生データとは何ですか? (定義と例)
統計において、生データとは、一次情報源から直接収集され、いかなる処理もされていないデータを指します。
どのような種類のデータ分析プロジェクトでも、最初のステップは生データを収集することです。このデータが収集されると、クリーニング、変換、要約、視覚化が可能になります。
生データを収集する利点は、最終的にそれを使用して特定の現象をより深く理解したり、ある種の予測モデルを構築したりできることです。
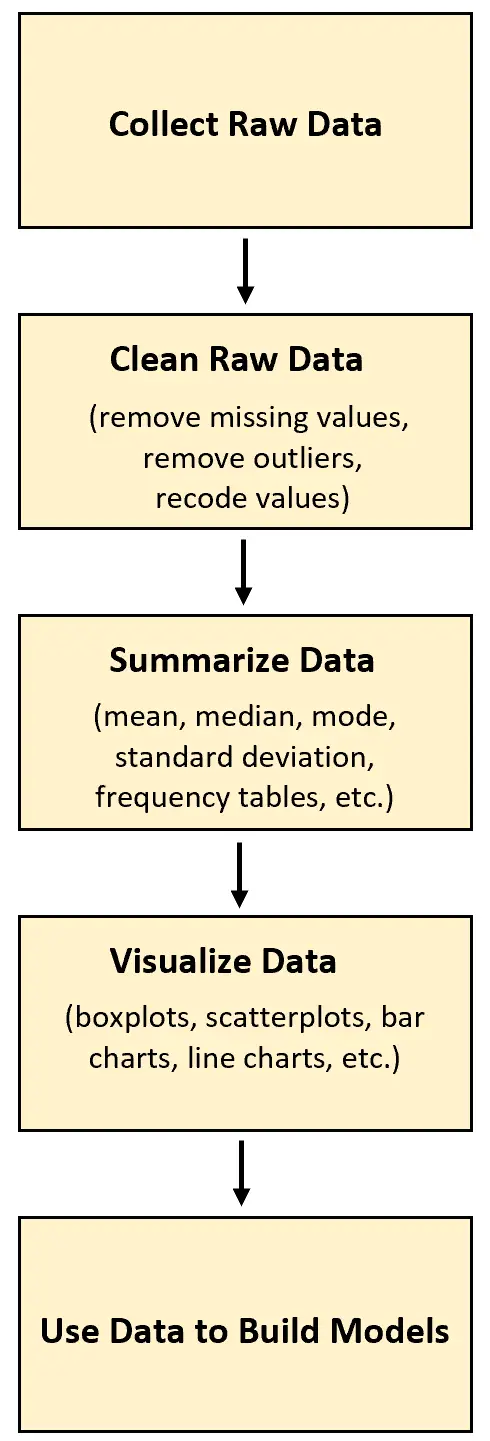
次の例は、生データを実際に収集して使用する方法を示しています。
例: 生データの収集と使用
スポーツは生データが頻繁に収集される分野です。たとえば、プロバスケットボール選手に関するさまざまな統計の生データを収集できます。
