教師あり学習と教師なし学習の簡単な紹介
機械学習の分野には、データを理解するために使用できる膨大なアルゴリズムのセットが含まれています。これらのアルゴリズムは、次の 2 つのカテゴリのいずれかに分類できます。
1. 教師あり学習アルゴリズム: 1 つ以上の入力に基づいて結果を推定または予測するモデルの構築が含まれます。
2. 教師なし学習アルゴリズム:入力から構造と関係を見つけることが含まれます。 「監視」出力はありません。
このチュートリアルでは、これら 2 種類のアルゴリズムの違いを、それぞれのいくつかの例とともに説明します。
教師あり学習アルゴリズム
教師あり学習アルゴリズムは、 1 つ以上の説明変数( X1、応答変数:
Y = f (X) + ε
ここで、 f はX が Y について提供する系統的な情報を表し、ε は X から独立した平均ゼロのランダム誤差項です。
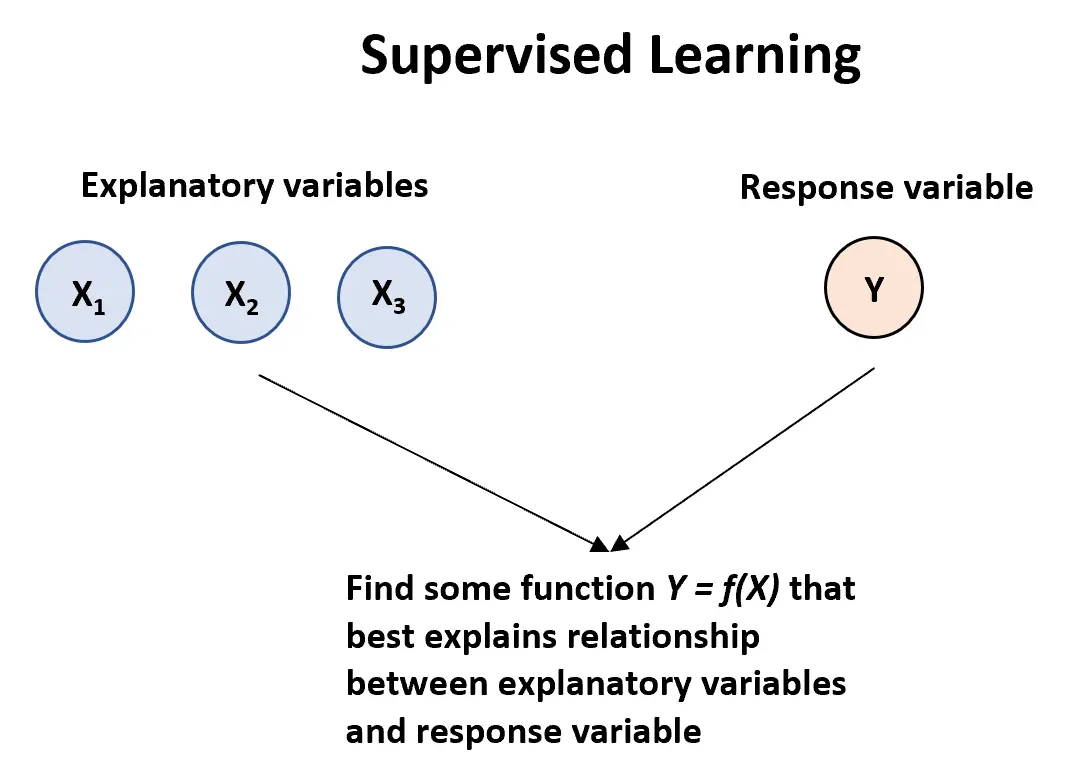
教師あり学習アルゴリズムには主に 2 つのタイプがあります。
1. 回帰:出力変数は連続的です (体重、身長、時間など)。
2. 分類:出力変数はカテゴリカルです (例: 男性または女性、成功または失敗、良性または悪性など)。
教師あり学習アルゴリズムを使用する主な理由は 2 つあります。
1. 予測:応答変数の値を予測するために一連の説明変数を使用することがよくあります (たとえば、住宅の価格を予測するために平方フィートと寝室の数を使用します)。
2. 推論:説明変数の値が変化したときに応答変数がどのような影響を受けるかを理解することに興味があるかもしれません (たとえば、部屋の数が 1 つ増加すると、不動産の価格は平均してどのくらい上昇しますか?)。
目標が推論か予測 (または両方の混合) であるかどうかに応じて、関数fを推定するためにさまざまな方法を使用できます。たとえば、線形モデルは解釈が容易ですが、解釈が難しい非線形モデルはより正確な予測を提供する可能性があります。
最も一般的に使用される教師あり学習アルゴリズムのリストは次のとおりです。
- 線形回帰
- ロジスティック回帰
- 線形判別分析
- 二次判別分析
- ディシジョンツリー
- ナイーブ・ベイズ
- サポートベクターマシン
- ニューラルネットワーク
教師なし学習アルゴリズム
教師なし学習アルゴリズムは、変数のリスト( X 1 、 data.
