Validation set e test set: qual è la differenza?
Ogni volta che adattiamo un algoritmo di machine learning a un set di dati, in genere dividiamo il set di dati in tre parti:
1. Set di addestramento : utilizzato per addestrare il modello.
2. Set di validazione : utilizzato per ottimizzare i parametri del modello.
3. Set di test : utilizzato per ottenere una stima imparziale delle prestazioni del modello finale.
Il diagramma seguente fornisce una spiegazione visiva di questi tre diversi tipi di set di dati:
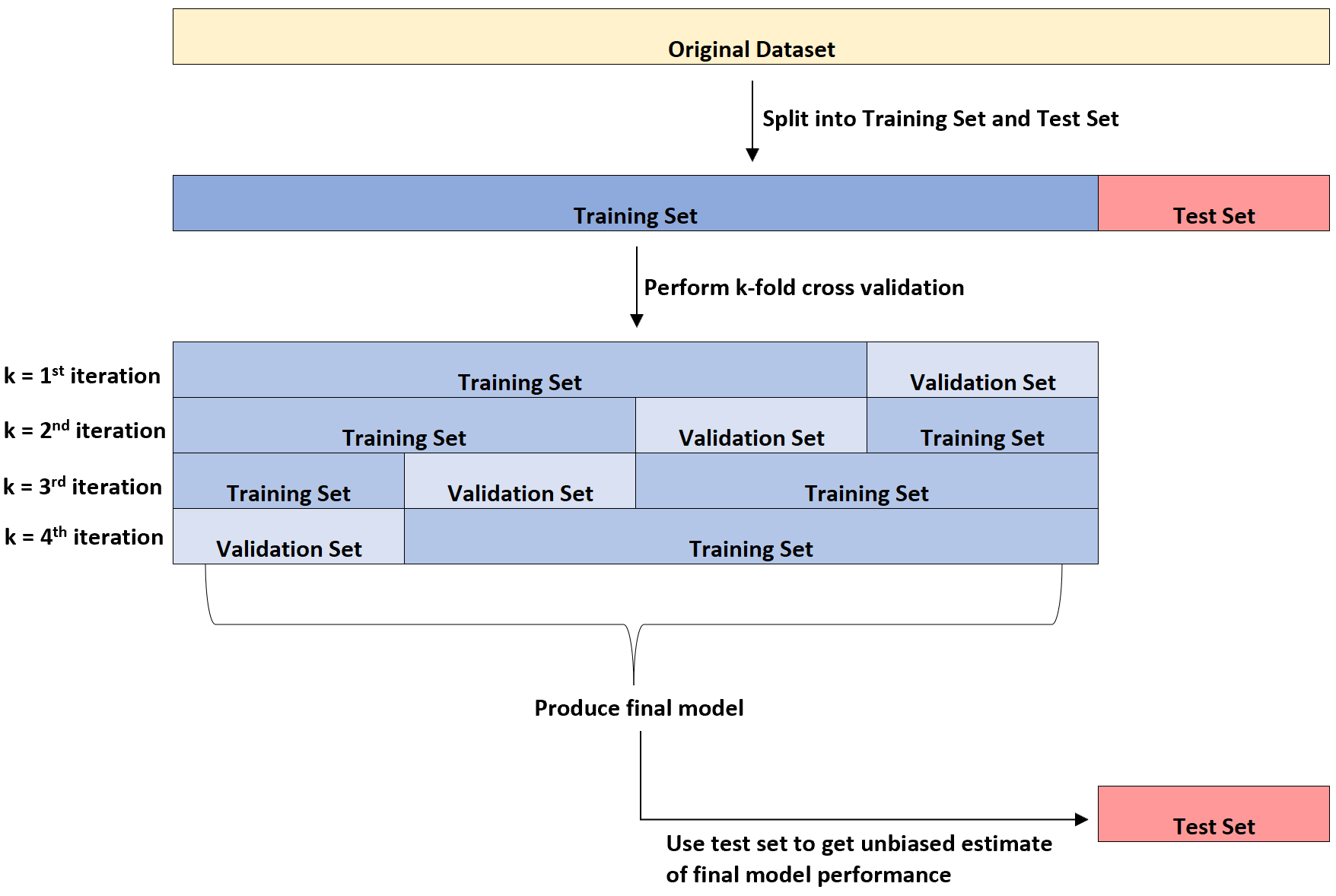
Un punto di confusione per gli studenti è la differenza tra il set di validazione e il set di test.
