Come eseguire il ridimensionamento multidimensionale in r (con esempio)
In statistica, il ridimensionamento multidimensionale è un modo per visualizzare la somiglianza delle osservazioni in un set di dati in uno spazio cartesiano astratto (solitamente spazio 2D).
Il modo più semplice per eseguire il ridimensionamento multidimensionale in R è utilizzare la funzione cmdscale() incorporata, che utilizza la seguente sintassi di base:
cmdscale(d, eig = FALSO, k = 2, …)
Oro:
- d : una matrice di distanza generalmente calcolata dalla funzione dist() .
- eig : se restituire o meno gli autovalori.
- k : il numero di dimensioni in cui visualizzare i dati. Il valore predefinito è 2 .
L’esempio seguente mostra come utilizzare questa funzione nella pratica.
Esempio: ridimensionamento multidimensionale in R
Supponiamo di avere il seguente frame di dati in R che contiene informazioni su vari giocatori di basket:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Possiamo utilizzare il seguente codice per eseguire il ridimensionamento multidimensionale con la funzione cmdscale() e visualizzare i risultati nello spazio 2D:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
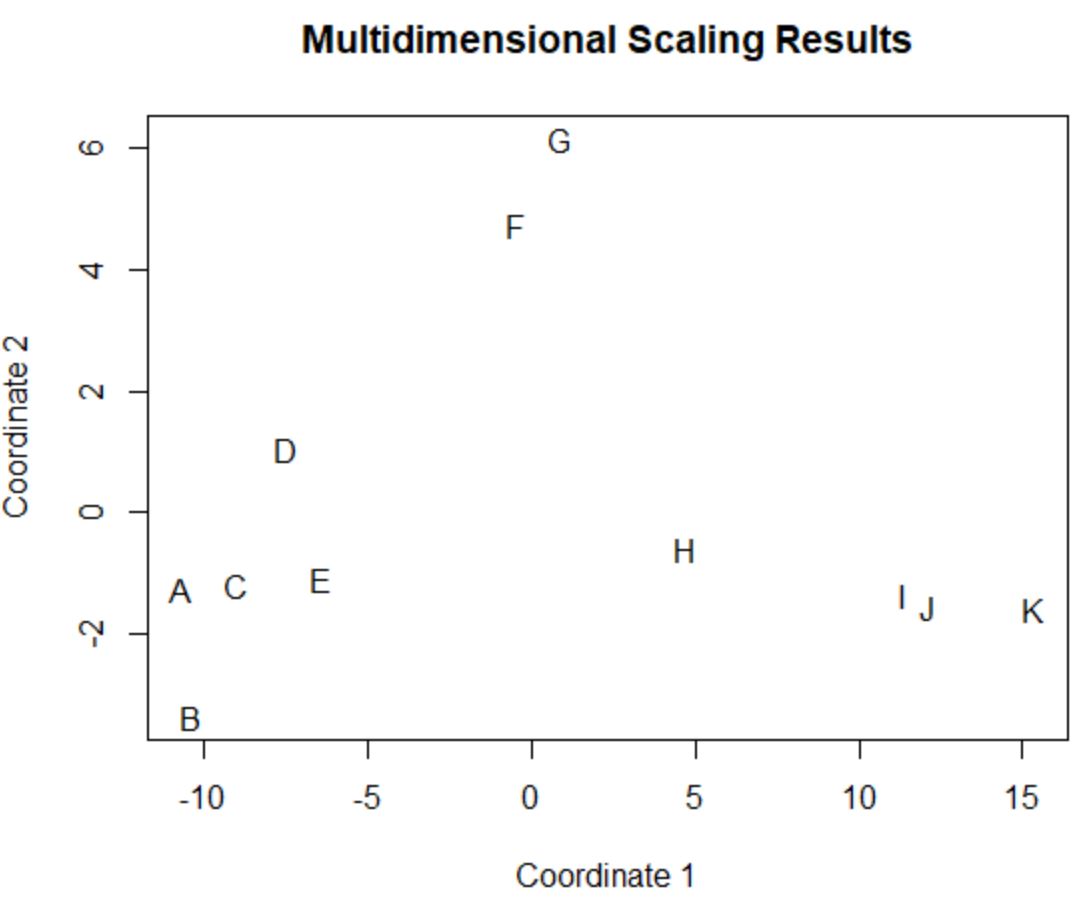
I giocatori nel frame di dati originale che hanno valori simili nelle quattro colonne originali (punti, assist, stoppate e rimbalzi) sono vicini tra loro nella trama.
Ad esempio, i giocatori A e C sono vicini l’uno all’altro. Ecco i loro valori dal frame di dati originale:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
I loro valori per punti, assist, stoppate e rimbalzi sono tutti abbastanza simili, il che spiega perché sono così vicini tra loro nella trama 2D.
Al contrario, consideriamo i giocatori B e K che sono distanti nella trama.
Se facciamo riferimento ai loro valori nei dati originali, possiamo vedere che sono abbastanza diversi:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
Quindi la trama 2D è un buon modo per visualizzare quanto ciascun giocatore sia simile in tutte le variabili nel frame di dati.
I giocatori con statistiche simili sono raggruppati vicini mentre i giocatori con statistiche molto diverse sono più distanti tra loro nella trama.
Tieni presente che puoi anche estrarre le coordinate esatte (x, y) di ciascun giocatore nella trama digitando fit , che è il nome della variabile in cui abbiamo memorizzato i risultati della funzione cmdscale() :
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
Risorse addizionali
I seguenti tutorial spiegano come eseguire altre attività comuni in R:
Come normalizzare i dati in R
Come creare un data center in R
Come rimuovere gli outlier in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più