Regressione o classificazione: qual è la differenza?
Gli algoritmi di machine learning possono essere suddivisi in due tipologie distinte: algoritmi di apprendimento supervisionato e non supervisionato .

Gli algoritmi di apprendimento supervisionato possono essere classificati in due tipologie:
1. Regressione: la variabile di risposta è continua.
Ad esempio, la variabile di risposta potrebbe essere:
- Peso
- Altezza
- Prezzo
- Tempo
- Unità totali
In ogni caso, un modello di regressione cerca di prevedere una quantità continua.
Esempio di regressione:
Supponiamo di avere un set di dati contenente tre variabili per 100 case diverse: metratura, numero di bagni e prezzo di vendita.
Potremmo adattare un modello di regressione che utilizza la metratura e il numero di bagni come variabili esplicative e il prezzo di vendita come variabile di risposta.
Potremmo quindi utilizzare questo modello per prevedere il prezzo di vendita di una casa, in base alla metratura e al numero di bagni.
Questo è un esempio di modello di regressione perché la variabile di risposta (prezzo di vendita) è continua.
Il modo più comune per misurare l’accuratezza di un modello di regressione è calcolare l’errore quadratico medio (RMSE), una metrica che ci dice quanto distano, in media, i nostri valori previsti dai valori osservati in un modello. Viene calcolato come segue:
RMSE = √ Σ(P i – O i ) 2 / n
Oro:
- Σ è un simbolo di fantasia che significa “somma”
- Pi è il valore previsto per l’ i-esima osservazione
- O i è il valore osservato per l’ i-esima osservazione
- n è la dimensione del campione
Più piccolo è l’RMSE, migliore è la capacità del modello di regressione di adattare i dati.
2. Classificazione: la variabile di risposta è categoriale.
Ad esempio, la variabile di risposta potrebbe assumere i seguenti valori:
- Maschio o femmina
- Riuscire o fallire
- Basso, medio o alto
In ogni caso, un modello di classificazione cerca di prevedere un’etichetta di classe.
Esempio di classificazione:
Supponiamo di avere un set di dati contenente tre variabili per 100 diversi giocatori di basket universitari: media punti per partita, livello di divisione e se sono stati arruolati o meno nella NBA.
Potremmo adattare un modello di classificazione che utilizzi la media dei punti per partita e per livello di divisione come variabili esplicative e “redatta” come variabile di risposta.
Potremmo quindi utilizzare questo modello per prevedere se un determinato giocatore verrà scelto o meno nella NBA in base alla media dei punti per partita e al livello di divisione.
Questo è un esempio di modello di classificazione perché la variabile di risposta (“scritto”) è categoriale. In altre parole, può assumere valori solo in due diverse categorie: “Scritto” o “Non redatto”.
Il modo più comune per misurare l’accuratezza di un modello di classificazione è semplicemente calcolare la percentuale di classificazioni corrette effettuate dal modello:
Precisione = classificazioni di correzione/numero totale di tentativi di classificazione * 100%
Ad esempio, se un modello identifica correttamente se un giocatore verrà scelto o meno nella NBA 88 volte su 100 possibili, allora la precisione del modello è:
Precisione = (88/100) * 100% = 88%
Maggiore è la precisione, migliore è la capacità del modello di classificazione di prevedere i risultati.
Somiglianze tra regressione e classificazione
Gli algoritmi di regressione e classificazione sono simili nei seguenti modi:
- Entrambi sono algoritmi di apprendimento supervisionato, ovvero implicano entrambi una variabile di risposta.
- Entrambi utilizzano una o più variabili esplicative per creare modelli per prevedere una risposta.
- Entrambi possono essere utilizzati per comprendere come i cambiamenti nei valori delle variabili esplicative influenzano i valori di una variabile di risposta.
