Tipi di distribuzioni di probabilità
Questo articolo spiega i diversi tipi di distribuzioni di probabilità nelle statistiche. Quindi scoprirai quanti tipi di distribuzioni di probabilità esistono e quali sono le differenze tra loro.
Quali sono i tipi di distribuzioni di probabilità?
I tipi di distribuzioni di probabilità sono:
- Distribuzioni discrete di probabilità :
- Distribuzione discreta ed uniforme .
- Distribuzione di Bernoulli .
- Distribuzione binomiale .
- Distribuzione del pesce .
- Distribuzione multinomiale .
- Distribuzione geometrica .
- Distribuzione binomiale negativa .
- Distribuzione ipergeometrica .
- Distribuzioni di probabilità continue :
- Distribuzione uniforme e continua .
- Distribuzione normale .
- Distribuzione lognormale .
- Distribuzione chi-quadrato .
- Distribuzione t di Student .
- Distribuzione Snedecor F.
- Distribuzione esponenziale .
- Distribuzione beta .
- Distribuzione gamma .
- Distribuzione di Weibull .
- Distribuzione di Pareto .
Ogni tipo di distribuzione di probabilità è spiegato in dettaglio di seguito.
Distribuzioni discrete di probabilità
Una distribuzione di probabilità discreta è la distribuzione che definisce le probabilità di una variabile casuale discreta. Pertanto, una distribuzione di probabilità discreta può assumere solo un numero finito di valori (solitamente valori interi).
Distribuzione discreta ed uniforme
La distribuzione uniforme discreta è una distribuzione di probabilità discreta in cui tutti i valori sono equiprobabili, cioè in una distribuzione uniforme discreta tutti i valori hanno la stessa probabilità di verificarsi.
Ad esempio, il lancio di un dado può essere definito con una distribuzione discreta e uniforme, poiché tutti i possibili risultati (1, 2, 3, 4, 5 o 6) hanno la stessa probabilità di verificarsi.
In generale, una distribuzione discreta uniforme ha due parametri caratteristici, a e b , che definiscono l’intervallo di possibili valori che la distribuzione può assumere. Pertanto, quando una variabile è definita da una distribuzione uniforme discreta, si scrive Uniform(a,b) .

La distribuzione uniforme discreta può essere utilizzata per descrivere esperimenti casuali, perché se tutti i risultati hanno la stessa probabilità, significa che c’è casualità nell’esperimento.
Distribuzione di Bernoulli
La distribuzione di Bernoulli , detta anche distribuzione dicotomica , è una distribuzione di probabilità che rappresenta una variabile discreta che può avere solo due esiti: “successo” o “fallimento”.
Nella distribuzione di Bernoulli, il “successo” è l’esito che ci aspettiamo e ha valore 1, mentre l’esito del “fallimento” è un esito diverso da quello atteso e ha valore 0. Quindi, se la probabilità dell’esito di “ successo” è p , la probabilità dell’esito di “fallimento” è q=1-p .
![\begin{array}{c}X\sim \text{Bernoulli}(p)\\[2ex]\begin{array}{l} \text{\'Exito}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=1]=p\\[2ex]\text{Fracaso}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=0]=q=1-p\end{array}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-384fd7d96d4d6584739b04a6e331b251_l3.png "Rendered by QuickLaTeX.com")
La distribuzione di Bernoulli prende il nome dallo statistico svizzero Jacob Bernoulli.
In statistica, la distribuzione di Bernoulli ha principalmente un’applicazione: definire le probabilità di esperimenti in cui ci sono solo due possibili risultati: successo e fallimento. Quindi, un esperimento che utilizza la distribuzione di Bernoulli è chiamato test di Bernoulli o esperimento di Bernoulli.
Distribuzione binomiale
La distribuzione binomiale , chiamata anche distribuzione binomiale , è una distribuzione di probabilità che conta il numero di successi quando si eseguono una serie di esperimenti dicotomici indipendenti con una probabilità di successo costante. In altre parole, la distribuzione binomiale è una distribuzione che descrive il numero di esiti positivi di una sequenza di prove Bernoulliane.
Ad esempio, il numero di volte in cui una moneta esce testa 25 volte è una distribuzione binomiale.
In generale, il numero totale di esperimenti eseguiti è definito dal parametro n , mentre p è la probabilità di successo di ciascun esperimento. Pertanto, una variabile casuale che segue una distribuzione binomiale si scrive come segue:

