Una guida completa al set di dati iris in r
Il set di dati dell’iride è un set di dati integrato in R che contiene misurazioni su 4 diversi attributi (in centimetri) per 50 fiori di 3 specie diverse.
Questo tutorial spiega come esplorare e riepilogare un set di dati in R, utilizzando il set di dati dell’iride come esempio.
Correlato: Una guida completa al set di dati mtcars in R
Carica il set di dati Iris
Poiché il set di dati dell’iride è un set di dati integrato in R, possiamo caricarlo utilizzando il seguente comando:
data(iris)
Possiamo dare un’occhiata alle prime sei righe del set di dati utilizzando la funzione head() :
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Riepilogare il set di dati Iris
Possiamo utilizzare la funzione summary() per riassumere rapidamente ogni variabile nel set di dati:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
Per ciascuna delle variabili numeriche possiamo vedere le seguenti informazioni:
- Min : il valore minimo.
- 1° Qu : il valore del primo quartile (25° percentile).
- Mediana : il valore mediano.
- Media : il valore medio.
- 3° Qu : Il valore del terzo quartile (75° percentile).
- Max : il valore massimo.
Per l’unica variabile categoriale nel set di dati (Specie), vediamo un conteggio della frequenza di ciascun valore:
- setosa : Questa specie è presente 50 volte.
- versicolor : questa specie si verifica 50 volte.
- virginica : Questa specie è presente 50 volte.
Possiamo usare la funzione dim() per ottenere le dimensioni del set di dati in termini di numero di righe e colonne:
#display rows and columns
dim(iris)
[1] 150 5
Possiamo vedere che il set di dati ha 150 righe e 5 colonne.
Possiamo anche usare la funzionenames () per visualizzare i nomi delle colonne del data frame:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Visualizza il set di dati Iris
Possiamo anche creare grafici per visualizzare i valori del set di dati.
Ad esempio, possiamo utilizzare la funzione hist() per creare un istogramma dei valori di una determinata variabile:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
