Una guida completa al set di dati di boston in r
Il set di dati di Boston del pacchetto MASS in R contiene informazioni su vari attributi della periferia di Boston, Massachusetts.
Questo tutorial spiega come esplorare, riepilogare e visualizzare il set di dati di Boston in R.
Carica il set di dati di Boston
Prima di poter visualizzare il set di dati di Boston , dobbiamo prima caricare il pacchetto MASS :
library (MASS)
Possiamo quindi utilizzare la funzione head() per visualizzare le prime sei righe del set di dati:
#view first six rows of Boston dataset
head(Boston)
crim zn indus chas nox rm age dis rad tax ptratio black lstat
1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
medv
1 24.0
2 21.6
3 34.7
4 33.4
5 36.2
6 28.7
Per visualizzare una descrizione di ciascuna variabile nel set di dati, possiamo inserire quanto segue:
#view description of each variable in dataset
?Boston
This data frame contains the following columns:
'crime' per capita crime rate by town.
'zn' proportion of residential land zoned for lots over 25,000
sq.ft.
'industrial' proportion of non-retail business acres per town.
'chas' Charles River dummy variable (= 1 if tract bounds river; 0
otherwise).
'nox' nitrogen oxides concentration (parts per 10 million).
'rm' average number of rooms per dwelling.
'age' proportion of owner-occupied units built prior to 1940.
'dis' weighted mean of distances to five Boston employment
centers.
'rad' index of accessibility to radial highways.
'tax' full-value property-tax rate per $10,000.
'ptratio' pupil-teacher ratio by town.
'black' 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by
town.
'lstat' lower status of the population (percent).
'medv' median value of owner-occupied homes in $1000s.
Riassumere il set di dati di Boston
Possiamo utilizzare la funzione summary() per riassumere rapidamente ogni variabile nel set di dati:
#summarize Boston dataset
summary(Boston)
crim zn indus chas
Min. : 0.00632 Min. : 0.00 Min. : 0.46 Min. :0.00000
1st Q: 0.08205 1st Q: 0.00 1st Q: 5.19 1st Q: 0.00000
Median: 0.25651 Median: 0.00 Median: 9.69 Median: 0.00000
Mean: 3.61352 Mean: 11.36 Mean: 11.14 Mean: 0.06917
3rd Qu.: 3.67708 3rd Qu.: 12.50 3rd Qu.: 18.10 3rd Qu.: 0.00000
Max. :88.97620 Max. :100.00 Max. :27.74 Max. :1.00000
nox rm age dis
Min. :0.3850 Min. :3.561 Min. : 2.90 Min. : 1,130
1st Qu.: 0.4490 1st Qu.: 5.886 1st Qu.: 45.02 1st Qu.: 2.100
Median: 0.5380 Median: 6.208 Median: 77.50 Median: 3.207
Mean: 0.5547 Mean: 6.285 Mean: 68.57 Mean: 3.795
3rd Qu.: 0.6240 3rd Qu.: 6.623 3rd Qu.: 94.08 3rd Qu.: 5.188
Max. :0.8710 Max. :8,780 Max. :100.00 Max. :12,127
rad tax ptratio black
Min. : 1,000 Min. :187.0 Min. :12.60 Min. : 0.32
1st Qu.: 4,000 1st Qu.:279.0 1st Qu.:17.40 1st Qu.:375.38
Median: 5,000 Median: 330.0 Median: 19.05 Median: 391.44
Mean: 9.549 Mean: 408.2 Mean: 18.46 Mean: 356.67
3rd Qu.:24,000 3rd Qu.:666.0 3rd Qu.:20.20 3rd Qu.:396.23
Max. :24,000 Max. :711.0 Max. :22.00 Max. :396.90
lstat medv
Min. : 1.73 Min. : 5.00
1st Q: 6.95 1st Q: 17.02
Median: 11.36 Median: 21.20
Mean:12.65 Mean:22.53
3rd Qu.:16.95 3rd Qu.:25.00
Max. :37.97 Max. :50.00
Per ciascuna delle variabili numeriche possiamo vedere le seguenti informazioni:
- Min : il valore minimo.
- 1° Qu : il valore del primo quartile (25° percentile).
- Mediana : il valore mediano.
