Selezione casuale o assegnazione casuale
La selezione casuale e l’assegnazione casuale sono due tecniche statistiche comunemente utilizzate, ma spesso confuse.
La selezione casuale si riferisce al processo di selezione casuale degli individui da una popolazione da coinvolgere in uno studio.
L’assegnazione casuale si riferisce al processo di assegnazione casuale degli individui partecipanti a uno studio a un gruppo di trattamento o a un gruppo di controllo.
Puoi pensare alla selezione casuale come al processo che usi per “inserire” gli individui in uno studio e puoi pensare all’assegnazione casuale come ciò che “fai” con quegli individui una volta che sono stati selezionati per far parte dello studio.
L’importanza della selezione casuale e dell’assegnazione casuale
Quando uno studio utilizza la selezione casuale , seleziona gli individui da una popolazione utilizzando un processo casuale. Ad esempio, se una popolazione ha 1.000 individui, potremmo utilizzare un computer per selezionare casualmente 100 di quegli individui da un database. Ciò significa che ogni individuo ha la stessa probabilità di essere selezionato per far parte dello studio, aumentando le possibilità di ottenere un campione rappresentativo , con caratteristiche simili alla popolazione generale.
Utilizzando un campione rappresentativo nel nostro studio, siamo in grado di generalizzare i risultati del nostro studio alla popolazione. In termini statistici, questo si chiama validità esterna : è valido esternalizzare i nostri risultati alla popolazione generale.
Quando uno studio utilizza l’assegnazione casuale , assegna casualmente gli individui a un gruppo di trattamento o a un gruppo di controllo. Ad esempio, se in uno studio abbiamo 100 individui, potremmo utilizzare un generatore di numeri casuali per assegnare casualmente 50 individui a un gruppo di controllo e 50 individui a un gruppo di trattamento.
Utilizzando l’assegnazione casuale, aumentiamo la possibilità che i due gruppi abbiano caratteristiche più o meno simili, il che significa che eventuali differenze osservate tra i due gruppi possono essere attribuite al trattamento. Ciò significa che lo studio ha validità interna : è valido per attribuire eventuali differenze tra i gruppi al trattamento stesso, in contrapposizione alle differenze tra gli individui dei gruppi.
Esempi di selezione casuale e assegnazione casuale
È possibile che uno studio utilizzi sia la selezione casuale che l’assegnazione casuale, oppure solo una di queste tecniche, oppure nessuna delle due. Uno studio efficace è quello che utilizza entrambe le tecniche.
Gli esempi seguenti mostrano come uno studio potrebbe utilizzare entrambe, una o nessuna di queste tecniche e gli effetti risultanti.
Esempio 1: utilizzo sia della selezione casuale che dell’assegnazione casuale
Studio: I ricercatori vogliono sapere se una nuova dieta comporta una maggiore perdita di peso rispetto a una dieta standard in una determinata comunità di 10.000 persone. Reclutano 100 persone per partecipare allo studio utilizzando un computer per selezionare casualmente 100 nomi da un database. Una volta ottenuti tutti i 100 individui, usano nuovamente un computer per assegnare casualmente 50 individui a un gruppo di controllo (ad esempio attenendosi alla loro dieta standard) e 50 individui a un gruppo di trattamento (ad esempio seguendo la nuova dieta). Registrano la perdita di peso totale di ogni individuo dopo un mese.
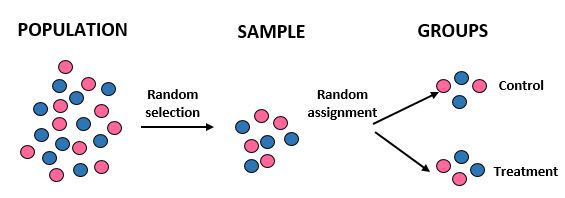
Risultati: i ricercatori hanno utilizzato la selezione casuale per ottenere il campione e l’assegnazione casuale quando hanno inserito gli individui in un gruppo di trattamento o di controllo. In questo modo, sono in grado di generalizzare i risultati dello studio all’intera popolazione e attribuire le differenze nella perdita di peso media tra i due gruppi alla nuova dieta.