In poche parole, il set di validazione viene utilizzato per ottimizzare i parametri del modello mentre il set di test viene utilizzato per fornire una stima imparziale del modello finale.
È possibile dimostrare che il tasso di errore misurato dalla convalida incrociata k-fold tende a sottostimare il tasso di errore reale una volta applicato il modello a un set di dati invisibile.
Pertanto, adattiamo il modello finale al set di test per ottenere una stima imparziale di quale sarà il vero tasso di errore nel mondo reale.
L’esempio seguente illustra la differenza tra un set di validazione e un set di test nella pratica.
Esempio: comprendere la differenza tra set di convalida e set di test
Supponiamo che un investitore immobiliare voglia utilizzare (1) il numero di camere da letto, (2) il numero totale di metri quadrati e (3) il numero di bagni per prevedere il prezzo di vendita di una determinata casa.
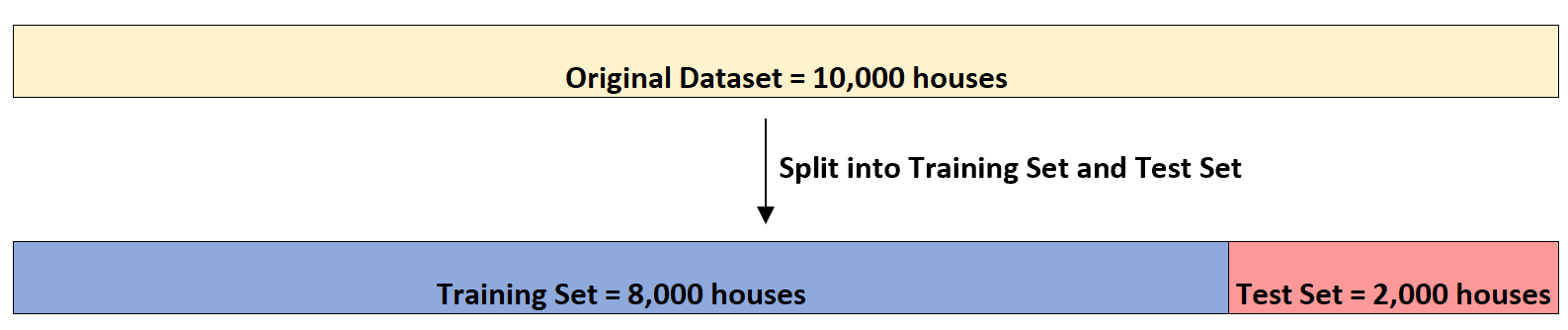
Supponiamo che abbia un set di dati con queste informazioni su 10.000 case. Innanzitutto, suddividerà il set di dati in un set di addestramento di 8.000 case e un set di test di 2.000 case:
Quindi adatterà un modello di regressione lineare multipla al set di dati quattro volte. Utilizzerà ogni volta 6.000 case per il training set e 2.000 case per il validation set.
Questa è chiamata convalida incrociata k-fold.
Il set di training viene utilizzato per addestrare il modello e il set di convalida viene utilizzato per valutare le prestazioni del modello. Utilizzerà ogni volta un gruppo diverso di 2.000 case per il set di convalida.
