Come utilizzare le variabili fittizie nell'analisi di regressione
La regressione lineare è un metodo che possiamo utilizzare per quantificare la relazione tra una o più variabili predittive e una variabile di risposta .
Generalmente utilizziamo la regressione lineare con variabili quantitative . A volte chiamate variabili “numeriche”, si tratta di variabili che rappresentano una quantità misurabile. Esempi inclusi:
- Numero di piedi quadrati in una casa
- Dimensione della popolazione di una città
- Età di un individuo
Tuttavia, a volte vogliamo utilizzare variabili categoriali come variabili predittive. Queste sono variabili che prendono nomi o etichette e possono rientrare in categorie. Esempi inclusi:
- Colore degli occhi (ad esempio “blu”, “verde”, “marrone”)
- Genere (ad es. “uomo”, “donna”)
- Stato civile (ad esempio “sposato”, “celibe”, “divorziato”)
Quando si utilizzano variabili categoriali, non ha senso assegnare solo valori come 1, 2, 3 a valori come “blu”, “verde” e “marrone”, perché non ha senso dire quel verde è doppio. colorato come il blu o il marrone è tre volte più colorato del blu.
Invece, la soluzione è utilizzare variabili fittizie . Si tratta di variabili che creiamo appositamente per l’analisi di regressione e che assumono uno di due valori: zero o uno.
Variabili fittizie: variabili numeriche utilizzate nell’analisi di regressione per rappresentare dati categorici che possono assumere solo uno di due valori: zero o uno.
Il numero di variabili dummy che dobbiamo creare è pari a k -1 dove k è il numero di valori diversi che può assumere la variabile categoriale.
Gli esempi seguenti illustrano come creare variabili fittizie per diversi set di dati.
Esempio 1: creare una variabile fittizia con solo due valori
Supponiamo di avere il seguente set di dati e di voler utilizzare il sesso e l’età per prevedere il reddito :
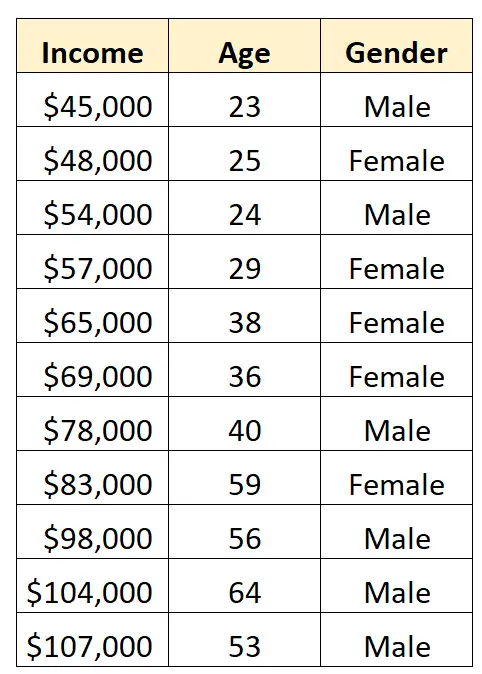
Per utilizzare il genere come variabile predittrice in un modello di regressione, dobbiamo convertirlo in una variabile fittizia.
Poiché attualmente si tratta di una variabile categoriale che può assumere due valori diversi (“Maschio” o “Femmina”), creiamo semplicemente k -1 = 2-1 = 1 variabile fittizia.
Per creare questa variabile fittizia, possiamo scegliere uno dei valori (“Maschio” o “Femmina”) per rappresentare 0 e l’altro per rappresentare 1.
In generale, di solito rappresentiamo il valore più frequente con uno 0, che sarebbe “Maschio” in questo set di dati.
