体系的なサンプリング
この記事では、システマティックサンプリングとは何か、その特徴、そしてどのように実施されるのかについて説明します。体系的なサンプリングの例も表示されます。さらに、系統的サンプリングの長所と短所、およびこのタイプのサンプリングをいつ使用する必要があるかについても学びます。
系統的サンプリングとは何ですか?
系統的サンプリングは、統計調査のサンプルの一部となる要素を選択するために使用される確率手法です。系統的サンプリングでは、最初に 1 つの要素がランダムに選択され、サンプル内の他の要素が一定の間隔で選択されます。
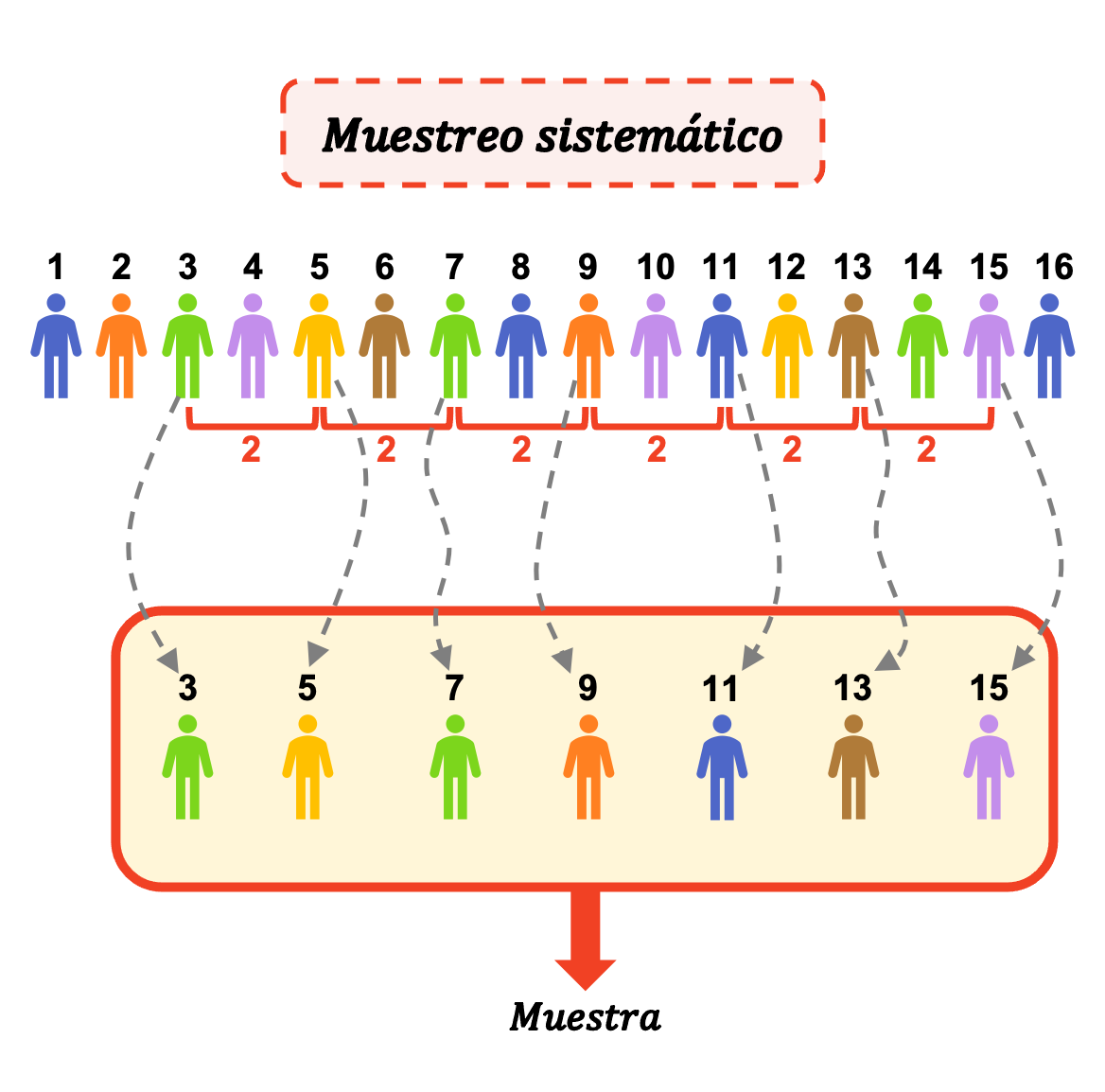
したがって、体系的なサンプリングでは、サンプルから最初の個人をランダムに選択したら、サンプルから次の個人を抽出するために、必要な間隔と同じだけ数をカウントする必要があります。そして、取得したいサンプルサイズと同じ数の個体がサンプル内に含まれるまで、同じ手順を繰り返します。
一方で、サンプルから個人を選択する方法は他にもあることを知っておく必要があります。最もよく使用されるサンプリングのタイプは次のとおりです。
- 単純なランダムサンプリング
- 層化抽出法
- 体系的なサンプリング
- 集落抽出
probabilistica.com では、各タイプの確率サンプリングの詳細な説明が用意されているため、興味がある場合は、Web サイトでそれぞれの確率サンプリングがどのように実行されるかを検索してください。
体系的なサンプリングを行う方法
体系的なランダムサンプリングを実行する手順は次のとおりです。
- 対象集団を定義します。
- 必要なサンプル サイズを決定します。
- サンプリング間隔を計算します。これを行うには、母集団のサイズをサンプル サイズで割ります。
- サンプル内の最初の項目をランダムに選択します。
- サンプルの残りの要素を選択します。これを行うには、前のステップで選択した数値にサンプリング間隔を連続的に加算します。
体系的サンプリングで選択される最初の項目がランダムであることが重要です。これは、実際にはサンプル内でランダムに選択される唯一の項目だからです。そうしないと、体系的なサンプリングのランダム性が損なわれてしまいます。このため、研究者は、母集団のすべての要素が開始点として選択される確率が同じであることを確認する必要があります。
同様に、系統的サンプリングではサンプル要素が間隔を置いて選択されるため、最終サンプルには特定のタイプの要素が存在せず、サンプルが十分に代表的でない可能性があります。しかし、これは体系的なサンプリングを実行するときに生じるリスクです。
最後に、サンプリング間隔はモデルではないことを考慮する必要があります。選択したサンプルが適切ではなくなり、統計調査で得られる結果が信頼性の低いものになるためです。
系統的なサンプリングの例
体系的サンプリングの定義を確認した後、その意味をよりよく理解できるように、このタイプのサンプリングの例を説明します。
たとえば、1000 個の要素からなる母集団に対して体系的なサンプリングを実行して、50 個の要素からなるサンプルを取得したい場合は、次のように進める必要があります。
まず、サンプリング間隔を計算する必要があります。これを行うには、単純に母集団サイズをサンプルサイズで割ります。