ステップ 1: 生データを収集する
バスケットボールのスカウトが、プロ バスケットボール チームの 10 人の選手に関する次の生データを収集すると想像してください。 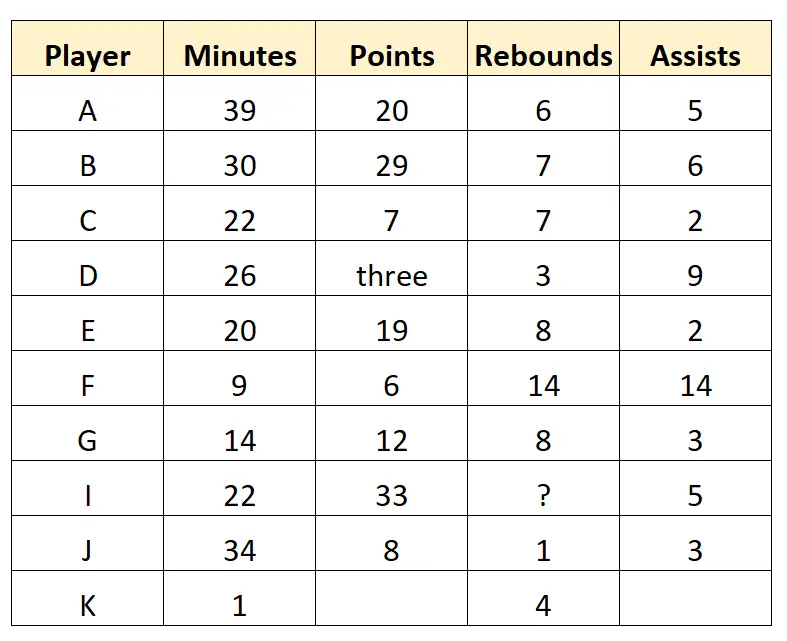
このデータセットは、スカウトによって直接収集された生データを表しており、いかなる方法でもクリーンアップまたは処理されていません。
ステップ 2: 生データをクリーンアップする
このデータを使用して要約表、グラフ、その他のものを作成する前に、スカウトはまず欠損値を削除し、「ダーティ」データ値をクリーンアップする必要があります。
たとえば、データセット内で変換または削除する必要があるいくつかの値を見つけることができます。