Si noti che in una distribuzione binomiale, lo stesso identico esperimento viene ripetuto n volte e gli esperimenti sono indipendenti l’uno dall’altro, quindi la probabilità di successo per ciascun esperimento è la stessa (p) .
Distribuzione del pesce
La distribuzione di Poisson è una distribuzione di probabilità che definisce la probabilità che un certo numero di eventi si verifichino in un periodo di tempo. In altre parole, la distribuzione di Poisson viene utilizzata per modellare variabili casuali che descrivono il numero di volte in cui un fenomeno si ripete in un intervallo di tempo.
Ad esempio, il numero di chiamate ricevute al minuto da una centrale telefonica è una variabile casuale discreta che può essere definita utilizzando la distribuzione di Poisson.
La distribuzione di Poisson ha un parametro caratteristico, rappresentato dalla lettera greca λ e indica il numero di volte in cui si prevede che l’evento studiato si verifichi durante un dato intervallo.

distribuzione multinomiale
La distribuzione multinomiale (o distribuzione multinomiale ) è una distribuzione di probabilità che descrive la probabilità che più eventi esclusivi si verifichino un dato numero di volte dopo aver eseguito più prove.
Cioè, se un esperimento casuale può dare come risultato tre o più eventi esclusivi ed è nota la probabilità che ciascun evento si verifichi separatamente, la distribuzione multinomiale viene utilizzata per calcolare la probabilità che, quando si eseguono più esperimenti, si verifichi un certo numero di eventi. volte ogni evento.
La distribuzione multinomiale è quindi una generalizzazione della distribuzione binomiale.
distribuzione geometrica
La distribuzione geometrica è una distribuzione di probabilità che definisce il numero di prove Bernoulliane necessarie per ottenere il primo risultato positivo. Cioè, una distribuzione geometrica modella processi in cui gli esperimenti di Bernoulli vengono ripetuti finché uno di essi non ottiene un risultato positivo.
Ad esempio, il numero di auto che passano su un’autostrada finché non vedono un’auto gialla è una distribuzione geometrica.
Ricorda che un test di Bernoulli è un esperimento che ha due possibili esiti: “successo” e “fallimento”. Quindi se la probabilità di “successo” è p , la probabilità di “fallimento” è q=1-p .
Pertanto, la distribuzione geometrica dipende dal parametro p , che è la probabilità di successo di tutti gli esperimenti eseguiti. Inoltre, la probabilità p è la stessa per tutti gli esperimenti.

distribuzione binomiale negativa
La distribuzione binomiale negativa è una distribuzione di probabilità che descrive il numero di prove Bernoulliane necessarie per ottenere un dato numero di risultati positivi.
Pertanto, una distribuzione binomiale negativa ha due parametri caratteristici: r è il numero desiderato di risultati positivi e p è la probabilità di successo per ogni esperimento di Bernoulli eseguito.

Pertanto, una distribuzione binomiale negativa definisce un processo in cui vengono eseguite tutte le prove Bernoulliane necessarie per ottenere risultati positivi. Inoltre, tutti questi studi di Bernoulli sono indipendenti e hanno una probabilità di successo costante.
Ad esempio, una variabile casuale che segue una distribuzione binomiale negativa è il numero di volte in cui è necessario lanciare un dado finché il numero 6 non sia tre volte.
distribuzione ipergeometrica
La distribuzione ipergeometrica è una distribuzione di probabilità che descrive il numero di casi di successo in un’estrazione casuale senza sostituzione di n elementi da una popolazione.
Cioè, la distribuzione ipergeometrica viene utilizzata per calcolare la probabilità di ottenere x successi estraendo n elementi da una popolazione senza sostituirne nessuno.
Pertanto, la distribuzione ipergeometrica ha tre parametri:
- N : è il numero di elementi della popolazione (N = 0, 1, 2,…).
- K : è il numero massimo di casi di successo (K = 0, 1, 2,…,N). Poiché in una distribuzione ipergeometrica un elemento può essere considerato solo un “successo” o un “fallimento”, NK è il numero massimo di casi di fallimento.
- n : è il numero di recuperi senza sostituzione eseguiti.