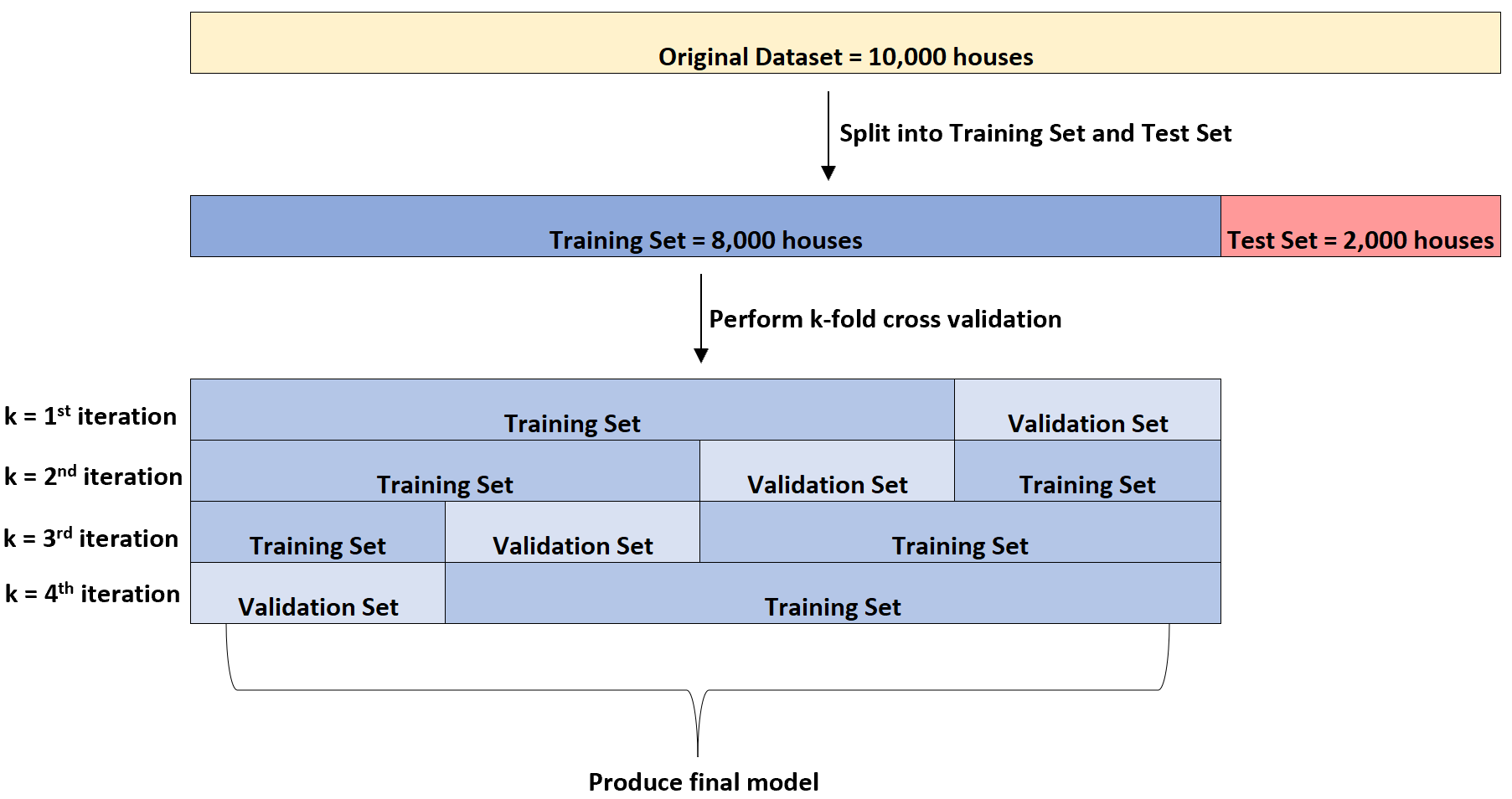
Può eseguire questa convalida incrociata k-fold su diversi tipi di modelli di regressione per identificare il modello che presenta l’errore più basso (ovvero identificare il modello che meglio si adatta al set di dati).
Solo una volta identificato il modello migliore utilizzerà il set di test di 2.000 case presentato all’inizio per ottenere una stima imparziale delle prestazioni finali del modello.