- Media : il valore medio.
- 3° Qu : Il valore del terzo quartile (75° percentile).
- Max : il valore massimo.
Possiamo usare la funzione dim() per ottenere le dimensioni del set di dati in termini di numero di righe e colonne:
#display rows and columns
sun(Boston)
[1] 506 14
Possiamo vedere che il set di dati ha 506 righe e 14 colonne.
Visualizza il set di dati di Boston
Possiamo anche creare grafici per visualizzare i valori del set di dati.
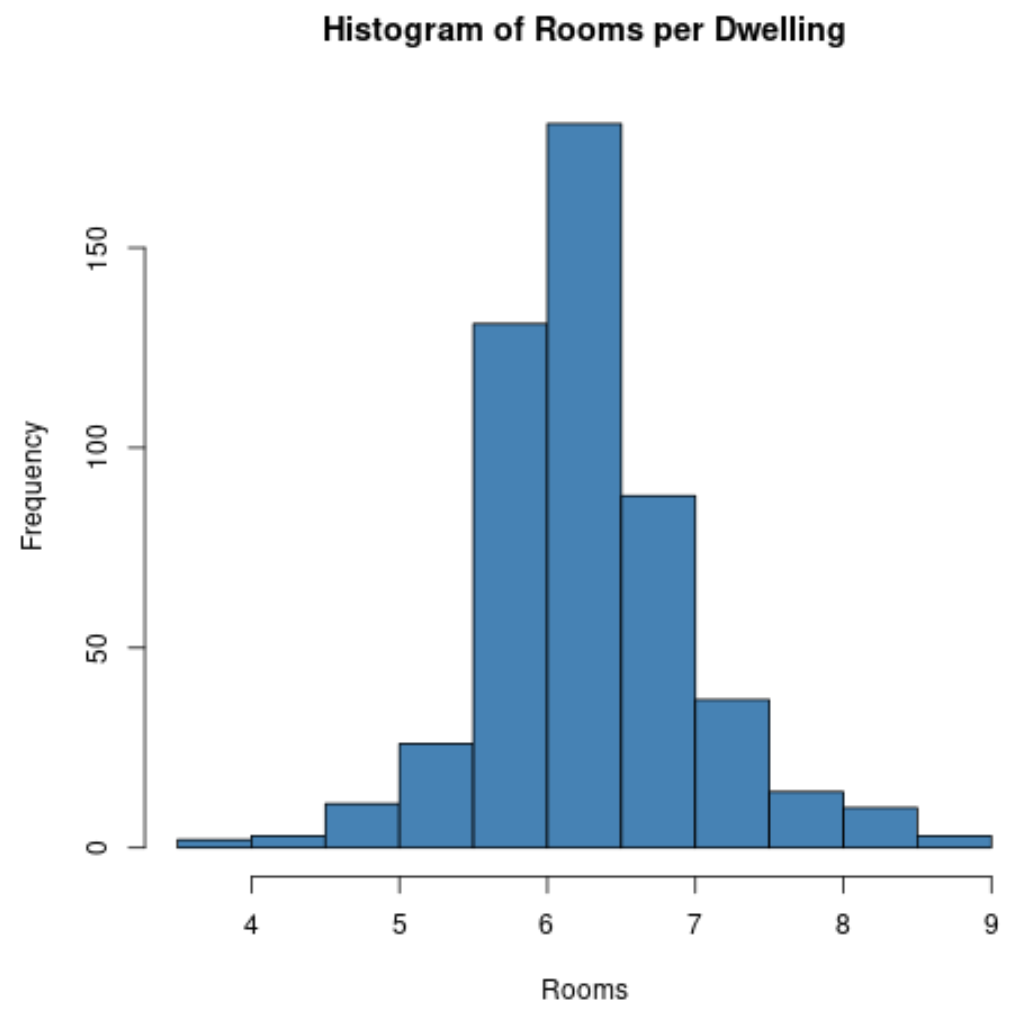
Ad esempio, possiamo utilizzare la funzione hist() per creare un istogramma dei valori di una determinata variabile:
#create histogram of values for 'rm' column
hist(Boston$rm,
col=' steelblue ',
main=' Histogram of Rooms per Dwelling ',
xlab=' Rooms ',
ylab=' Frequency ')