Distribuzioni di probabilità continue
Una distribuzione di probabilità continua è quella che può assumere qualsiasi valore in un intervallo, compresi i valori decimali. Pertanto, una distribuzione di probabilità continua definisce le probabilità di una variabile casuale continua.
distribuzione uniforme e continua
La distribuzione uniforme continua , chiamata anche distribuzione rettangolare , è un tipo di distribuzione di probabilità continua in cui tutti i valori hanno la stessa probabilità di verificarsi. In altre parole, la distribuzione uniforme continua è una distribuzione in cui la probabilità è distribuita uniformemente su un intervallo.
La distribuzione uniforme continua viene utilizzata per descrivere variabili continue che hanno probabilità costante. Allo stesso modo, la distribuzione uniforme continua viene utilizzata per definire i processi casuali, perché se tutti i risultati hanno la stessa probabilità, significa che c’è casualità nel risultato.
La distribuzione uniforme continua ha due parametri caratteristici, aeb , che definiscono l’intervallo di equiprobabilità. Pertanto, il simbolo della distribuzione uniforme continua è U(a,b) , dove a e b sono i valori caratteristici della distribuzione.

Ad esempio, se il risultato di un esperimento casuale può assumere qualsiasi valore compreso tra 5 e 9 e tutti i possibili risultati hanno la stessa probabilità di verificarsi, l’esperimento può essere simulato con una distribuzione uniforme continua U(5.9).
Distribuzione normale
La distribuzione normale è una distribuzione di probabilità continua il cui grafico è a campana e simmetrico rispetto alla sua media. In statistica, la distribuzione normale viene utilizzata per modellare fenomeni con caratteristiche molto diverse, motivo per cui questa distribuzione è così importante.
Infatti, in statistica, la distribuzione normale è considerata di gran lunga la più importante tra tutte le distribuzioni di probabilità, perché consente non solo di modellare un gran numero di fenomeni reali, ma anche di utilizzare la distribuzione normale per approssimare altri tipi di distribuzioni. a determinate condizioni.
Il simbolo della distribuzione normale è la lettera maiuscola N. Quindi, per indicare che una variabile segue una distribuzione normale, si indica con la lettera N e si aggiungono tra parentesi i valori della sua media aritmetica e della deviazione standard.

La distribuzione normale ha molti nomi diversi, tra cui distribuzione gaussiana , distribuzione gaussiana e distribuzione di Laplace-Gauss .
Distribuzione lognormale
La distribuzione lognormale , o distribuzione lognormale , è una distribuzione di probabilità che definisce una variabile casuale il cui logaritmo segue una distribuzione normale.
Pertanto, se la variabile X ha una distribuzione normale, allora la funzione esponenziale e x ha una distribuzione lognormale.