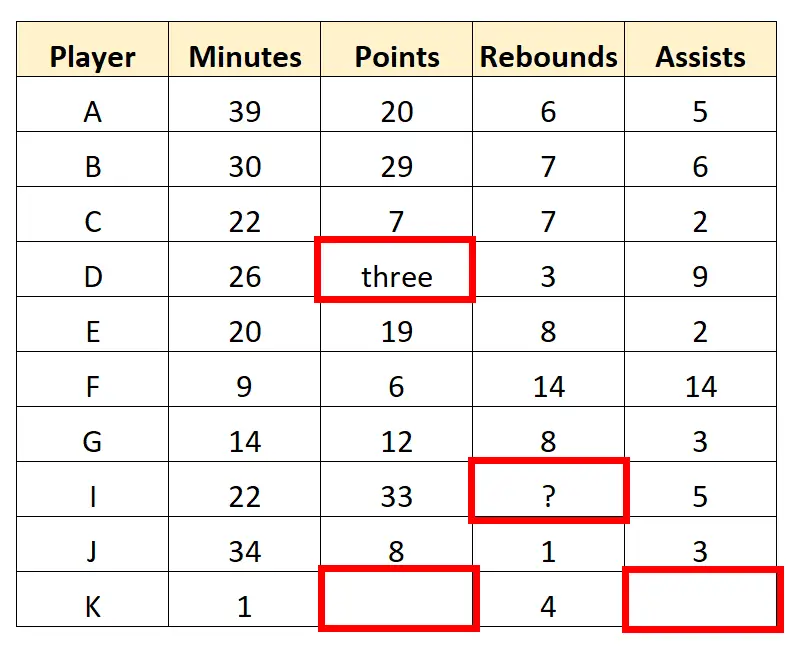
スカウトは、欠損値がいくつかあるため、最後の行を完全に削除することを決定する場合があります。次に、データセット内の文字値をクリーンアップして、次の「クリーンな」データを取得します。
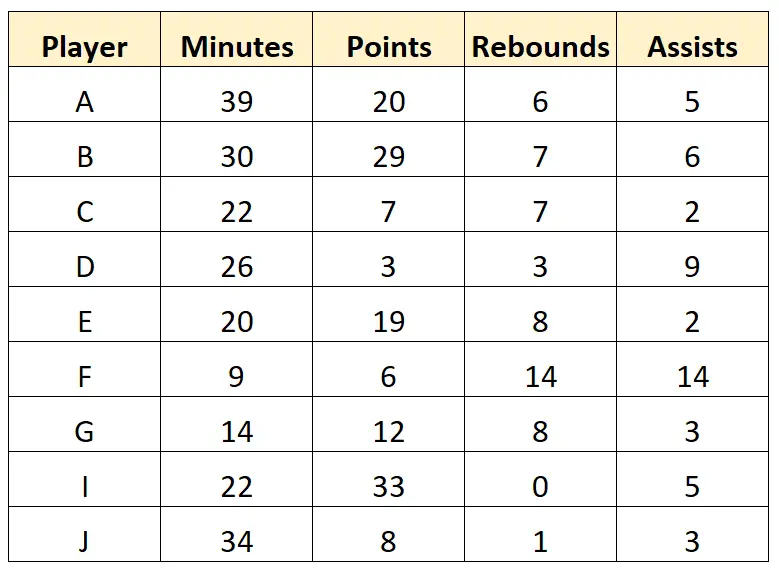
ステップ 3: データを要約する
データがクリーンアップされると、スカウトはデータセット内の各変数を要約できるようになります。たとえば、「Minutes」変数について次の概要統計を計算できます。
- 平均:24分
- 中央値: 22 分
- 標準偏差: 9.45分
ステップ 4: データを視覚化する
スカウトはデータセット内の変数を視覚化して、データ値をより深く理解できます。