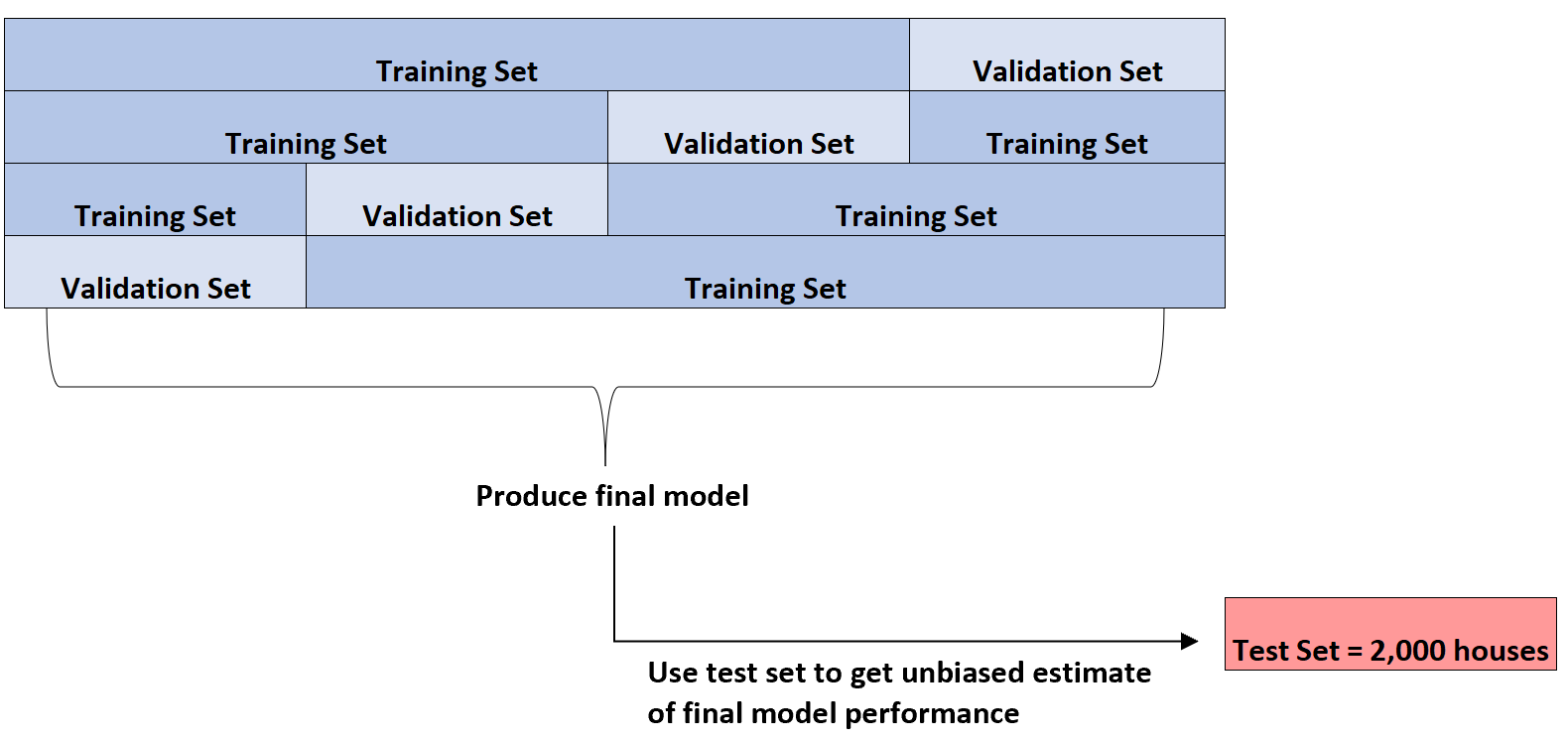
Ad esempio, potrebbe identificare un tipo specifico di modello di regressione il cui errore medio assoluto è 8.345 . Cioè, la differenza media assoluta tra il prezzo delle case previsto e il prezzo effettivo delle case è di $ 8.345.
Può quindi adattare questo esatto modello di regressione all’insieme di test di 2.000 case che non è stato ancora utilizzato e scoprire che l’errore medio assoluto del modello è 8,847 .
Pertanto, la stima imparziale del vero errore medio assoluto del modello è di $ 8.847.
Risorse addizionali
Una semplice guida alla convalida incrociata di K-Fold
Come eseguire la convalida incrociata K-Fold in Python
Come eseguire la convalida incrociata K-Fold in R
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più