クォータのサンプリング
この記事では、クォータ サンプリングとは何か、およびその実行方法について説明します。クォータ サンプリングの例と、このタイプのサンプリングを他のサンプリングと比較した場合の長所と短所を示します。
クォータ サンプリングとは何ですか?
クォータ サンプリングは、統計調査のサンプルの一部となる個人を選択する方法です。
クォータサンプリングでは、少なくとも 1 つの特性を共有する個人のグループ (または層) が最初に確立され、次に各グループからクォータが選択され、研究サンプルが形成されます。
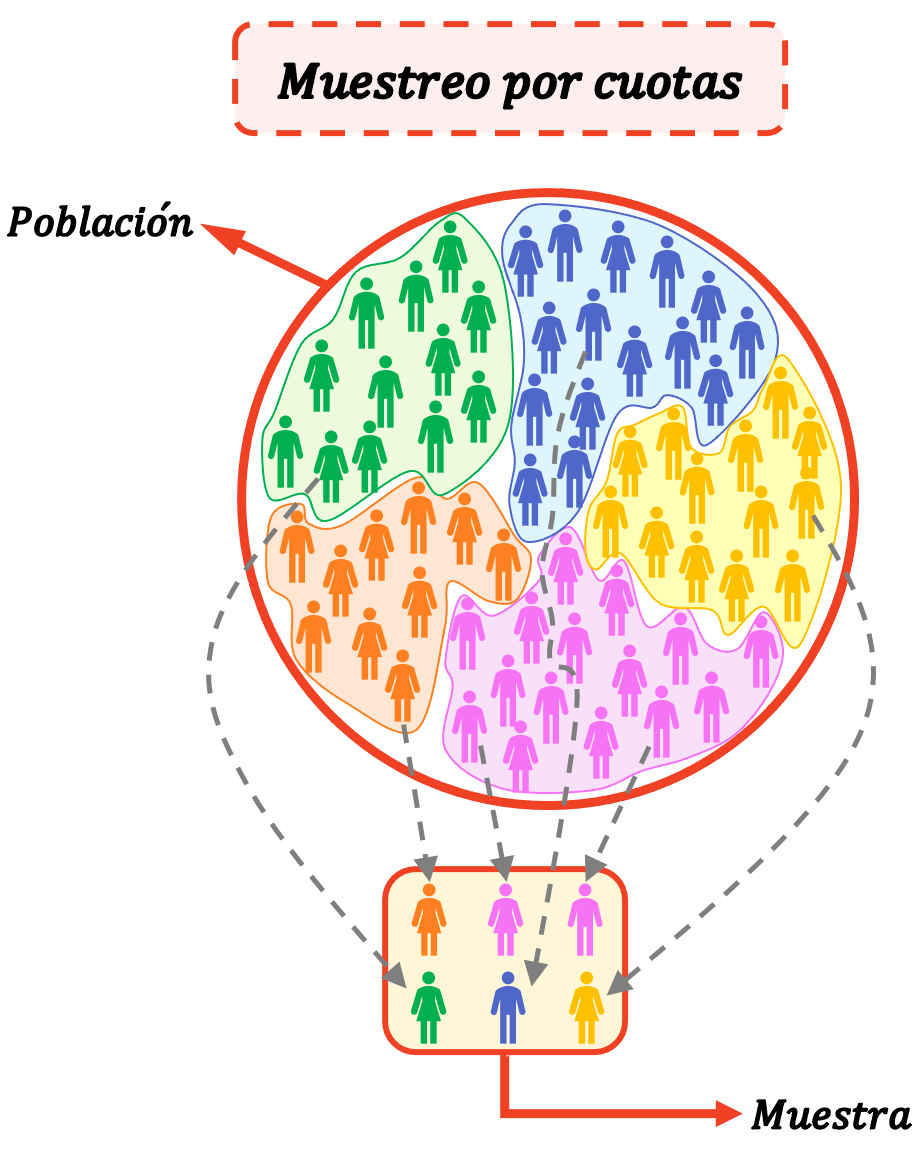
クォータ サンプリングは非確率サンプリングの一種であり、サンプル要素がランダムに選択されるのではなく、研究者によって選択されることを意味します。また、集団をグループに分ける際の個人の特徴も研究者によって決定されるため、研究の責任者が得られる結果に大きな影響を与えます。
クォータサンプリングの実行方法
クォータのサンプリング手順は次のとおりです。
- 対象集団を定義します。
- 統計調査のグループ (または階層) を定義します。これを行うには、母集団をグループに分ける基準を決定する必要があります。
- クォータ サイズを設定します。つまり、各グループからサンプルに含める人数を決定します。
- 各グループから統計研究に参加する個人を選択します。
各グループからサンプルに含める人数を選択する場合、研究者の基準を直接使用できますが、次のような統計的基準も使用できます。
- 単純な選択: 割り当てのサイズはすべてのグループで同じになります。つまり、すべてのグループから同じ数が選択されます。クォータ サイズは、必要なサンプル サイズをグループの総数で割ることによって計算されます。
- 比例的な選択: クォータのサイズはプールのサイズに比例するため、プールが大きいほどクォータも大きくなります。各支払額の計算式は次のとおりです。
- 変動に比例する選択: クォータのサイズが、母集団をグループに分割するのに役立つ特性の変動に比例する場合。クォータのサイズは、グループの標準偏差が大きいほど大きくなり、次の式を使用して計算されます。
![\displaystyle n_i=\cfrac{n}{k} \qquad \begin{array}{l}n=\text{tama\~no muestral deseado} \\[2ex]k=\text{n\'umero de cuotas}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-4878454ee52b3b8d03e49dbd351abe17_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle n_i=n\cdot \cfrac{N_i}{N} \qquad \begin{array}{l}n=\text{tama\~no muestral deseado} \\[2ex]N_i=\text{tama\~no del grupo }i \\[2ex]N=\text{tama\~no de la población}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-b476006440e3d86e8d56a316c658be7c_l3.png "Rendered by QuickLaTeX.com")
![\displaystyle n_i=n\cdot \cfrac{\sigma_i\cdot N_i}{\displaystyle \sum_{j=1}^k\sigma_j\cdot N_j} \qquad \begin{array}{l}n=\text{tama\~no muestral deseado}\\[2ex]\sigma_i=\text{desviaci\'on tipica del grupo }i \\[2ex]N_i=\text{tama\~no del grupo }i \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-b5cbf74f5a41add3e86719d403533613_l3.png "Rendered by QuickLaTeX.com")