Esempio 2: utilizzare solo la selezione casuale
Studio: I ricercatori vogliono sapere se una nuova dieta comporta una maggiore perdita di peso rispetto a una dieta standard in una determinata comunità di 10.000 persone. Reclutano 100 persone per partecipare allo studio utilizzando un computer per selezionare casualmente 100 nomi da un database. Tuttavia, decidono di dividere gli individui in gruppi esclusivamente in base al sesso. Le donne vengono assegnate al gruppo di controllo e gli uomini al gruppo di trattamento. Registrano la perdita di peso totale di ogni individuo dopo un mese.
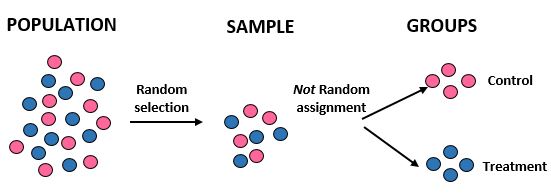
Risultati: i ricercatori hanno utilizzato la selezione casuale per ottenere il loro campione, ma non hanno utilizzato l’assegnazione casuale quando hanno inserito gli individui in un gruppo di trattamento o di controllo. Invece, hanno utilizzato un fattore specifico – il genere – per decidere a quale gruppo assegnare gli individui. In tal modo, sono in grado di generalizzare i risultati dello studio all’intera popolazione, ma non sono in grado di attribuire le differenze nella perdita di peso media tra i due gruppi alla nuova dieta. La validità interna dello studio è stata compromessa perché la differenza nella perdita di peso potrebbe in realtà essere semplicemente dovuta al genere piuttosto che alla nuova dieta.
Esempio 3: utilizzare solo l’assegnazione casuale
Studio: I ricercatori vogliono sapere se una nuova dieta comporta una maggiore perdita di peso rispetto a una dieta standard in una determinata comunità di 10.000 persone. Stanno reclutando 100 atleti maschi per partecipare allo studio. Quindi utilizzano un programma per computer per assegnare in modo casuale 50 atleti maschi a un gruppo di controllo e 50 al gruppo di trattamento. Registrano la perdita di peso totale di ogni individuo dopo un mese.
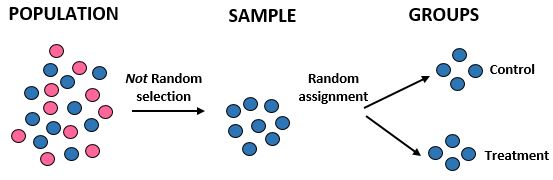
Risultati: i ricercatori non hanno utilizzato la selezione casuale per ottenere il campione poiché hanno scelto specificamente 100 atleti di sesso maschile. Per questo motivo, il loro campione non è rappresentativo della popolazione complessiva e la loro validità esterna è quindi compromessa: non saranno in grado di generalizzare i risultati dello studio alla popolazione complessiva. Tuttavia, hanno utilizzato l’assegnazione casuale, nel senso che possono attribuire qualsiasi differenza nella perdita di peso alla nuova dieta.
Esempio 4: non utilizzare nessuna delle due tecniche
Studio: I ricercatori vogliono sapere se una nuova dieta comporta una maggiore perdita di peso rispetto a una dieta standard in una determinata comunità di 10.000 persone. Stanno reclutando 50 atleti di sesso maschile e 50 atlete di sesso femminile per partecipare allo studio. Quindi assegnano tutte le atlete al gruppo di controllo e tutti gli atleti di sesso maschile al gruppo di trattamento. Registrano la perdita di peso totale di ogni individuo dopo un mese.
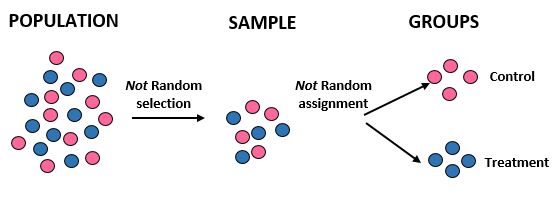
Risultati: i ricercatori non hanno utilizzato la selezione casuale per ottenere il campione poiché hanno scelto specificamente 100 atleti. Per questo motivo, il loro campione non è rappresentativo della popolazione complessiva e la loro validità esterna è quindi compromessa: non saranno in grado di generalizzare i risultati dello studio alla popolazione complessiva. Inoltre, dividono gli individui in gruppi in base al sesso anziché fare affidamento su un’assegnazione casuale, il che significa che anche la loro validità interna è compromessa: le differenze nella perdita di peso potrebbero essere dovute al sesso piuttosto che alla dieta.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più