Benjamini-hochberg 手順のガイド
統計検定を実行すると、たとえ帰無仮説が正しい場合でも、まったくの偶然で 0.05 未満の p 値が得られる可能性があります。
たとえば、特定の植物の平均高さが 10 インチを超えるかどうかを知りたいとします。テスト用の帰無仮説と対立仮説は次のようになります。
H 0 : μ = 10 インチ
H A : μ > 10 インチ
この仮説を検証するには、外出して 20 個の植物の 無作為サンプルを収集して測定します。この植物種の実際の平均高さは 10 インチですが、20 個の異常に高い植物のサンプルを選択したため、帰無仮説が棄却される可能性があります。
たとえ帰無仮説が真実だったとしても (この植物の平均高さは実際には 10 インチでした)、あなたはそれを棄却しました。統計では、これを「誤った発見」と呼びます。あなたは「重大な結果」を発見したと主張していますが、これは実際には誤りです。
ここで、100 個の統計テストを一度に実行することを想像してください。アルファ レベル0.05 を使用すると、個々のテストで誤った検出が行われる可能性は 5% のみですが、非常に多くのテストを実行しているため、誤った検出につながるのは 100 件中 5 件のみであると予想されます。
現代世界では、技術の進歩により、研究者は一度に何百、場合によっては何千もの統計的テストを実行できるようになったため、誤った発見が一般的な問題となる可能性があります。
たとえば、医学研究者は、一度に数万の遺伝子に対して統計的検査を実行できます。誤検出率がわずか 5% であっても、何百回ものテストで誤検出が生じる可能性があることを意味します。
誤検出率を制御する 1 つの方法は、いわゆるBenjamini-Hochberg 手順を使用することです。
ベンジャミニ・ホッホベルグ法
Benjamini-Hochberg 手順は次のように機能します。
ステップ 1:すべての統計検定を実行し、各検定の p 値を見つけます。
ステップ 2: p 値を降順でランク付けし、それぞれにランクを割り当てます。最も小さい値のランクは 1、次に小さい値のランクは 2 などになります。
ステップ 3:式(i/m)*Qを使用して、各 p 値の臨界ベンジャミニ・ホッホベルグ値を計算します。
金:
i = p 値のランク
m = テストの総数
Q = 選択した誤検出率
ステップ 4: 臨界値未満の最大の p 値を見つけます。この p 値より小さい各 p 値を有意なものとして指定します。
