Come tracciare una curva di regressione logistica in python
Puoi utilizzare la funzione regplot() della libreria di visualizzazione dei dati seaborn per tracciare una curva di regressione logistica in Python:
import seaborn as sns sns. regplot (x=x, y=y, data=df, logistic= True , ci= None )
L’esempio seguente mostra come utilizzare questa sintassi nella pratica.
Esempio: tracciare una curva di regressione logistica in Python
Per questo esempio, utilizzeremo il set di dati predefinito dal libro Introduction to Statistical Learning . Possiamo utilizzare il seguente codice per caricare e visualizzare un riepilogo del set di dati:
#import dataset from CSV file on Github url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv" data = pd. read_csv (url) #view first six rows of dataset data[0:6] default student balance income 0 0 0 729.526495 44361.625074 1 0 1 817.180407 12106.134700 2 0 0 1073.549164 31767.138947 3 0 0 529.250605 35704.493935 4 0 0 785.655883 38463.495879 5 0 1 919.588530 7491.558572
Questo set di dati contiene le seguenti informazioni su 10.000 individui:
- default: indica se un individuo è inadempiente o meno.
- studente: indica se un individuo è studente o meno.
- saldo: saldo medio portato da un individuo.
- reddito: reddito dell’individuo.
Supponiamo di voler costruire un modello di regressione logistica che utilizzi il “bilanciamento” per prevedere la probabilità che un dato individuo vada in default.
Possiamo utilizzare il seguente codice per tracciare una curva di regressione logistica:
#define the predictor variable and the response variable
x = data[' balance ']
y = data[' default ']
#plot logistic regression curve
sns. regplot (x=x, y=y, data=data, logistic= True , ci= None )
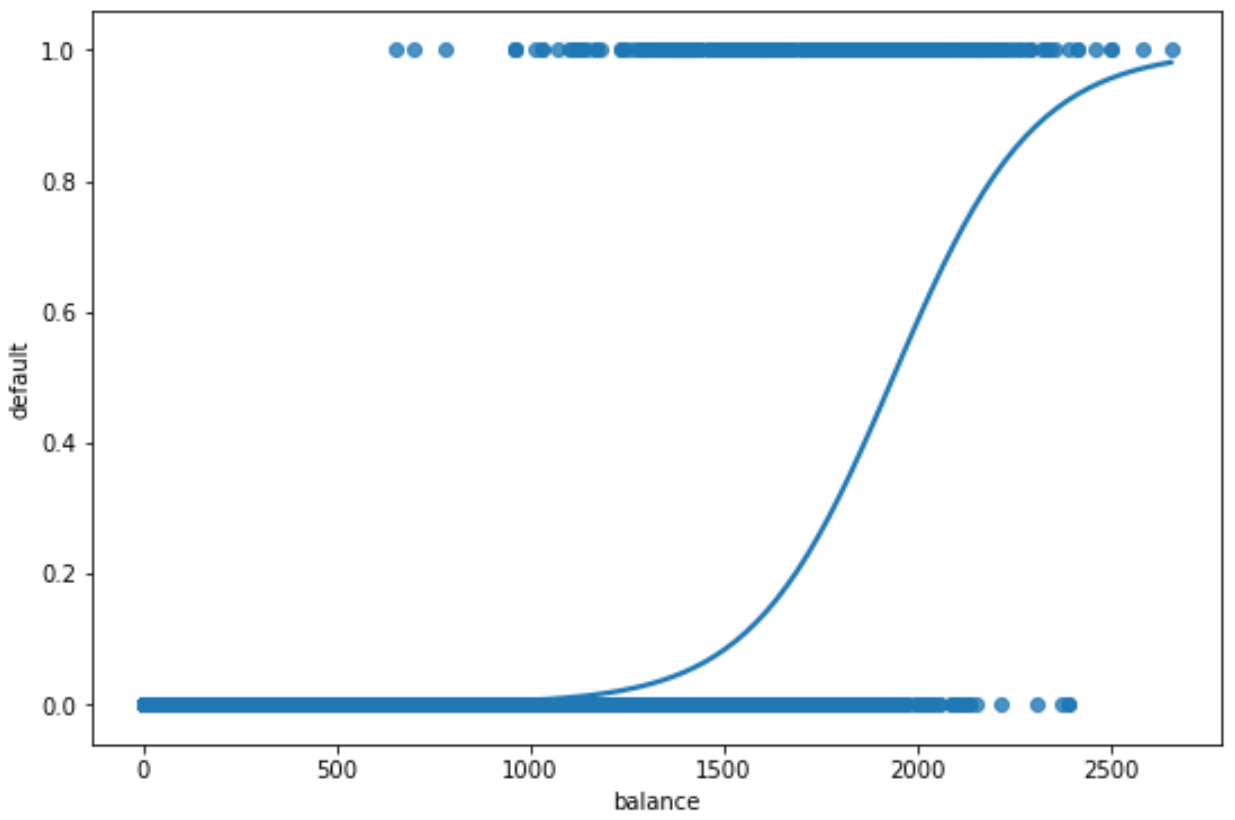
L’asse x mostra i valori della variabile predittrice “saldo” e l’asse y mostra la probabilità di default prevista.
