Come eseguire un test di shapiro-wilk in r (con esempi)
Il test di Shapiro-Wilk è un test di normalità. Viene utilizzato per determinare se un campione proviene o meno da una distribuzione normale .
Questo tipo di test è utile per determinare se un determinato set di dati proviene o meno da una distribuzione normale, che è un presupposto comunemente utilizzato in molti test statistici, tra cui regressione , ANOVA , test t e molti altri. ‘altri.
Possiamo facilmente eseguire un test Shapiro-Wilk su un dato set di dati utilizzando la seguente funzione incorporata in R:
shapiro.test(x)
Oro:
- x: un vettore numerico di valori di dati.
Questa funzione produce una statistica del test W insieme a un valore p corrispondente. Se il valore p è inferiore a α = 0,05, ci sono prove sufficienti per affermare che il campione non proviene da una popolazione distribuita normalmente.
Nota: la dimensione del campione deve essere compresa tra 3 e 5.000 per utilizzare la funzione shapiro.test().
Questo tutorial mostra diversi esempi di utilizzo pratico di questa funzione.
Esempio 1: test di Shapiro-Wilk su dati normali
Il codice seguente mostra come eseguire un test di Shapiro-Wilk su un set di dati con dimensione del campione n=100:
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a normal distribution data <- rnorm(100) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data:data W = 0.98957, p-value = 0.6303
Il valore p del test risulta essere 0,6303 . Poiché questo valore non è inferiore a 0,05, possiamo supporre che i dati del campione provengano da una popolazione distribuita normalmente.
Questo risultato non dovrebbe sorprendere poiché abbiamo generato i dati campione utilizzando la funzione rnorm(), che genera valori casuali da una distribuzione normale con media = 0 e deviazione standard = 1.
Correlato: Una guida a dnorm, pnorm, qnorm e rnorm in R
Possiamo anche produrre un istogramma per verificare visivamente che i dati del campione siano distribuiti normalmente:
hist(data, col=' steelblue ')
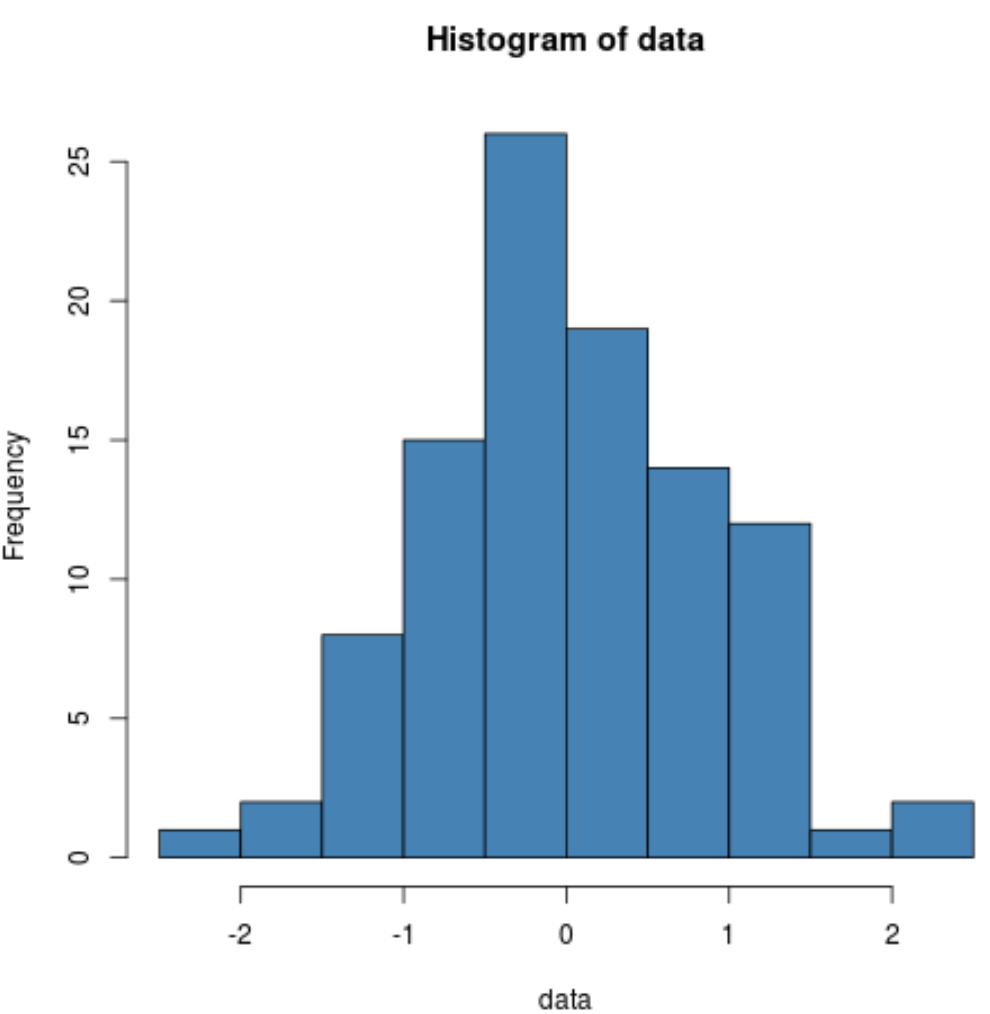
Possiamo vedere che la distribuzione è piuttosto a campana con un picco al centro della distribuzione, tipico dei dati distribuiti normalmente.
