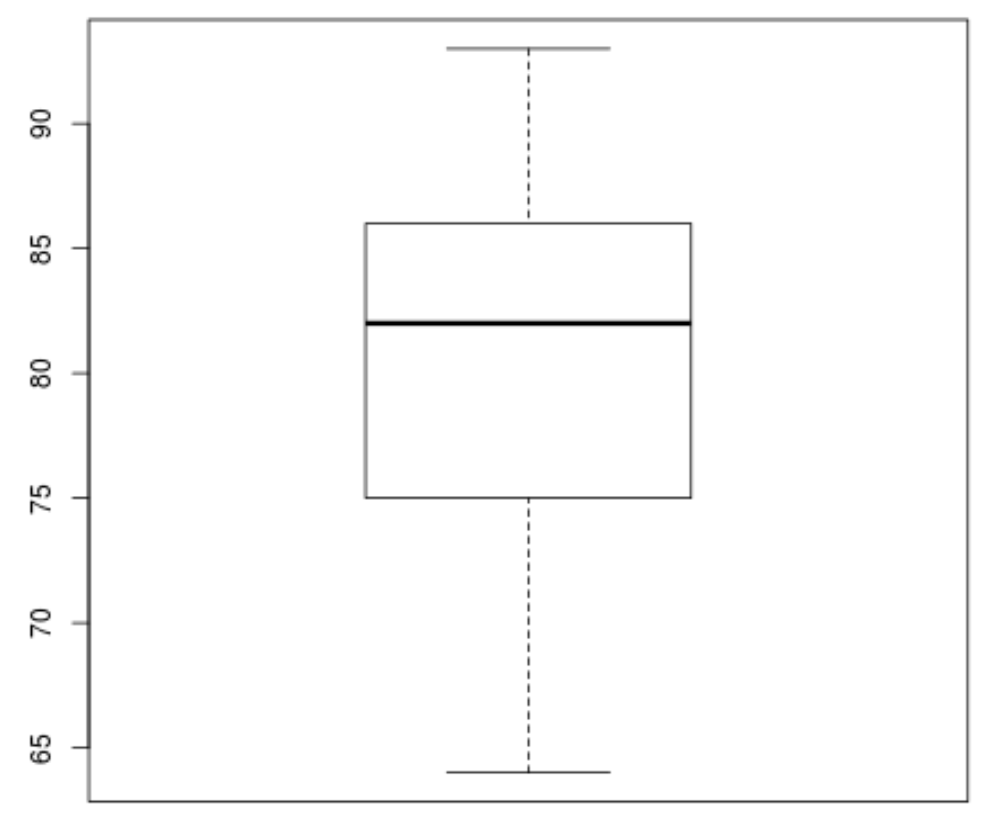
Non ci sono piccoli cerchi nel boxplot, il che significa che non ci sono valori anomali nel nostro set di dati.
Passaggio 3: eseguire una regressione lineare semplice
Una volta confermato che la relazione tra le nostre variabili è lineare e non ci sono valori anomali, possiamo procedere con l’adattamento di un semplice modello di regressione lineare utilizzando le ore come variabile esplicativa e il punteggio come variabile di risposta:
#fit simple linear regression model model <- lm(score~hours) #view model summary summary(model) Call: lm(formula = score ~ hours) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
Dal riepilogo del modello, possiamo vedere che l’equazione di regressione adattata è:
Punteggio = 65.334 + 1.982*(ore)
Ciò significa che ogni ora aggiuntiva studiata è associata a un aumento medio del punteggio dell’esame di 1.982 punti. E il valore originale di 65.334 ci dice il punteggio medio previsto per l’esame per uno studente che studia per zero ore.
Possiamo anche utilizzare questa equazione per trovare il punteggio atteso dell’esame in base al numero di ore di studio di uno studente. Ad esempio, uno studente che studia per 10 ore dovrebbe ottenere un punteggio d’esame di 85,15 :
Punteggio = 65,334 + 1,982*(10) = 85,15
Ecco come interpretare il resto del riepilogo del modello:
- Pr(>|t|): Questo è il valore p associato ai coefficienti del modello. Poiché il valore p delle ore (2,25e-06) è significativamente inferiore a 0,05, possiamo affermare che esiste un’associazione statisticamente significativa tra ore e punteggio .
- R quadrato multiplo: questo numero ci dice che la percentuale di variazione nei punteggi degli esami può essere spiegata dal numero di ore studiate. In generale, maggiore è il valore R quadrato di un modello di regressione, migliore è la capacità delle variabili esplicative di predire il valore della variabile di risposta. In questo caso, l’83,1% della variazione dei punteggi è spiegabile con le ore studiate.