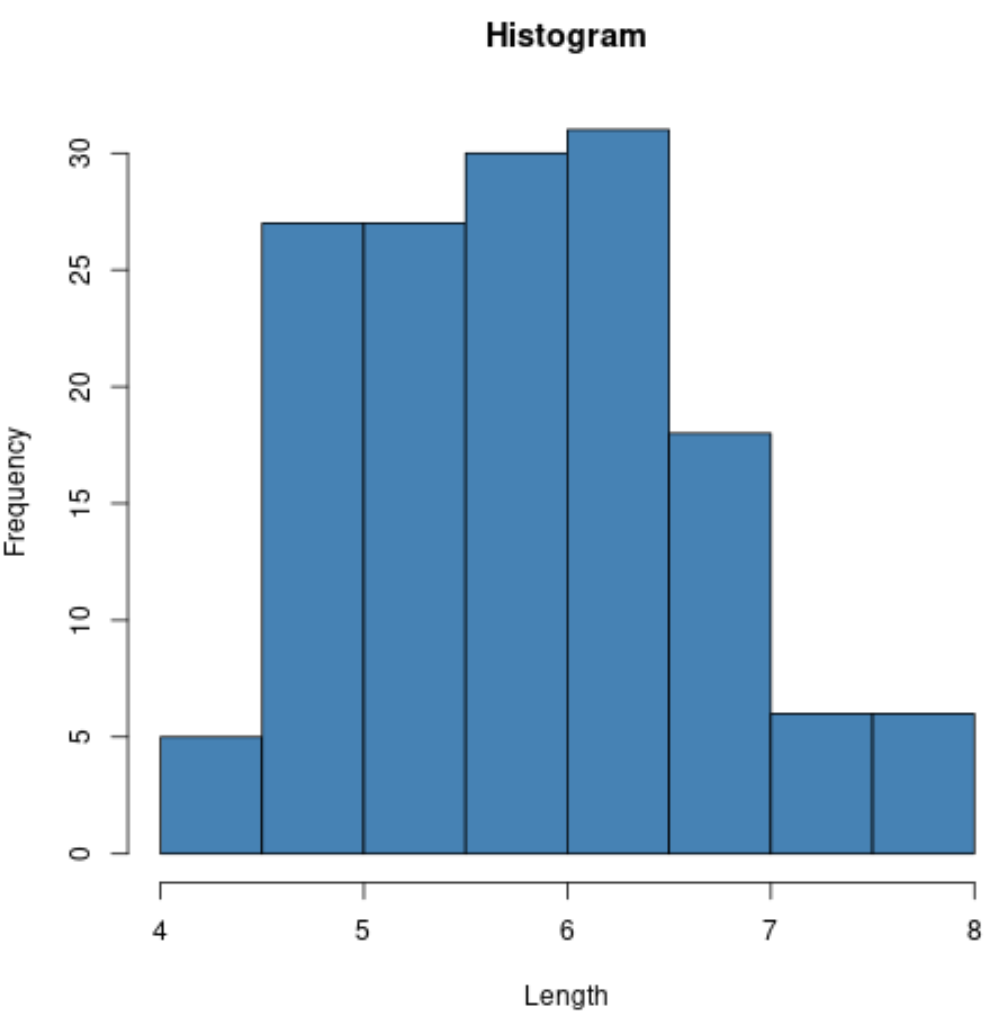
Possiamo anche usare la funzione plot() per creare un grafico a dispersione di qualsiasi combinazione di variabili a coppie:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
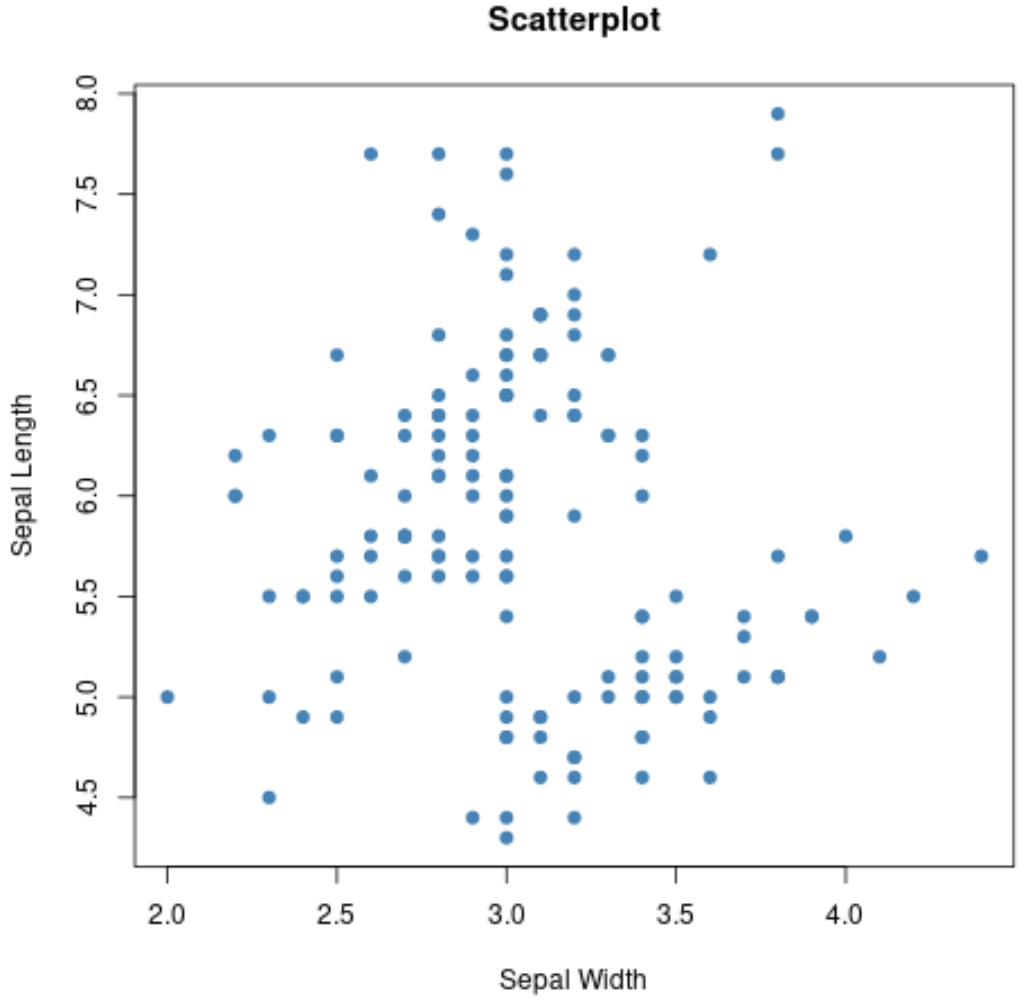
Possiamo anche usare la funzione boxplot() per creare un boxplot per gruppo:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
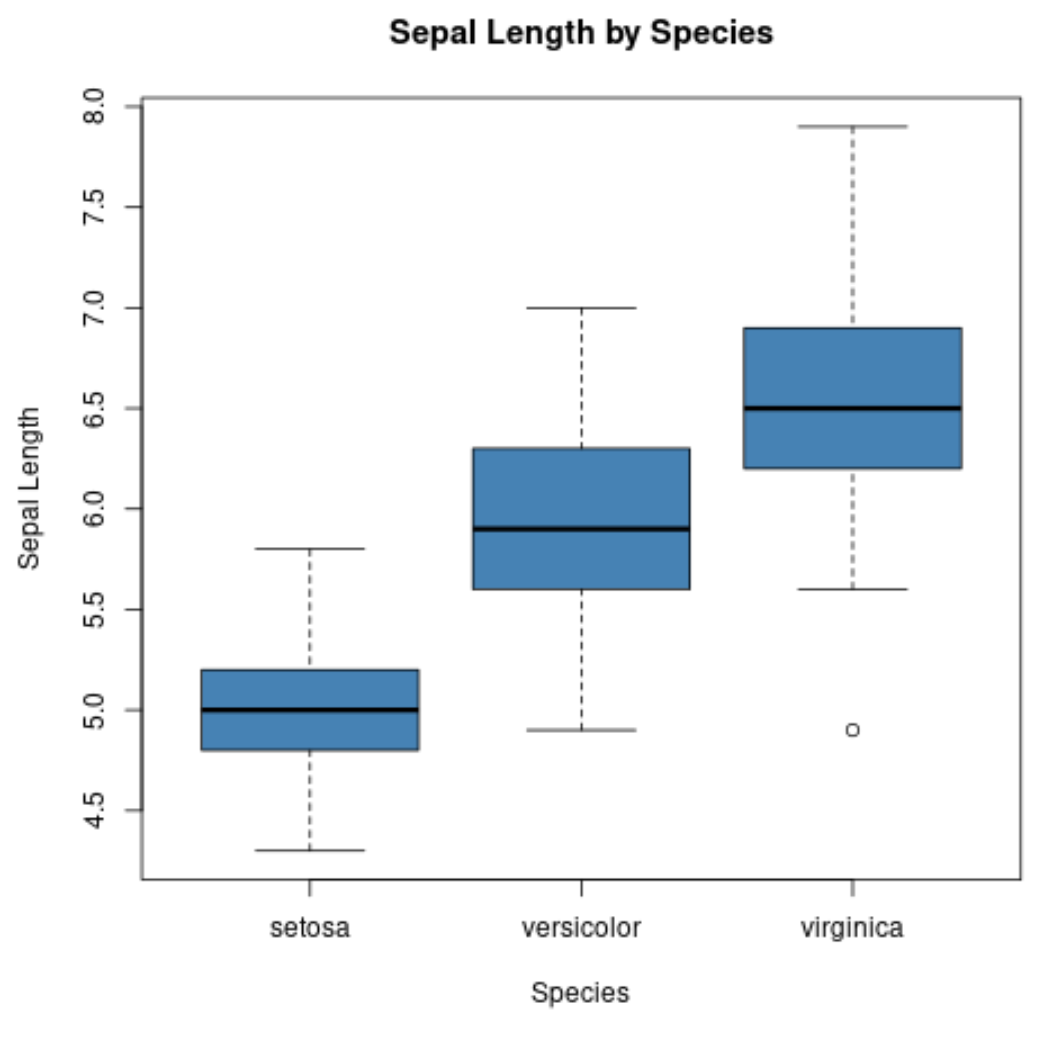
L’asse x mostra le tre specie e l’asse y mostra la distribuzione dei valori di lunghezza dei sepali per ciascuna specie.
Questo tipo di diagramma permette di vedere rapidamente che la lunghezza dei sepali tende ad essere maggiore per la specie virginica e minima per la specie setosa.
Risorse addizionali
I seguenti tutorial spiegano più in dettaglio come riepilogare i set di dati in R:
Il modo più semplice per creare tabelle di riepilogo in R
Come calcolare la sintesi di cinque numeri in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più