Quindi, ecco come convertire il genere in una variabile fittizia:
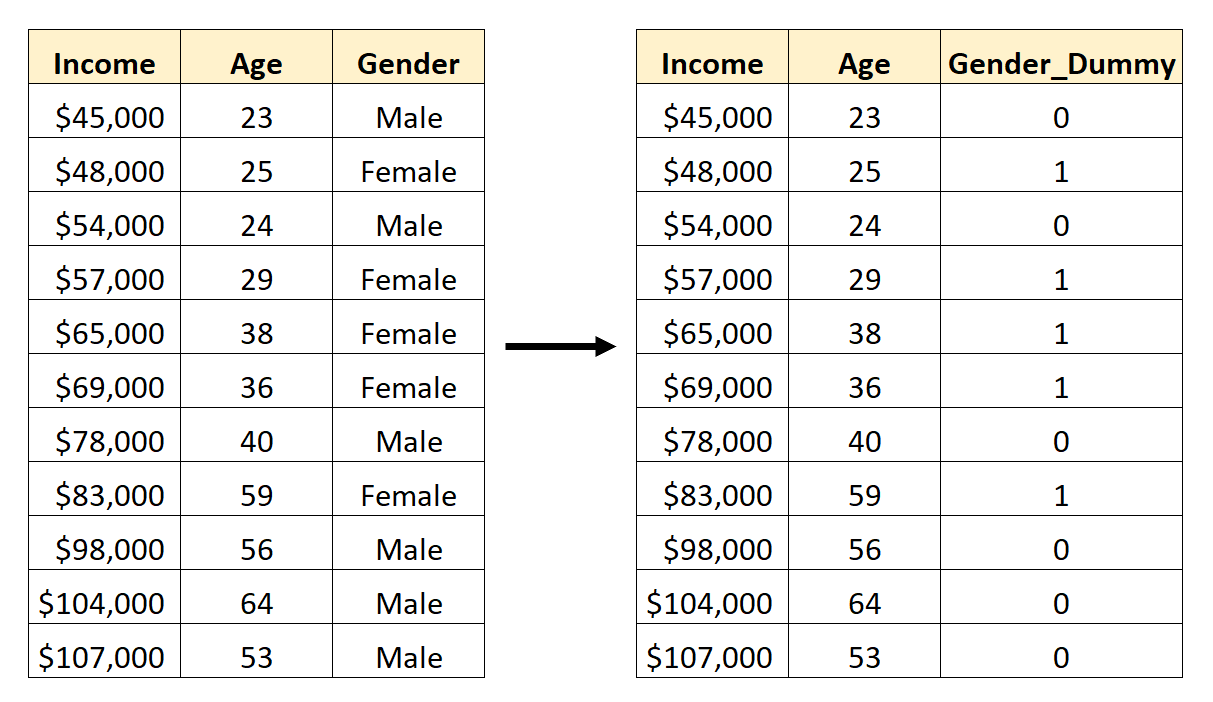
Potremmo quindi utilizzare Age e Gender_Dummy come variabili predittive in un modello di regressione.
Esempio 2: creare una variabile fittizia con più valori
Supponiamo di avere il seguente set di dati e di voler utilizzare lo stato civile e l’età per prevedere il reddito :

Per utilizzare lo stato civile come variabile predittiva in un modello di regressione, dobbiamo convertirlo in una variabile fittizia.
Poiché attualmente si tratta di una variabile categoriale che può assumere tre valori diversi (“Single”, “Sposato” o “Divorziato”), dobbiamo creare k -1 = 3-1 = 2 variabili dummy.
Per creare questa variabile fittizia, possiamo lasciare “Single” come valore base poiché appare più spesso. Quindi, ecco come convertiremo lo stato civile in variabili fittizie:

Potremmo quindi utilizzare Age , Married e Divorced come variabili predittive in un modello di regressione.
Come interpretare l’output della regressione con variabili fittizie
Supponiamo di adattare un modello di regressione lineare multipla utilizzando il set di dati dell’esempio precedente con Età , Sposato e Divorziato come variabili predittive e Reddito come variabile di risposta.
Ecco il risultato della regressione:
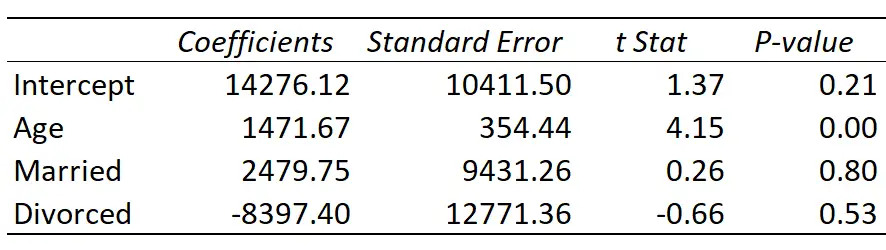
La retta di regressione adattata è definita come:
Reddito = 14.276,21 + 1.471,67*(Età) + 2.479,75*(Coniugato) – 8.397,40*(Divorziato)
Possiamo utilizzare questa equazione per trovare il reddito stimato di un individuo in base all’età e allo stato civile. Ad esempio, una persona di 35 anni sposata avrebbe un reddito stimato di $ 68.264 :
Reddito = 14.276,21 + 1.471,67*(35) + 2.479,75*(1) – 8.397,40*(0) = $ 68.264
Ecco come interpretare i coefficienti di regressione nella tabella:
- Intercetta: l’intercetta rappresenta il reddito medio di una singola persona di età pari a zero. Ovviamente non si possono avere zero anni, quindi non ha senso interpretare l’intercetta da sola in questo particolare modello di regressione.
- Età: ogni anno di aumento dell’età è associato a un aumento medio di 1.471,67 dollari di reddito. Poiché il valore p (0,00) è inferiore a 0,05, l’età è un predittore statisticamente significativo del reddito.
- Sposato: una persona sposata guadagna in media $ 2.479,75 in più di una persona single. Poiché il valore p (0,80) non è inferiore a 0,05, questa differenza non è statisticamente significativa.
- Divorziato: una persona divorziata guadagna in media $ 8.397,40 in meno di una persona single. Poiché il valore p (0,53) non è inferiore a 0,05, questa differenza non è statisticamente significativa.
Poiché entrambe le variabili dummy non erano statisticamente significative, potremmo rimuovere lo stato civile come predittore dal modello, poiché non sembra aggiungere valore predittivo al reddito.
Risorse addizionali
Variabili qualitative e quantitative
La trappola della variabile fittizia
Come leggere e interpretare una tabella di regressione
Una spiegazione dei valori P e della significatività statistica
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più