- Errore standard residuo: è la distanza media tra i valori osservati e la retta di regressione. Più basso è questo valore, più una retta di regressione riesce a corrispondere ai dati osservati. In questo caso, il punteggio medio osservato all’esame si discosta di 3.641 punti dal punteggio previsto dalla retta di regressione.
- Statistica F e valore p: la statistica F ( 63,91 ) e il corrispondente valore p ( 2,253e-06 ) ci dicono il significato complessivo del modello di regressione, ovvero se le variabili esplicative nel modello sono utili per spiegare la variazione . nella variabile di risposta. Poiché il valore p in questo esempio è inferiore a 0,05, il nostro modello è statisticamente significativo e le ore sono considerate utili per spiegare la variazione del punteggio .
Passaggio 4: creare grafici residui
Dopo aver adattato il modello di regressione lineare semplice ai dati, il passaggio finale consiste nel creare grafici dei residui.
Uno dei presupposti chiave della regressione lineare è che i residui di un modello di regressione siano distribuiti approssimativamente normalmente e siano omoschedastici a ciascun livello della variabile esplicativa. Se queste ipotesi non vengono soddisfatte, i risultati del nostro modello di regressione potrebbero essere fuorvianti o inaffidabili.
Per verificare che queste ipotesi siano soddisfatte, possiamo creare i seguenti grafici residui:
Grafico dei residui rispetto ai valori adattati: questo grafico è utile per confermare l’omoschedasticità. L’asse x mostra i valori adattati e l’asse y mostra i residui. Finché i residui appaiono distribuiti in modo casuale e uniforme in tutto il grafico attorno al valore zero, possiamo supporre che l’omoschedasticità non sia violata:
#define residuals res <- resid(model) #produce residual vs. fitted plot plot(fitted(model), res) #add a horizontal line at 0 abline(0,0)
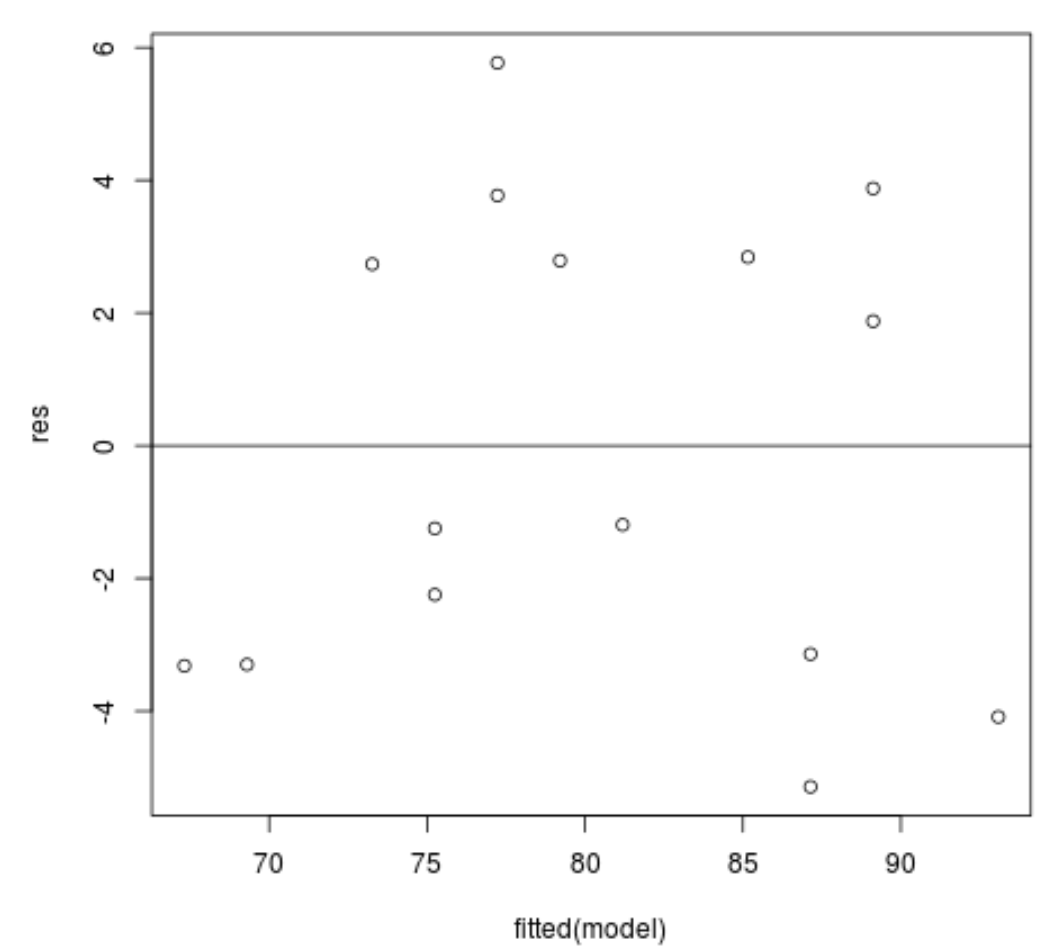
I residui sembrano essere sparsi in modo casuale attorno allo zero e non mostrano alcuno schema evidente, quindi questa ipotesi è soddisfatta.
