パンダ: 行あたりの列数が異なる csv をインポートします
行ごとの列数が異なる場合は、次の基本構文を使用して CSV ファイルをパンダにインポートできます。
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
range()関数内の値は、最大列数の行の列数である必要があります。
次の例は、この構文を実際に使用する方法を示しています。
例: 行あたりの列数が異なる CSV を Pandas にインポートする
たとえば、不均等データ.csvという次の CSV ファイルがあるとします。
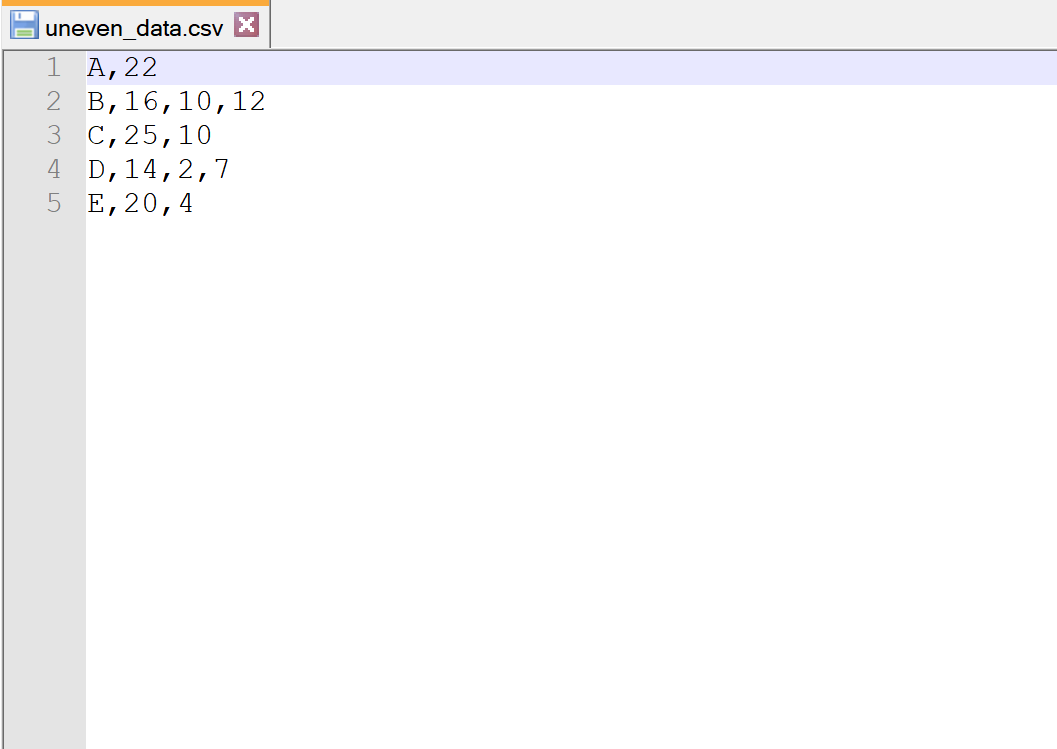
各行の列数は同じではないことに注意してください。
read_csv()関数を使用してこの CSV ファイルを pandas DataFrame にインポートしようとすると、エラーが発生します。
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
ParserErrorを受け取ります。これは、パンダが2 つのフィールド (最初の行の列数であるため) を予期していましたが、 4 を認識したことを示します。
このエラーは、特定の行の最大列数が4であることを示しています。
したがって、CSV ファイルをインポートし、 name引数にrange(4)の値を指定できます。
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
pandas に 4 列を期待するように明示的に指示したため、エラーなしで CSV ファイルを pandas DataFrame に正常にインポートできることに注意してください。
デフォルトでは、pandas は各行のすべての欠損値を NaN で埋めます。
欠損値をゼロとして表示したい場合は、次のようにfillna()関数を使用できます。
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
DataFrame 内の各 NaN 値はゼロに置き換えられました。
注: pandas read_csv()関数の完全なドキュメントはここで見つけることができます。
追加リソース
次のチュートリアルでは、Python で他の一般的なタスクを実行する方法について説明します。
Pandas: CSV ファイルを読み取るときに行をスキップする方法
パンダ: 既存の CSV ファイルにデータを追加する方法
Pandas: CSV ファイルをインポートするときにタイプを指定する方法
Pandas: CSV ファイルをインポートするときに列名を設定する
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る