Esempio 2: test di Shapiro-Wilk su dati non normali
Il codice seguente mostra come eseguire un test di Shapiro-Wilk su un set di dati con dimensione campionaria n=100 in cui i valori sono generati casualmente da una distribuzione di Poisson :
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a Poisson distribution data <- rpois(n=100, lambda=3) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data:data W = 0.94397, p-value = 0.0003393
Il valore p del test risulta essere 0,0003393 . Poiché questo valore è inferiore a 0,05, abbiamo prove sufficienti per affermare che i dati del campione non provengono da una popolazione distribuita normalmente.
Questo risultato non dovrebbe sorprendere poiché abbiamo generato i dati campione utilizzando la funzione rpois(), che genera valori casuali da una distribuzione di Poisson.
Correlati: una guida a dpois, ppois, qpois e rpois in R
Possiamo anche produrre un istogramma per vedere visivamente che i dati del campione non sono distribuiti normalmente:
hist(data, col=' coral2 ')
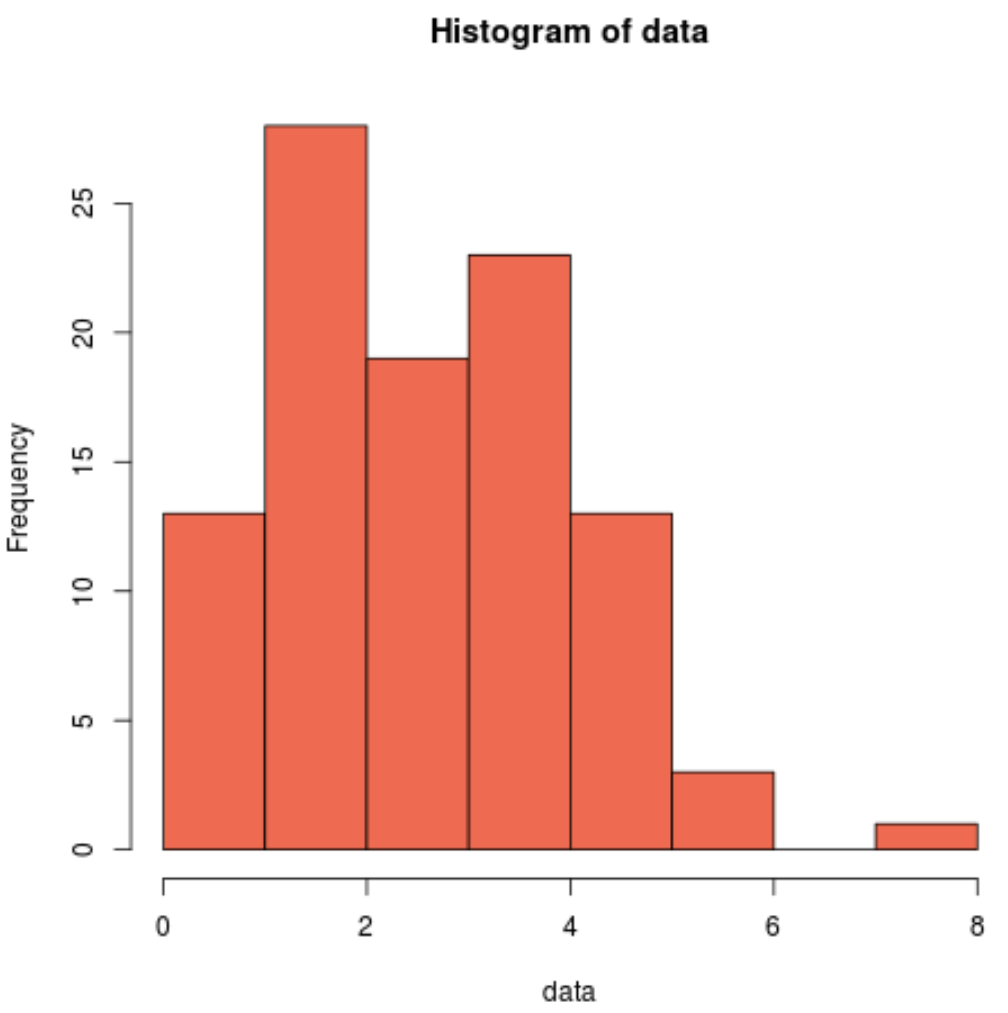
Possiamo vedere che la distribuzione è distorta a destra e non ha la tipica “forma a campana” associata ad una distribuzione normale. Pertanto, il nostro istogramma corrisponde ai risultati del test di Shapiro-Wilk e conferma che i dati del nostro campione non provengono da una distribuzione normale.
Cosa fare con i dati non normali
Se un dato set di dati non è distribuito normalmente, spesso possiamo eseguire una delle seguenti trasformazioni per renderlo più normale:
1. Trasformazione del log: trasforma la variabile di risposta da y a log(y) .
2. Trasformazione della radice quadrata: trasforma la variabile di risposta da y a √y .
3. Trasformazione della radice del cubo: trasforma la variabile di risposta da y a y 1/3 .
Eseguendo queste trasformazioni, la variabile di risposta generalmente si avvicina alla distribuzione normale.
Dai un’occhiata a questo tutorial per vedere come eseguire queste trasformazioni nella pratica.
Risorse addizionali
Come eseguire un test di Anderson-Darling in R
Come eseguire un test di Kolmogorov-Smirnov in R
Come eseguire un test di Shapiro-Wilk in Python
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più