Grafico QQ: questo grafico è utile per determinare se i residui seguono una distribuzione normale. Se i valori dei dati nel grafico seguono una linea approssimativamente retta con un angolo di 45 gradi, i dati vengono distribuiti normalmente:
#create QQ plot for residuals qqnorm(res) #add a straight diagonal line to the plot qqline(res)
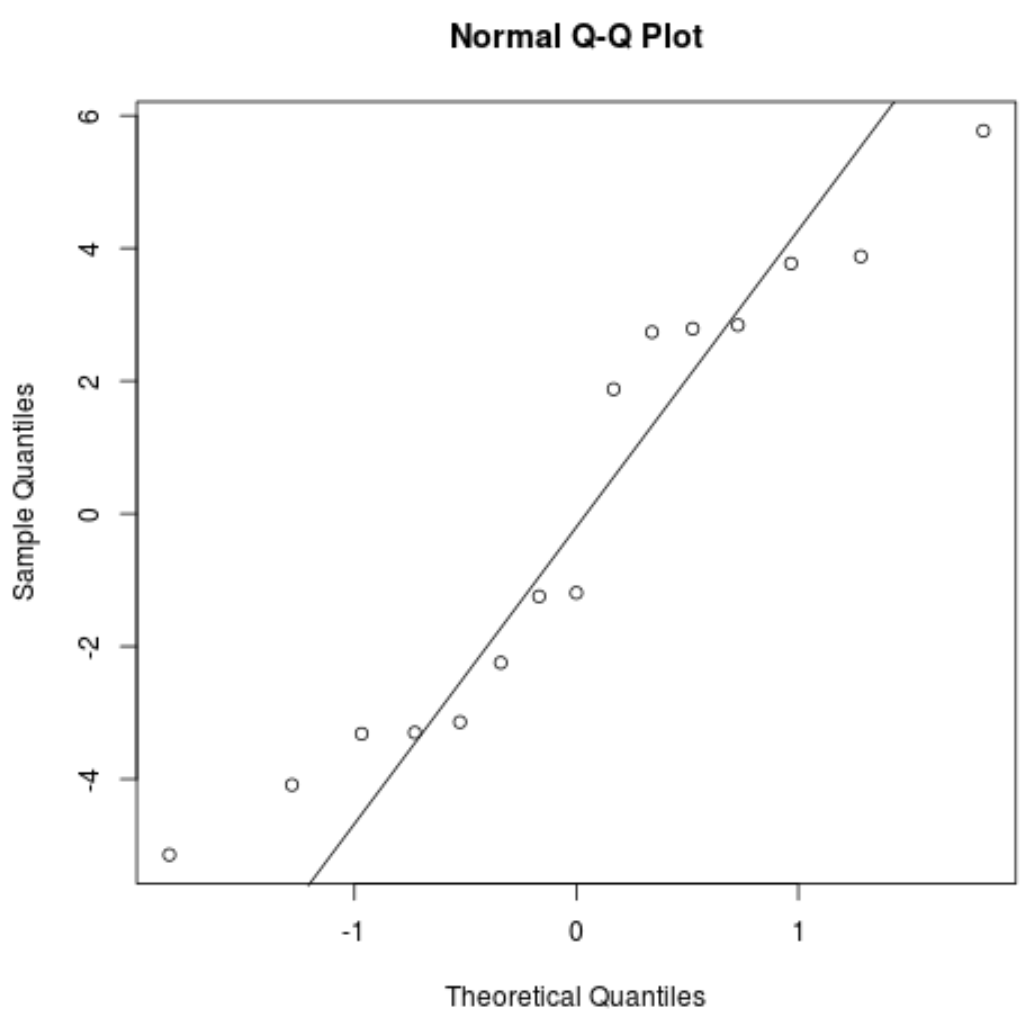
I residui si discostano leggermente dalla linea dei 45 gradi, ma non abbastanza da destare seria preoccupazione. Possiamo supporre che il presupposto di normalità sia soddisfatto.
Poiché i residui sono normalmente distribuiti e omoschedastici, abbiamo verificato che le ipotesi del modello di regressione lineare semplice siano soddisfatte. Pertanto, l’output del nostro modello è affidabile.
Il codice R completo utilizzato in questo tutorial può essere trovato qui .
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più