Si noti che la distribuzione lognormale può essere utilizzata solo quando i valori delle variabili sono positivi, poiché il logaritmo è una funzione che accetta solo un argomento positivo.
Tra le diverse applicazioni della distribuzione lognormale in statistica, distinguiamo l’utilizzo di questa distribuzione per analizzare investimenti finanziari ed effettuare analisi di affidabilità.
La distribuzione lognormale è conosciuta anche come distribuzione Tinaut , a volte scritta anche come distribuzione lognormale o distribuzione lognormale .
Distribuzione chi-quadrato
La distribuzione Chi-quadrato è una distribuzione di probabilità il cui simbolo è χ². Più precisamente, la distribuzione Chi-quadrato è la somma dei quadrati di k variabili casuali indipendenti con distribuzione normale.
Pertanto, la distribuzione Chi-quadrato ha k gradi di libertà. Pertanto, una distribuzione Chi-quadrato ha tanti gradi di libertà quanti sono la somma dei quadrati delle variabili normalmente distribuite che rappresenta.
![\displaystyle X\sim\chi^2_k \ \color{orange}\bm{\longrightarrow}\color{black}\ \begin{array}{l}\text{Distribuci\'on chi-cuadrado}\\[2ex]\text{con k grados de libertad}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9ea0bf7a87071883ceae5e419bae9e71_l3.png "Rendered by QuickLaTeX.com")
La distribuzione Chi-quadrato è anche conosciuta come distribuzione Pearson .
La distribuzione chi-quadrato è ampiamente utilizzata nell’inferenza statistica, ad esempio nei test di ipotesi e negli intervalli di confidenza. Vedremo di seguito quali sono le applicazioni di questo tipo di distribuzione di probabilità.
Distribuzione t di Student
La distribuzione t di Student è una distribuzione di probabilità ampiamente utilizzata in statistica. Nello specifico, la distribuzione t di Student viene utilizzata nel test t di Student per determinare la differenza tra le medie di due campioni e per stabilire intervalli di confidenza.
La distribuzione t di Student fu sviluppata dallo statistico William Sealy Gosset nel 1908 con lo pseudonimo di “Student”.
La distribuzione t di Student è definita dal numero di gradi di libertà, ottenuti sottraendo un’unità dal numero totale di osservazioni. Pertanto, la formula per determinare i gradi di libertà della distribuzione t di Student è ν=n-1 .
![\begin{array}{c}\nu=n-1\\[2ex]X\sim t_\nu\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1c805dc2d6ca050feb70dad99de53402_l3.png "Rendered by QuickLaTeX.com")
Distribuzione Snedecor F
La distribuzione F di Snedecor , chiamata anche distribuzione F di Fisher-Snedecor o semplicemente distribuzione F , è una distribuzione di probabilità continua utilizzata nell’inferenza statistica, in particolare nell’analisi della varianza.
Una delle proprietà della distribuzione Snedecor F è che è definita dal valore di due parametri reali, m e n , che ne indicano i gradi di libertà. Pertanto, il simbolo della distribuzione Snedecor F è F m,n , dove m e n sono i parametri che definiscono la distribuzione.
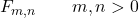
![\left.\begin{array}{c} X\sim \chi_m^2\\[2ex] Y\sim \chi_n^2\end{array}\right\}\color{orange}\bm{\longrightarrow}\color{black}\ F_{m,n}= \cfrac{X/m}{Y/n}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d407869e61ca4357ffbcb40df3bd83ab_l3.png "Rendered by QuickLaTeX.com")
La distribuzione F Fisher-Snedecor deve il suo nome allo statistico inglese Ronald Fisher e allo statistico americano George Snedecor.
Nelle statistiche, la distribuzione F Fisher-Snedecor ha diverse applicazioni. Ad esempio, la distribuzione F Fisher-Snedecor viene utilizzata per confrontare diversi modelli di regressione lineare e questa distribuzione di probabilità viene utilizzata nell’analisi della varianza (ANOVA).
Distribuzione esponenziale
La distribuzione esponenziale è una distribuzione di probabilità continua utilizzata per modellare il tempo di attesa per il verificarsi di un fenomeno casuale.
Più precisamente, la distribuzione esponenziale permette di descrivere il tempo di attesa tra due eventi che segue una distribuzione di Poisson. Pertanto, la distribuzione esponenziale è strettamente correlata alla distribuzione di Poisson.
La distribuzione esponenziale ha un parametro caratteristico, rappresentato dalla lettera greca λ e indica il numero di volte in cui si prevede che l’evento studiato si verifichi in un dato periodo di tempo.