Differenze tra regressione e classificazione
Gli algoritmi di regressione e classificazione differiscono nei seguenti modi:
- Gli algoritmi di regressione cercano di prevedere una quantità continua e gli algoritmi di classificazione cercano di prevedere un’etichetta di classe.
- Il modo in cui misuriamo l’accuratezza dei modelli di regressione e di classificazione è diverso.
Conversione della regressione in classificazione
Va notato che un problema di regressione può essere convertito in un problema di classificazione semplicemente discretizzando la variabile di risposta in compartimenti.
Ad esempio, supponiamo di avere un set di dati che contiene tre variabili: metratura, numero di bagni e prezzo di vendita.
Potremmo costruire un modello di regressione utilizzando la metratura e il numero di bagni per prevedere i prezzi di vendita.
Potremmo però discretizzare il prezzo di vendita in tre diverse classi:
- $ 80.000 – $ 160.000: “Prezzo di vendita basso”
- $ 161.000 – $ 240.000: “Prezzo di vendita medio”
- $ 241.000 – $ 320.000: “Prezzo di vendita elevato”
Potremmo quindi utilizzare la metratura e il numero di bagni come variabili esplicative per prevedere in quale classe (bassa, media o alta) rientrerà il prezzo di vendita di una determinata casa.
Questo sarebbe un esempio di modello di classificazione poiché stiamo cercando di collocare ogni casa in una classe.
Riepilogo
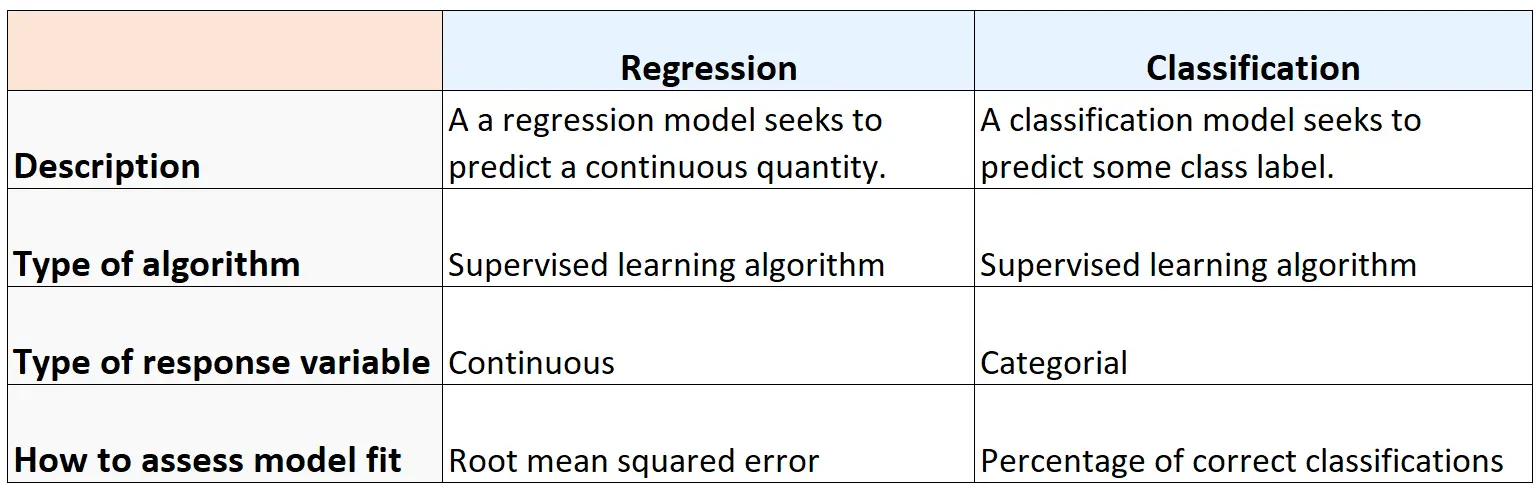
La tabella seguente riassume le somiglianze e le differenze tra gli algoritmi di regressione e di classificazione:
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più