Come calcolare la varianza aggregata in r
Nelle statistiche, la varianza dei cluster si riferisce alla media di due o più varianze dei cluster.
Usiamo la parola “pool” per indicare che stiamo “raggruppando” due o più varianze di gruppo per ottenere un unico numero per la varianza comune tra i gruppi.
In pratica, la varianza aggregata viene utilizzata più spesso in un test t a due campioni , utilizzato per determinare se le medie di due popolazioni sono uguali o meno.
La varianza aggregata tra due campioni è generalmente indicata come sp 2 e viene calcolata come segue:
s p 2 = ( (n 1 -1)s 1 2 + (n 2 -1)s 2 2 ) / (n 1 +n 2 -2)
Sfortunatamente, non esiste una funzione incorporata per calcolare la varianza aggregata tra due gruppi in R, ma possiamo calcolarla abbastanza facilmente.
Ad esempio, supponiamo di voler calcolare la varianza aggregata tra i seguenti due gruppi:
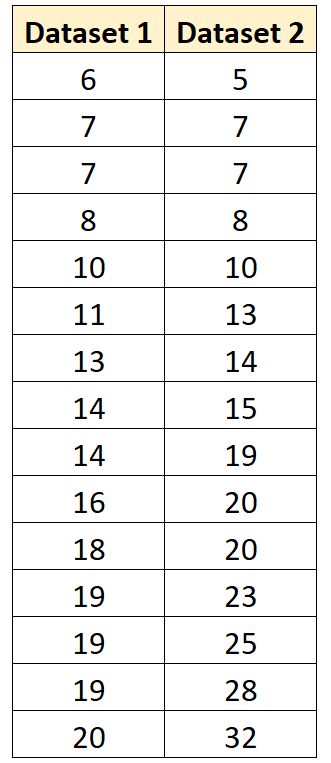
Il codice seguente mostra come calcolare la varianza aggregata tra questi gruppi in R:
#define groups of data x1 <- c(6, 7, 7, 8, 10, 11, 13, 14, 14, 16, 18, 19, 19, 19, 20) x2 <- c(5, 7, 7, 8, 10, 13, 14, 15, 19, 20, 20, 23, 25, 28, 32) #calculate sample size of each group n1 <- length(x1) n2 <- length(x2) #calculate sample variance of each group var1 <- var(x1) var2 <- var(x2) #calculate pooled variance between the two groups pooled <- ((n1-1)*var1 + (n2-1)*var2) / (n1+n2-2) #display pooled variance pooled [1] 46.97143
La varianza complessiva tra questi due gruppi risulta essere 46.97143 .
Risorse addizionali
Cos’è la varianza clusterizzata? (Definizione ed esempio)
Calcolatore del gap in bundle
Come calcolare la varianza raggruppata in Excel
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più