次の例は、具体的な値を使用してこの手順を実行する方法を示しています。
例
研究者が 20 の異なる変数が心臓病に関連しているかどうかを判断したいとします。一度に 20 個の個別の統計検定を実行し、各検定の p 値を受け取ります。次の表は、各テストの p 値を降順に示しています。
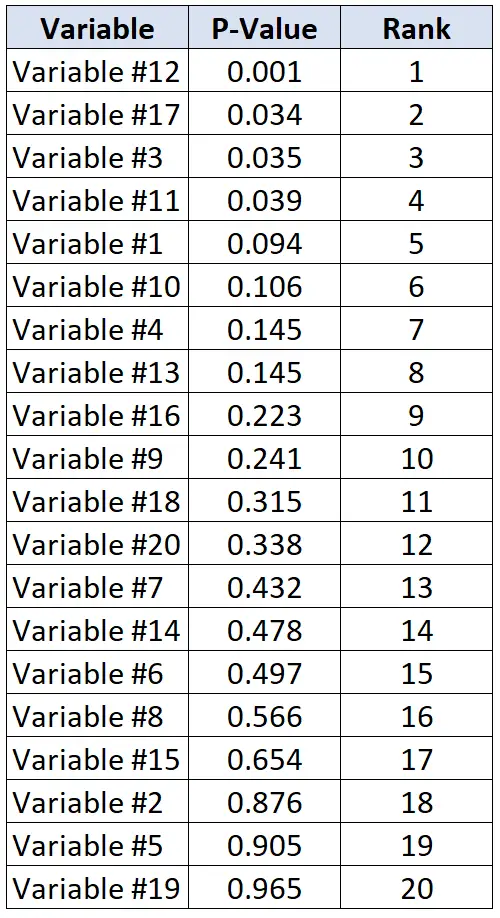
研究者が誤発見率 20% を喜んで受け入れると仮定します。したがって、各 p 値の臨界 Benjamini-Hochberg 値を計算するには、次の式を使用できます: (i/20)*0.2 ここで、 i = p 値のランク。
次の表は、個々の p 値に対する臨界 Benjamini-Hochberg 値を示しています。
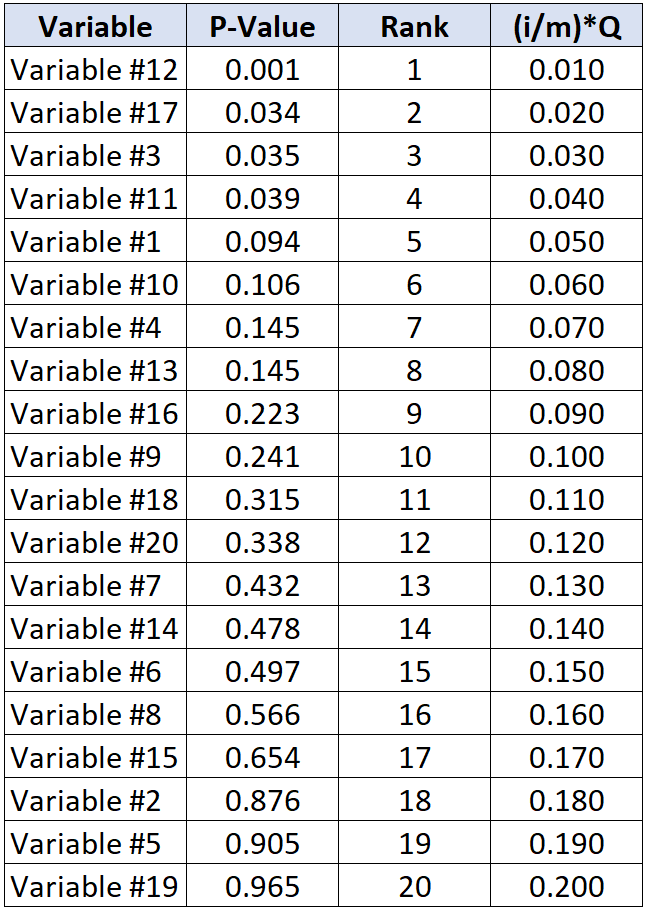
Benjamini-Hochberg 臨界値を下回る最大の p 値を持つ検定は変数 #11 で、p 値は 0.039、BH 臨界値は 0.040 です。
したがって、この検定と、p 値が小さいすべての検定は有意であるとみなされます。
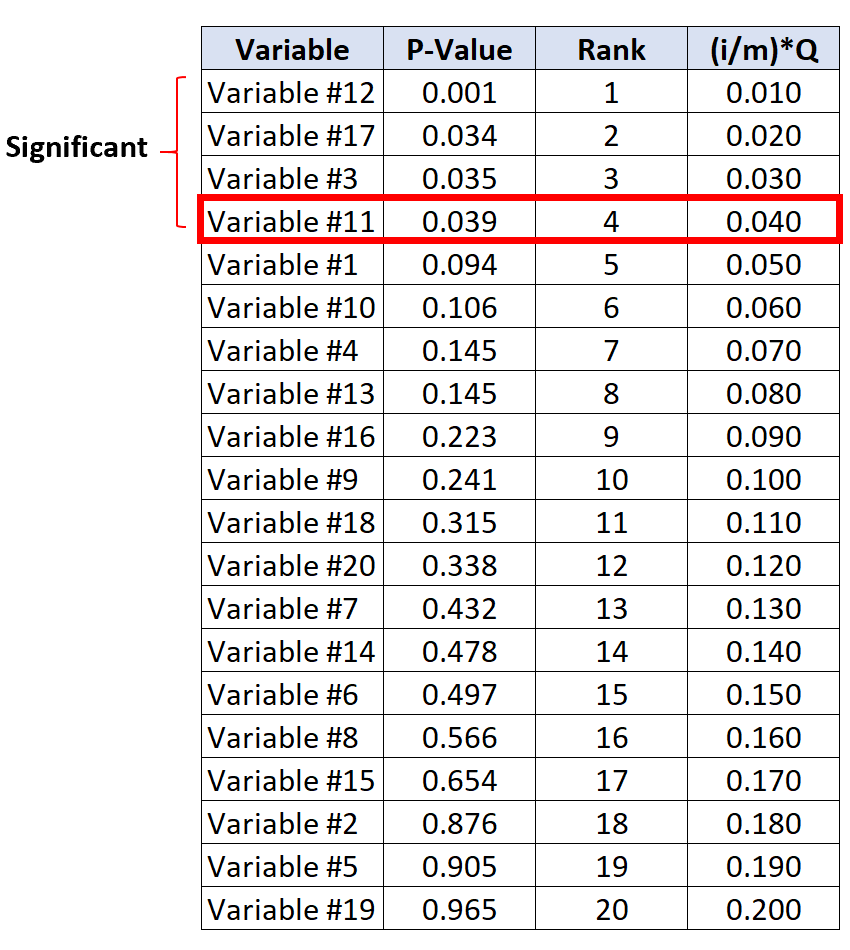
変数 #17 と #3 の p 値は BH 臨界値よりも小さくありませんでしたが、変数 #11 よりも p 値が小さいため、依然として有意であるとみなされることに注意してください。
誤検出率の選び方
Benjamini-Hochberg 手順で最も重要な手順の 1 つは、誤検出率を選択することです。データを収集したり統計テストを実行したりする前に、誤検出率を選択する必要があります。
通常、分析の探索段階では多数の統計テストを実行し、その後、他のテストを実行して結果をさらに調査します。
フォローアップ テストのコストが低い場合は、誤検出率を高く設定することを検討してください。たとえ少数の誤検出があったとしても、その後のテストでそれらの誤検出が検出される可能性が高いからです。
さらに、重要な発見を見逃すコストが高い場合は、重要なものを見逃さないように誤発見率を高めることができます。
研究のコストと、重要な発見を見逃さないことの重要性に応じて、誤検出率は状況によって異なります。
追加リソース
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る