Allo stesso modo, la distribuzione esponenziale viene utilizzata anche per modellare il tempo fino al verificarsi di un guasto. La distribuzione esponenziale ha quindi diverse applicazioni nella teoria dell’affidabilità e della sopravvivenza.
Distribuzione beta
La distribuzione beta è una distribuzione di probabilità definita sull’intervallo (0,1) e parametrizzata da due parametri positivi: α e β. In altre parole, i valori della distribuzione beta dipendono dai parametri α e β.
Pertanto, la distribuzione beta viene utilizzata per definire variabili casuali continue il cui valore varia da 0 a 1.
Esistono diverse notazioni per indicare che una variabile casuale continua è governata da una distribuzione beta, le più comuni sono:
![\begin{array}{c}X\sim B(\alpha,\beta)\\[2ex]X\sim Beta(\alpha,\beta)\\[2ex]X\sim \beta_{\alpha,\beta}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ee1d0d8a1624a017b8ef9ce8a67c694e_l3.png "Rendered by QuickLaTeX.com")
Nelle statistiche, la distribuzione beta ha applicazioni molto diverse. Ad esempio, la distribuzione beta viene utilizzata per studiare le variazioni percentuali in diversi campioni. Allo stesso modo, nella gestione dei progetti, la distribuzione beta viene utilizzata per eseguire l’analisi Pert.
Distribuzione gamma
La distribuzione gamma è una distribuzione di probabilità continua definita da due parametri caratteristici, α e λ. In altre parole, la distribuzione gamma dipende dal valore dei suoi due parametri: α è il parametro di forma e λ è il parametro di scala.
Il simbolo della distribuzione gamma è la lettera greca maiuscola Γ. Quindi, se una variabile casuale segue una distribuzione gamma, si scrive come segue:

La distribuzione gamma può anche essere parametrizzata utilizzando il parametro di forma k = α e il parametro di scala inversa θ = 1/λ. In tutti i casi, i due parametri che definiscono la distribuzione gamma sono numeri reali positivi.
In genere, la distribuzione gamma viene utilizzata per modellare set di dati inclinati a destra, in modo che vi sia una maggiore concentrazione di dati sul lato sinistro del grafico. Ad esempio, la distribuzione gamma viene utilizzata per modellare l’affidabilità dei componenti elettrici.
Distribuzione di Weibull
La distribuzione di Weibull è una distribuzione di probabilità continua definita da due parametri caratteristici: il parametro di forma α e il parametro di scala λ.
Nelle statistiche, la distribuzione di Weibull viene utilizzata principalmente per l’analisi della sopravvivenza. Allo stesso modo, la distribuzione Weibull ha molte applicazioni in diversi campi.

Secondo gli autori la distribuzione di Weibull può essere parametrizzata anche con tre parametri. Successivamente viene aggiunto un terzo parametro chiamato valore di soglia, che indica l’ascissa in cui inizia il grafico della distribuzione.
La distribuzione di Weibull prende il nome dallo svedese Waloddi Weibull, che la descrisse dettagliatamente nel 1951. Tuttavia, la distribuzione di Weibull fu scoperta da Maurice Fréchet nel 1927 e applicata per la prima volta da Rosin e Rammler nel 1933.
Distribuzione di Pareto
La distribuzione di Pareto è una distribuzione di probabilità continua utilizzata in statistica per modellare il principio di Pareto. Pertanto, la distribuzione di Pareto è una distribuzione di probabilità che ha pochi valori la cui probabilità di accadimento è molto più alta rispetto al resto dei valori.
Ricordiamo che la legge di Pareto, detta anche regola 80-20, è un principio statistico secondo il quale la maggior parte della causa di un fenomeno è dovuta ad una piccola parte della popolazione.
La distribuzione di Pareto ha due parametri caratteristici: il parametro di scala x m e il parametro di forma α.

In origine, la distribuzione di Pareto veniva utilizzata per descrivere la distribuzione della ricchezza all’interno della popolazione, poiché la maggior parte di essa era dovuta ad una piccola percentuale della popolazione. Ma attualmente la distribuzione di Pareto ha molteplici applicazioni, ad esempio nel controllo della qualità, in economia, nella scienza, in campo sociale, ecc.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più