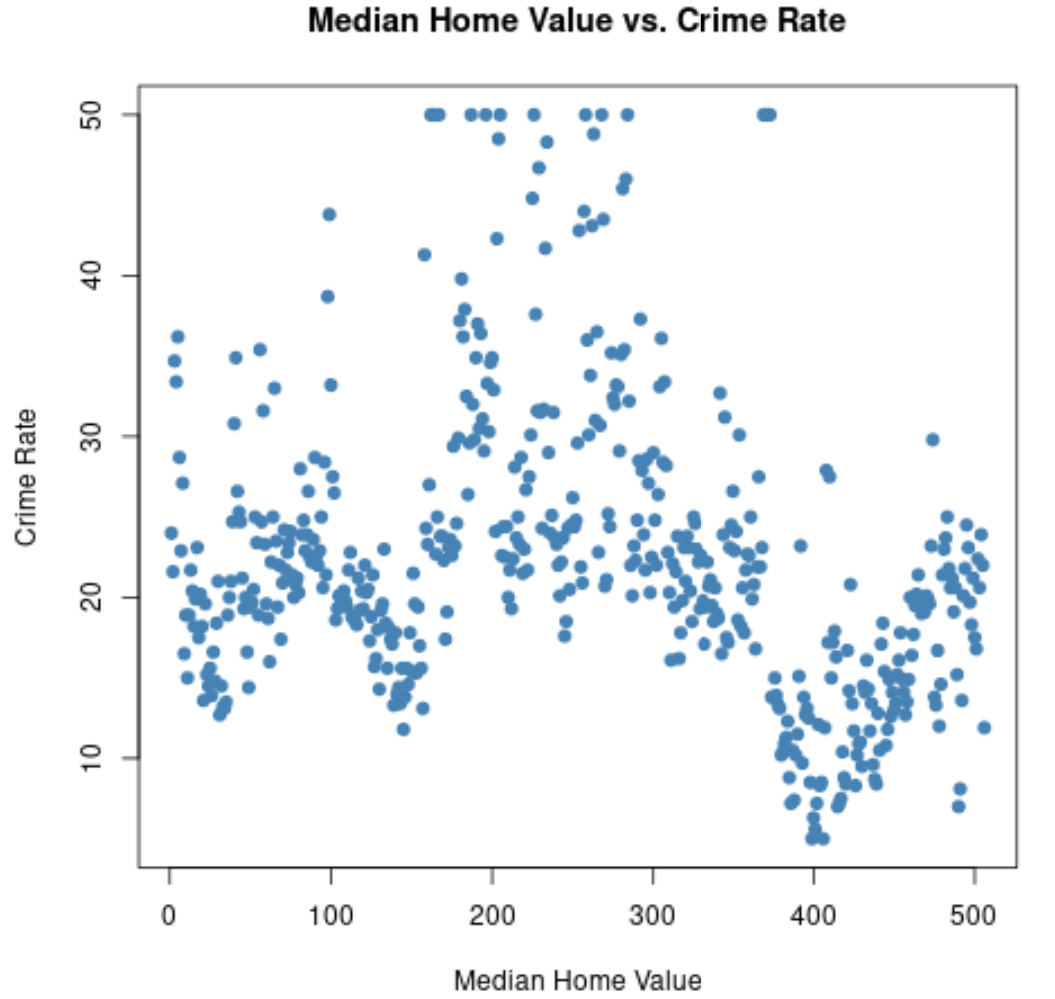
Possiamo anche usare la funzione plot() per creare un grafico a dispersione di qualsiasi combinazione di variabili a coppie:
#create scatterplot of median home value vs crime rate
plot(Boston$medv, Boston$crime,
col=' steelblue ',
main=' Median Home Value vs. Crime Rate ',
xlab=' Median Home Value ',
ylab=' Crime Rate ',
pch= 19 )
Possiamo creare un grafico a dispersione simile per visualizzare la relazione tra due variabili qualsiasi nel set di dati.
Risorse addizionali
I seguenti tutorial forniscono una guida completa ad altri set di dati popolari in R:
Una guida completa al set di dati Iris in R
Una guida completa al set di dati mtcars in R
Una guida completa al dataset dei diamanti in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più