Come eseguire il ridimensionamento multidimensionale in python
In statistica, il ridimensionamento multidimensionale è un modo per visualizzare la somiglianza delle osservazioni in un set di dati in uno spazio cartesiano astratto (solitamente spazio 2D).
Il modo più semplice per eseguire il ridimensionamento multidimensionale in Python è utilizzare la funzione MDS() del sottomodulo sklearn.manifold .
L’esempio seguente mostra come utilizzare questa funzione nella pratica.
Esempio: scala multidimensionale in Python
Supponiamo di avere il seguente DataFrame panda che contiene informazioni su vari giocatori di basket:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Possiamo utilizzare il codice seguente per eseguire il ridimensionamento multidimensionale con la funzione MDS() del modulo sklearn.manifold :
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
Ogni riga del DataFrame originale è stata ridotta a una coordinata (x, y).
Possiamo usare il seguente codice per visualizzare queste coordinate nello spazio 2D:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
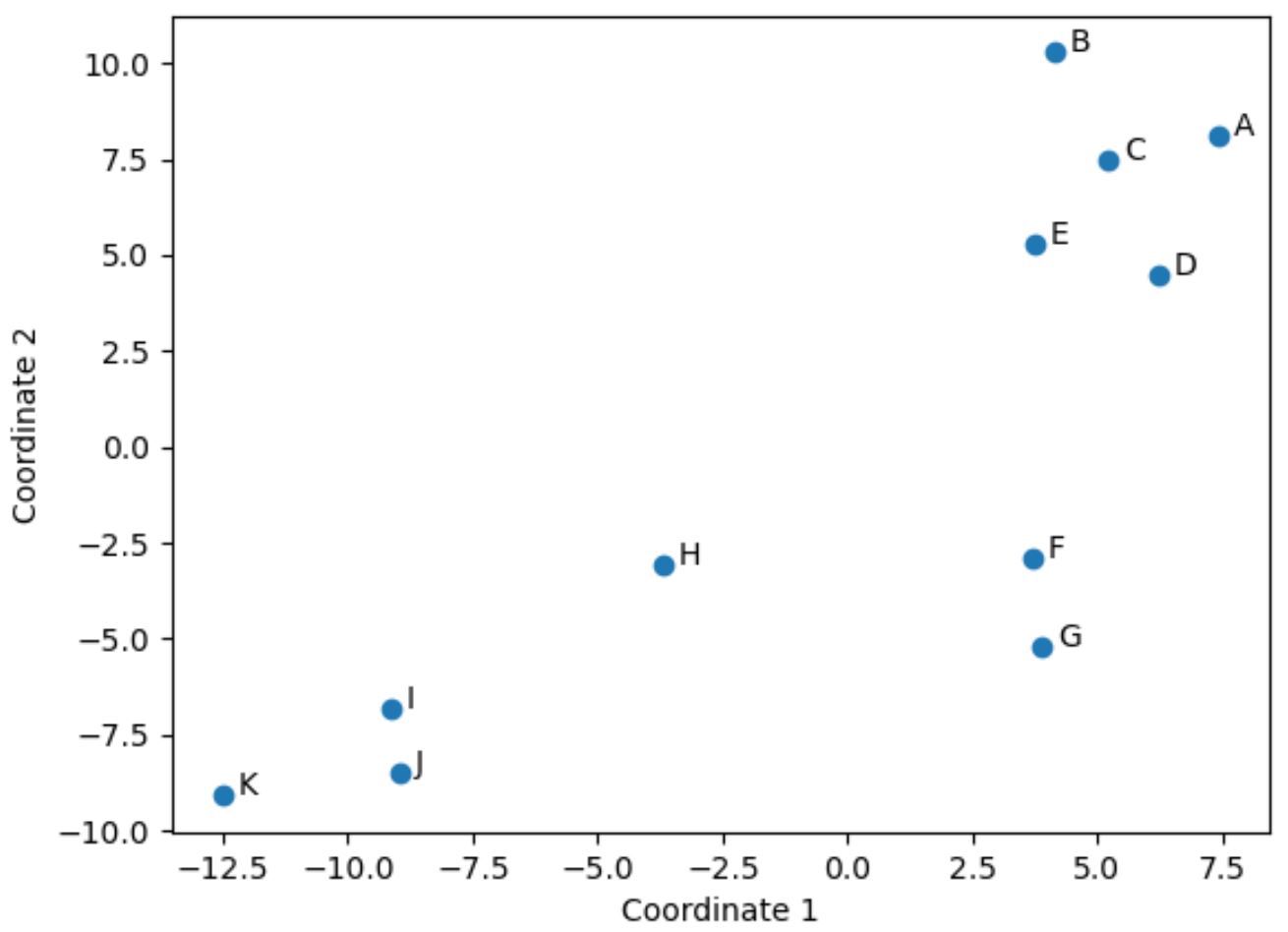
I giocatori nel DataFrame originale che hanno valori simili nelle quattro colonne originali (punti, assist, stoppate e rimbalzi) sono vicini tra loro nella trama.
Ad esempio, i giocatori F e G sono vicini l’uno all’altro. Ecco i loro valori dal DataFrame originale:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
I loro valori per punti, assist, stoppate e rimbalzi sono tutti abbastanza simili, il che spiega perché sono così vicini tra loro nella trama 2D.
Al contrario, consideriamo i giocatori B e K che sono distanti nella trama.
Se facciamo riferimento ai loro valori nel DataFrame originale, possiamo vedere che sono abbastanza diversi:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
Quindi la trama 2D è un buon modo per visualizzare quanto simile è ogni giocatore in tutte le variabili nel DataFframe.
I giocatori con statistiche simili sono raggruppati vicini mentre i giocatori con statistiche molto diverse sono più distanti tra loro nella trama.
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in Python:
Come normalizzare i dati in Python
Come rimuovere i valori anomali in Python
Come testare la normalità in Python
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più