次に、サンプル内の最初の被験者をランダムに選択する必要があります。このステップを実行するには、いくつかの方法がありますが、たとえば、コンピューター プログラム Excel を使用して、1 から 20 までの乱数を取得できます (最初の数値を最初のフラグメントに含めることをお勧めします)。 17 という数字を取得したとします。

次に、サンプルから次の要素を選択するために、数値 17 にサンプリング間隔 (20) を加算する必要があります。必要なサンプル サイズは 50 であるため、さらに 49 個の数値を選択する必要があります。

したがって、出てくる数字に共感する母集団の要素は、統計研究のサンプルの一部として選択されたものになります。
系統的サンプリングの長所と短所
体系的なサンプリングには次のような利点と欠点があります。
| アドバンテージ | 短所 |
|---|---|
| 体系的なサンプリングは非常に迅速に実行できます。 | パターンがあり、それがサンプリング間隔と一致する場合、偏ったサンプルが得られます。 |
| わかりやすいですね。 | 選択されたサンプルには、ランダムに選択された要素が 1 つだけあります。 |
| 得られたサンプルは一般に代表的なものです。 | 最初のトピックが選択されると、一部のアイテムは選択される可能性がゼロになります。 |
| 体系的なサンプリングは、母集団の一部に限定されるのではなく、母集団全体に分布する要素をサンプリングします。 | 変動の推定は、単純なランダムサンプリングシステムよりも複雑です。 |
上の例で見たように、体系的なサンプリングは迅速かつ簡単に実行できます。そうは思えないかもしれませんが、この特性は経済的コストが低いため重要です。
系統的サンプリングのもう 1 つの利点は、母集団全体からサンプリングされることです。一方、他のタイプのサンプリングでは、たとえば母集団の前半から要素のみを抽出することもできます。
体系的サンプリングの欠点は、特定の種類の周期性やパターンがある場合、偏ったサンプルが取得される可能性があるため、母集団の要素が配置される順序によって統計結果の信頼性が左右される可能性があることです。たとえば、男性と女性の母集団を次のように順序付けするとします。

この順序でサンプリング間隔を 2 にすると、出身地に応じて女性のみ、または男性のみが選択されます。したがって、信頼性の低いサンプルが得られることになります。
最後に、系統的サンプリングのもう 1 つのマイナス面は、1 つの要素だけがランダムに選択され、サンプル内の残りの要素が条件付けされてしまうことです。手順全体を通じて偶然がはるかに多く存在する他のタイプのサンプリングとは異なります。
系統的サンプリングを使用する場合
最後に、体系的なサンプリングを使用するのが現実的な場合とそうでない場合を示します。このサンプリング システムは常に使用できるわけではないためです。
系統的サンプリングは、シンプルかつ迅速に実装できるサンプリング方法が必要な場合に使用できます。言い換えれば、プロジェクトの予算が限られている場合、体系的なサンプリングは、実行に必要なリソースがほとんどないため、非常に優れた選択肢となります。
記事全体で見たように、母集団がある種のパターンを示している場合には偏った標本が得られる可能性があるため、このタイプの標本抽出を使用するのは現実的ではありません。
最後に、母集団に多くの異なるグループが存在する場合、つまり母集団に多くの層がある場合は、体系的なサンプリングができない層を個別に統計分析できるため、層化サンプリングを使用することが望ましいと考えられます。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る