人口 vs.サンプル:違いは何ですか?
統計では、特定の研究上の疑問に答えるためにデータを収集することがよくあります。
たとえば、次のような質問に答えたいと思うかもしれません。
1.フロリダ州マイアミの世帯収入の中央値はいくらですか?
2.特定のカメの個体群の平均体重はどれくらいですか?
3.特定の郡の住民の何パーセントが特定の法律を支持していますか?
各シナリオでは、測定したいすべての考えられる個々の要素を表す母集団に関する質問に答えたいと考えています。
ただし、母集団内のすべての個人に関するデータを収集するのではなく、母集団の一部を表す母集団のサンプルに関するデータを収集します。
人口: 測定したいすべての可能な個々の項目。
サンプル:人口の一部。
ここでは、3 つの導入例における母集団とサンプルの例を示します。
例 1: フロリダ州マイアミの世帯収入の中央値はいくらですか?
人口全体は 500,000 世帯で構成されている可能性がありますが、データを収集できるのは合計 2,000 世帯のサンプルについてのみです。

2. 特定のカメの個体群の平均体重はどれくらいですか?
総個体数には 800 匹のカメが含まれる可能性がありますが、データを収集できたのはサンプルの 30 匹だけでした。

3. 特定の郡の住民の何パーセントが特定の法律を支持していますか?
総人口は50,000 人かもしれませんが、収集できるデータはサンプルの 1,000 人だけです。

なぜサンプルを使用するのでしょうか?
通常、母集団全体ではなくサンプルに関するデータを収集するのには、次のような理由があります。
1 .人口全体に関するデータを収集するには時間がかかりすぎます。たとえば、フロリダ州マイアミの世帯収入の中央値を知りたい場合、各世帯の収入を収集するのに数か月、場合によっては数年かかる場合があります。このデータをすべて収集する頃には、母集団が変わっているか、関心のある研究課題がなくなっている可能性があります。
2. 人口全体のデータを収集するには費用がかかりすぎます。多くの場合、母集団内の各個人のデータを収集するにはコストがかかりすぎるため、代わりにサンプルに関するデータを収集することを選択します。
3. 集団全体のデータを収集することは不可能です。多くの場合、集団内のすべての個人のデータを収集することは不可能です。たとえば、対象となる特定の集団内のすべてのカメを見つけて体重を量ることは、非常に困難な場合があります。
サンプルのデータを収集することにより、特定の集団に関する情報をより迅速かつ低コストで収集できるようになります。
そして、サンプルが母集団を代表するものであれば、高い信頼度で 1 つのサンプルの結果をより大きな母集団に一般化することができます。
代表的なサンプルの重要性
母集団からサンプルを収集するとき、理想的には、そのサンプルが母集団の「ミニバージョン」に似ていることが望ましいと考えられます。
たとえば、合計 5,000 人の生徒がいる特定の学区の生徒の映画の好みを理解したいとします。各学生を個別に調査するには時間がかかりすぎるため、代わりに 100 人の学生のサンプルを採取し、彼らの好みについて尋ねることができます。
学生人口全体が女子 50%、男子 50% である場合、男子が 90%、女子が 10% のみを含むサンプルは代表的ではありません。
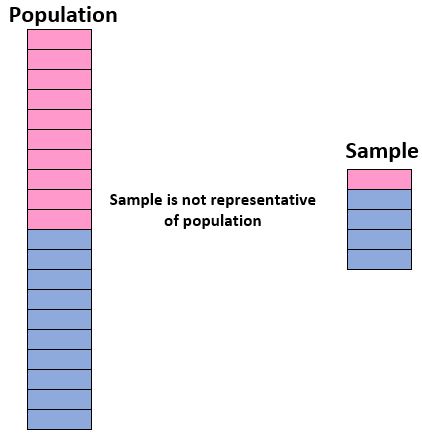
または、母集団全体が 1 年生、2 年生、3 年生、4 年生で構成されている場合、1 年生のみが含まれているサンプルは代表的ではありません。
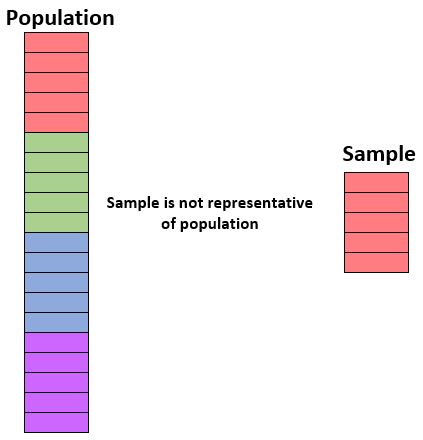
サンプル内の個人の特徴が母集団全体の個人の特徴とよく一致する場合、サンプルは母集団を代表していると言えます。
これが起こると、サンプルからの結果を母集団全体に自信を持って一般化することができます。
サンプルの入手方法
サンプル母集団を取得するために使用できるさまざまな方法があります。
代表的なサンプルを取得する可能性を最大限に高めるために、次の 3 つの方法のいずれかを使用できます。
単純なランダムサンプリング:乱数発生器またはランダム選択手段を使用して個人をランダムに選択します。
体系的なランダムサンプリング:母集団の各メンバーを特定の順序で配置します。ランダムな開始点を選択し、サンプルの一部となるメンバーを n 人から1 人選択します。
層化ランダムサンプリング:母集団をグループに分ける。各グループから数人のメンバーをサンプルの一部としてランダムに選択します。
これらの各方法では、母集団内の各個人がサンプルに含まれる確率は等しいです。これにより、母集団の「ミニバージョン」であるサンプルを取得できる可能性が最大になります。
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る