ロジスティック回帰の概要
1 つ以上の予測子変数と連続応答変数の間の関係を理解したい場合、多くの場合、線形回帰が使用されます。
ただし、応答変数がカテゴリカルである場合は、ロジスティック回帰を使用できます。
ロジスティック回帰は、データセット内の観測値を個別のカテゴリに「分類」しようとするため、分類アルゴリズムの一種です。
ロジスティック回帰の使用例をいくつか示します。
- 信用スコアと銀行残高を使用して、特定の顧客がローンを滞納するかどうかを予測したいと考えています。 (応答変数 = 「デフォルト」または「デフォルトなし」)
- 1 試合あたりの平均リバウンドと1 試合あたりの平均ポイントを使用して、特定のバスケットボール選手が NBA にドラフトされるかどうかを予測したいとします (応答変数 = 「ドラフト」または「ドラフト外」)。
- 面積とバスルームの数を使用して、特定の都市の家が 20 万ドル以上の販売価格で出品されるかどうかを予測したいと考えています。 (応答変数 = 「はい」または「いいえ」)
これらの各例の応答変数は 2 つの値のうち 1 つだけを取ることができることに注意してください。これを、応答変数が連続値をとる線形回帰と比較してください。
ロジスティック回帰式
ロジスティック回帰では、最尤推定として知られる方法 (詳細はここでは説明しません) を使用して、次の形式の方程式を求めます。
log[p(X) / ( 1 -p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p
金:
- X j : j番目の予測変数
- β j : j番目の予測変数の係数の推定
方程式の右側の式は、応答変数が値 1 をとる対数オッズを予測します。
したがって、ロジスティック回帰モデルを当てはめる場合、次の方程式を使用して、特定の観測値が値 1 を取る確率を計算できます。
p(X) = e β 0 + β 1 X 1 + β 2 X 2 + … + β p
次に、特定の確率しきい値を使用して、観測値を 1 または 0 に分類します。
たとえば、確率が 0.5 以上の観測値は「1」に分類され、その他の観測値はすべて「0」に分類されると言えます。
ロジスティック回帰の結果を解釈する方法
ロジスティック回帰モデルを使用して、1 試合あたりの平均リバウンドと 1 試合あたりの平均得点に基づいて、特定のバスケットボール選手が NBA にドラフトされるかどうかを予測するとします。
ロジスティック回帰モデルの結果は次のとおりです。
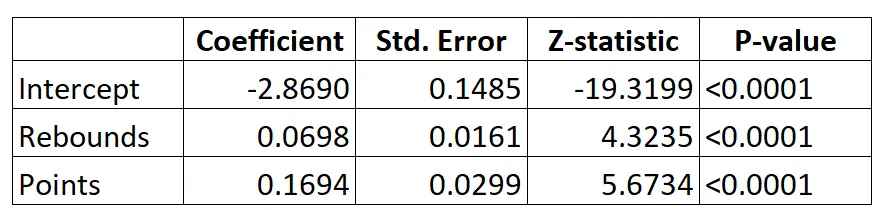
係数を使用すると、次の式を使用して、ゲームごとの平均リバウンドとポイントに基づいて、特定のプレーヤーが NBA にドラフトされる確率を計算できます。
P(ドラフト) = e -2.8690 + 0.0698*(rebs) + 0.1694*(points) / (1+e -2.8690 + 0.0698*(rebs) + 0.1694*(points) ) )
たとえば、特定のプレーヤーが 1 試合あたり平均 8 リバウンド、15 得点を記録したとします。モデルによると、このプレーヤーが NBA にドラフトされる確率は0.557です。
P(書面) = e -2.8690 + 0.0698*(8) + 0.1694*(15) / (1+e -2.8690 + 0.0698*(8) + 0.1694*(15 ) ) = 0.557
この確率は 0.5 より大きいため、この選手はドラフトされると予測します。
これを、1 試合平均 3 リバウンドと 7 得点しか記録しないプレーヤーと比較してください。この選手がNBAにドラフトされる確率は0.186です。
P(書面) = e -2.8690 + 0.0698*(3) + 0.1694*(7) / (1+e -2.8690 + 0.0698*(3) + 0.1694*(7 ) ) = 0.186
この確率は 0.5 未満であるため、この選手はドラフトされないと予測します。
ロジスティック回帰の仮定
ロジスティック回帰では、次の仮定が使用されます。
1. 応答変数はバイナリです。応答変数は 2 つの可能な結果のみを取ることができると想定されます。
2. 観測は独立しています。データセット内の観測値は互いに独立していると想定されます。つまり、観察結果は、同じ個人の繰り返しの測定から得られたものであってはならず、また、いかなる形であっても相互に関連するものであってはなりません。
3. 予測変数間に重大な多重共線性はありません。どの予測変数も相互に高度に相関していないことが想定されます。
4. 極端な外れ値はありません。データセットには極端な外れ値や影響力のある観測値が存在しないと想定されます。
5. 予測変数と応答変数のロジットの間には線形関係があります。この仮説は、Box-Tidwell 検定を使用して検証できます。
6. サンプルサイズが十分に大きい。通常、説明変数ごとに、結果の頻度が最も低いケースが少なくとも 10 個存在する必要があります。たとえば、説明変数が 3 つあり、最小頻度の結果の期待確率が 0.20 の場合、サンプル サイズは少なくとも (10*3) / 0.20 = 150 である必要があります。
これらの仮定を検証する方法の詳細な説明については、 この記事を参照してください。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る