クォータのサンプリング例
クォータ サンプリングの定義を確認した後、ステップごとに説明する例を使用して、クォータ サンプリングがどのように行われるかを見てみましょう。
産業分野を専門とする企業は、新製品の販売可能性について市場分析を実行したいと考えています。そのために、彼は年齢別の統計調査を依頼して世論を調査し、新製品の成功を予測しようとしました。同社はまず、潜在的な顧客の見積もりを作成しました。データは次のとおりです。
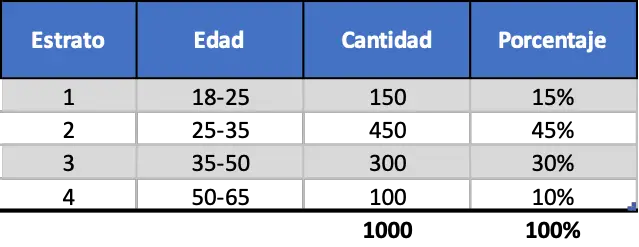
しかし、1,000 人規模の調査を行うと会社にとってコストが高すぎるため、200 人のサンプルのみをインタビューするクォータ サンプリングを実施することにしました。
この場合、人口統計データは、人の年齢に応じてグループ (または階層) ごとに分類されています。さらに、各グループの金額と全体に対する割合もわかっているため、各支払いの金額に比例して選択します。
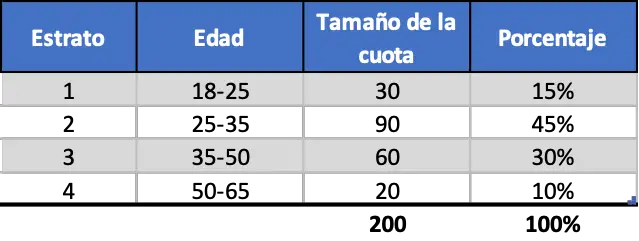
最後に、研究に参加する各割り当ての個人の数が決定したら、研究者は各割り当てからその規模に示される人数を選択し、各被験者から新たに生成された人々について調査を実施するだけで済みます。
クォータサンプリングと階層化サンプリングの違い
クォータサンプリングと層化サンプリングの違いは、サンプル内の個人の選択にあります。クォータ サンプリングでは、研究者がサンプル内の個人を選択しますが、層化サンプリングでは、サンプル内の個人がランダムに選択されます。
ただし、クォータ サンプリングと層化サンプリングには、母集団をグループ (または層) に分割するという共通の特徴があります。このため、これら 2 種類のサンプリングを混同することがよくあります。
層別サンプリングに興味がある場合は、そのすべての長所と短所をここで確認できます。
クォータサンプリングの長所と短所
クォータ サンプリングの長所と短所は次のとおりです。
| アドバンテージ | 短所 |
|---|---|
| クォータ サンプリングでは、得られた結果の解釈が非常に簡単です。 | このタイプのサンプリングで生じる誤差を推定することは不可能です。 |
| クォータ サンプリングは非常に迅速かつ簡単に実行できます。 | ノルマを設定できなかった場合、結果は信頼できなくなります。 |
| これは経済的サンプリングの一種です。 | プロジェクトのコストは割り当てが追加されるたびに増加します。 |
| これにより、人口全体と特に各層を研究することが可能になります。 | グループを形成するには情報の例が必要です。 |
明らかに、クォータ サンプリングの主な利点は、他のタイプのサンプリングと比較して迅速かつ簡単に実行できることです。
この特性は、多くのリソースを使用する必要がないため、クォータ サンプリングの実行コストが非常に低いことを意味します。一方、クォータを追加すると、統計分析の総コストが指数関数的に増加します。
クォータ サンプリングのもう 1 つの利点は、データがグループごとに収集されるため、特定の各グループに関する情報も取得できることです。
他の理由から、博物館のクオータの主な欠点は、クオータを確立するための基準が十分な範囲と範囲である必要があるため、調査員が正しい方法でクオータを定義できるように人口に関する予備知識を持っている必要があることです。各クオタのまた。
論理的には、クォータによるサンプリング時にクォータを含めることを忘れた場合、結果が歪められ、したがって誤った結論が導かれることになります。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る