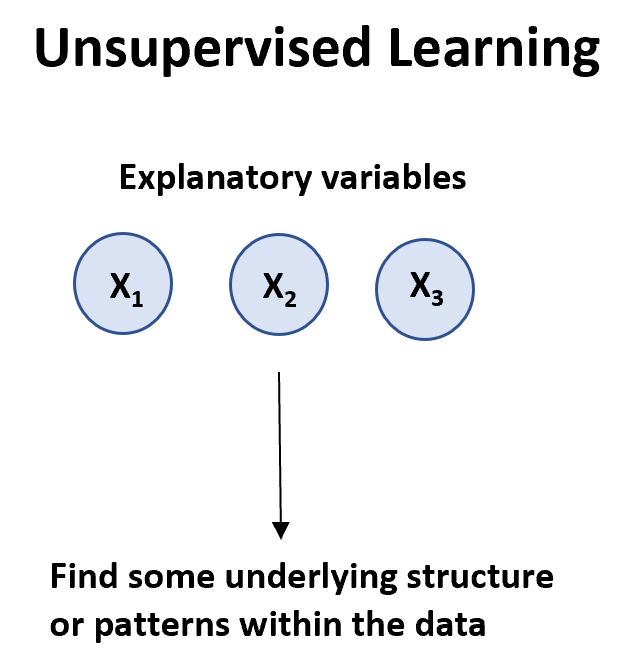
教師なし学習アルゴリズムには主に 2 つのタイプがあります。
1. クラスタリング:この種のアルゴリズムを使用して、データセット内で互いに類似した観測値の「クラスター」を見つけようとします。これは、企業が特定の顧客グループを対象とした特定のマーケティング戦略を作成できるように、同様の購買習慣を持つ顧客のグループを特定したい場合に、小売業でよく使用されます。
2. 関連付け:この種のアルゴリズムを使用して、関連付けを確立するために使用できる「ルール」を見つけようとします。たとえば、小売業者は、「顧客が製品 X を購入すると、製品 Y も購入する可能性が非常に高い」ことを示す関連付けアルゴリズムを開発できます。
最も一般的に使用される教師なし学習アルゴリズムのリストは次のとおりです。
- 主成分分析
- K 平均法クラスタリング
- K-medoidのグループ化
- 階層的分類
- アプリオリアルゴリズム
概要: 教師あり学習または教師なし学習
次の表は、教師あり学習アルゴリズムと教師なし学習アルゴリズムの違いをまとめたものです。
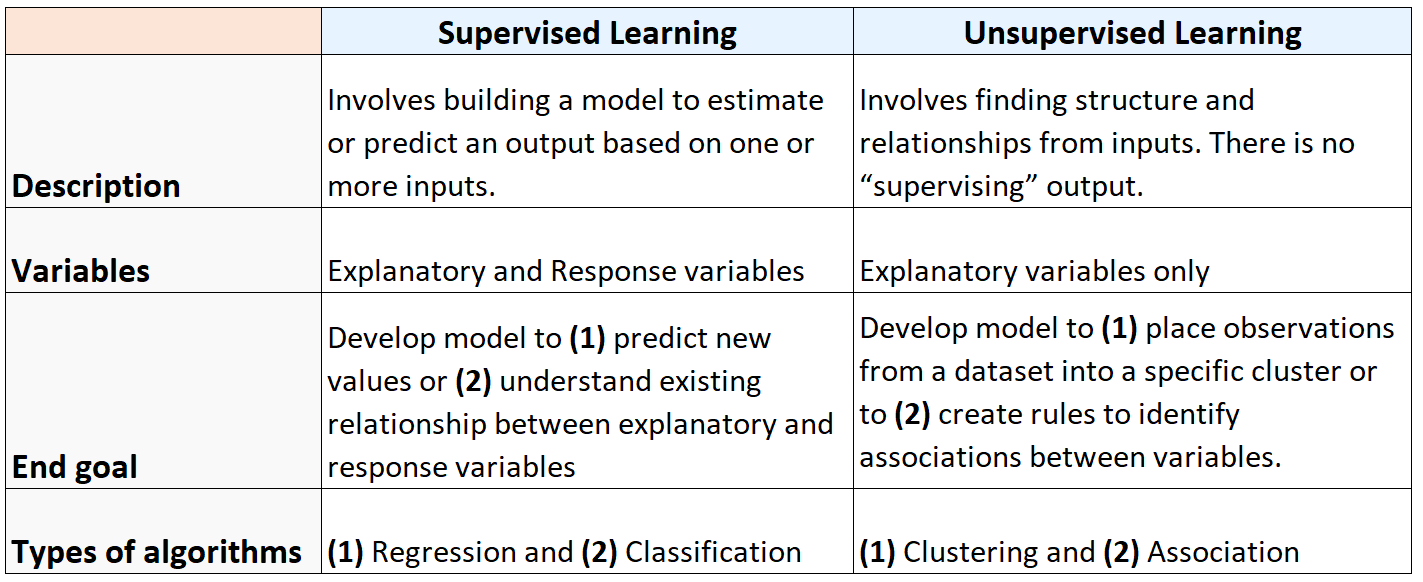
次の図は、機械学習アルゴリズムの種類をまとめたものです。

著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る