Possiamo vedere chiaramente che valori di equilibrio più elevati sono associati a maggiori probabilità che un individuo vada in default.
Nota che puoi anche usare scatter_kws e line_kws per cambiare i colori dei punti e della curva nel grafico:
#define the predictor variable and the response variable
x = data[' balance ']
y = data[' default ']
#plot logistic regression curve with black points and red line
sns. regplot (x=x, y=y, data=data, logistic= True , ci= None ),
scatter_kws={' color ': ' black '}, line_kws={' color ': ' red '})
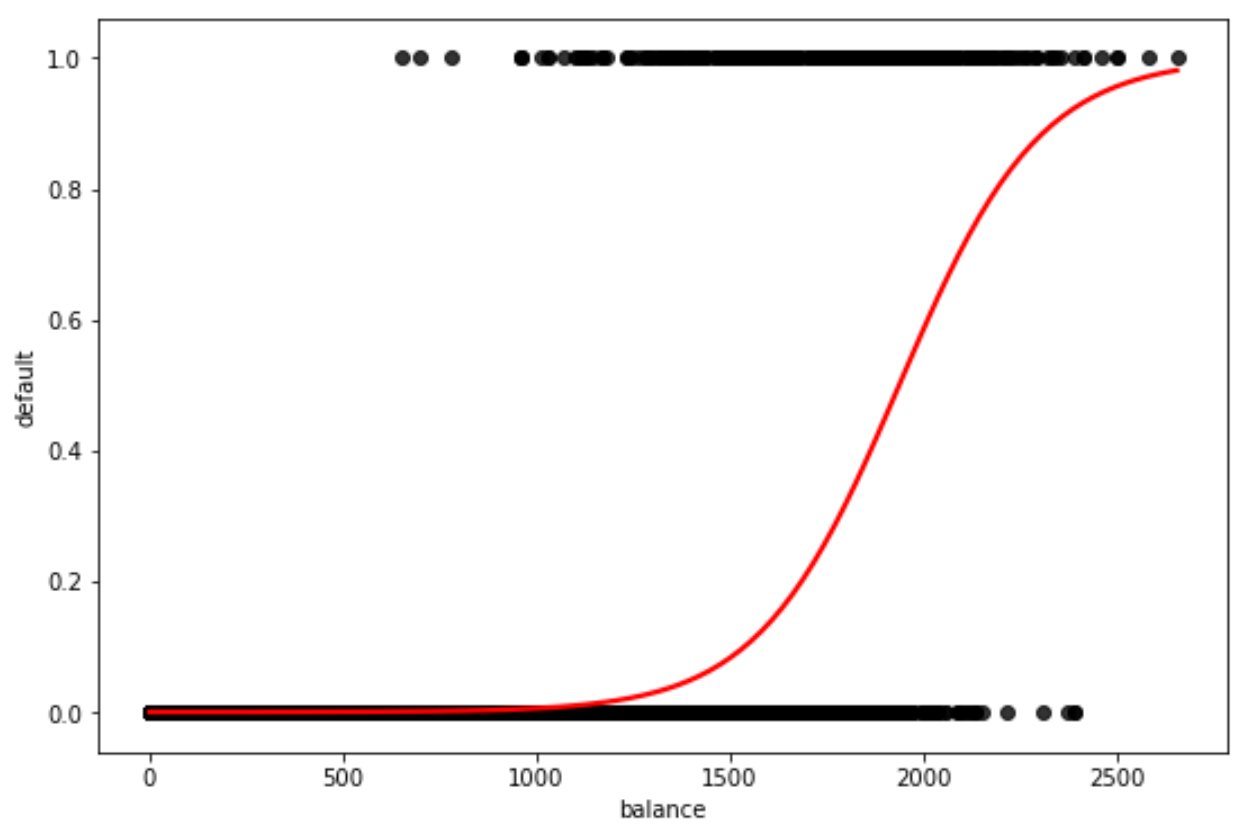
Sentiti libero di scegliere i colori che desideri nella trama.
Risorse addizionali
Le seguenti esercitazioni forniscono informazioni aggiuntive sulla regressione logistica:
Introduzione alla regressione logistica
Come riportare i risultati della regressione logistica
Come eseguire la regressione logistica in Python (passo dopo passo)
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più