たとえば、次の棒グラフを作成して、各プレーヤーの合計プレイ時間を視覚化できます。
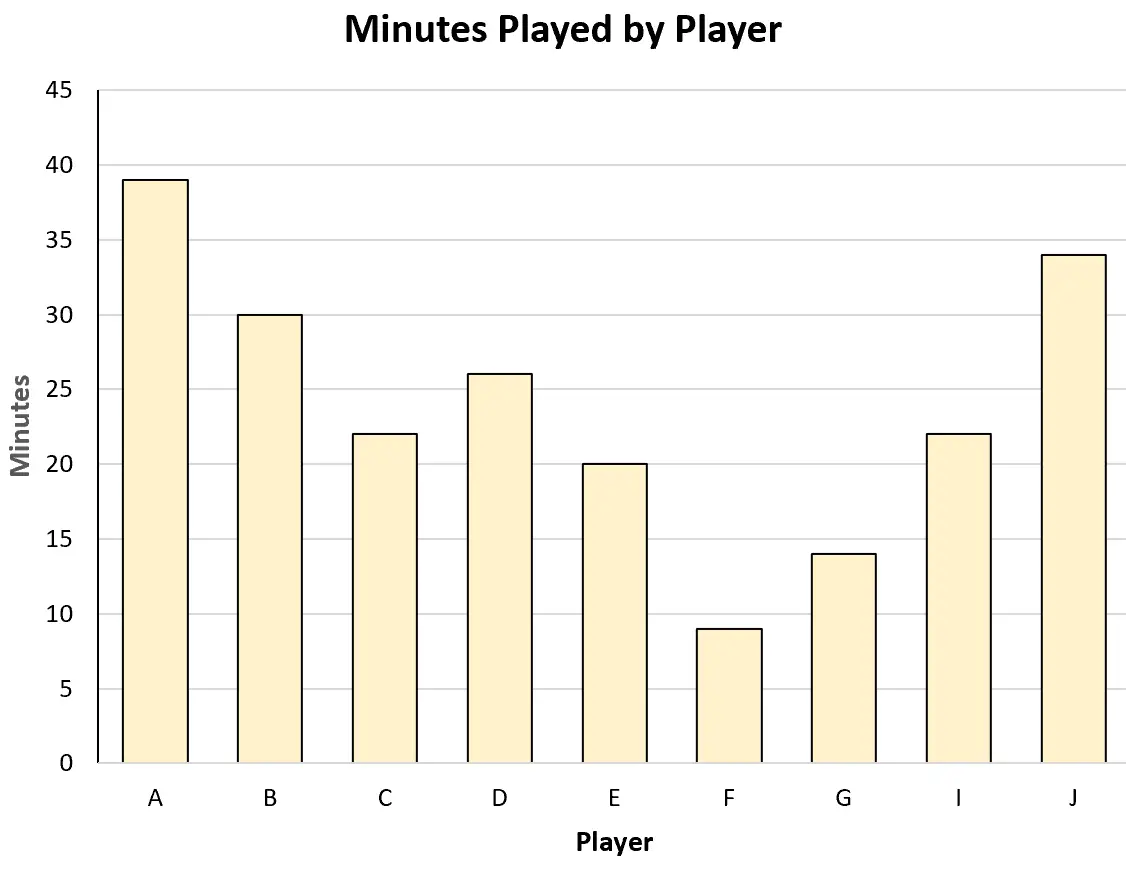
あるいは、次の散布図を作成して、プレー時間と得点の関係を視覚化することもできます。
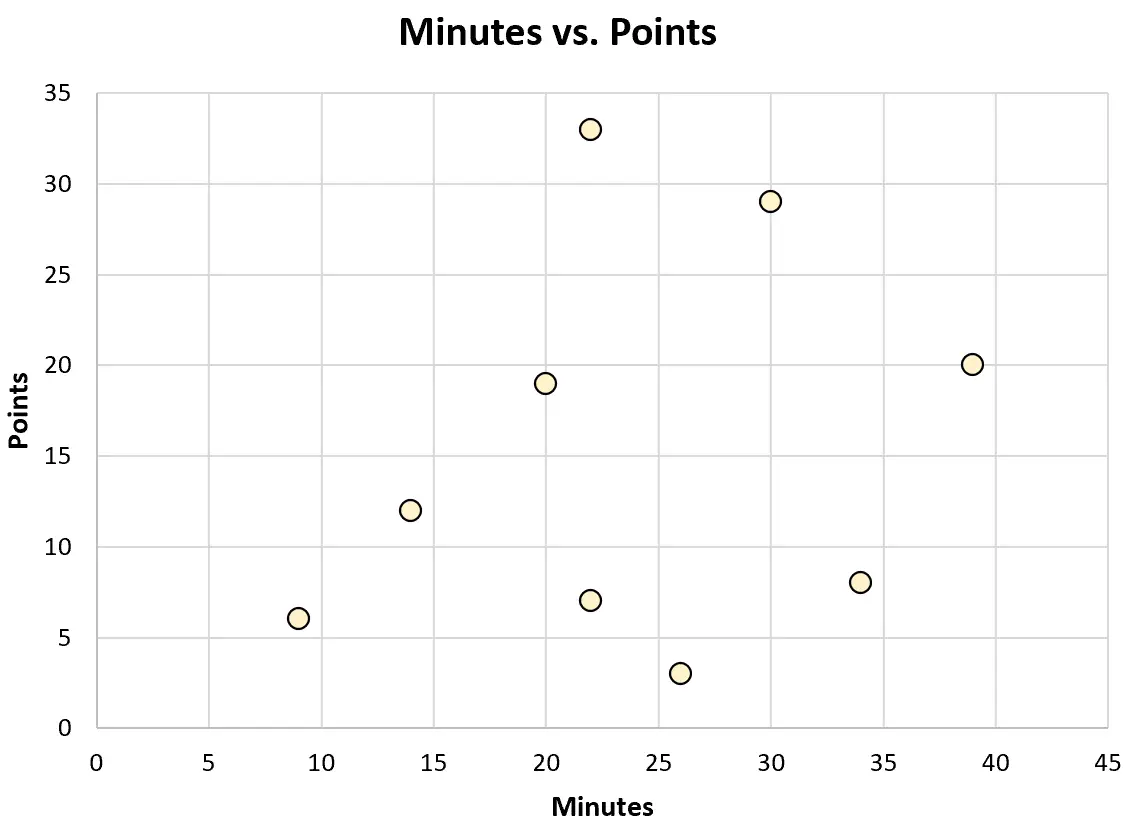
これらの種類のグラフはそれぞれ、データをより深く理解するのに役立ちます。
ステップ 5: データを使用してモデルを構築する
最後に、データがクリーンアップされると、スカウトは何らかのタイプの予測モデルを適応させることを決定できます。
たとえば、単純な線形回帰モデルを当てはめ、プレー時間を使用して各プレーヤーが獲得した合計ポイントを予測できます。
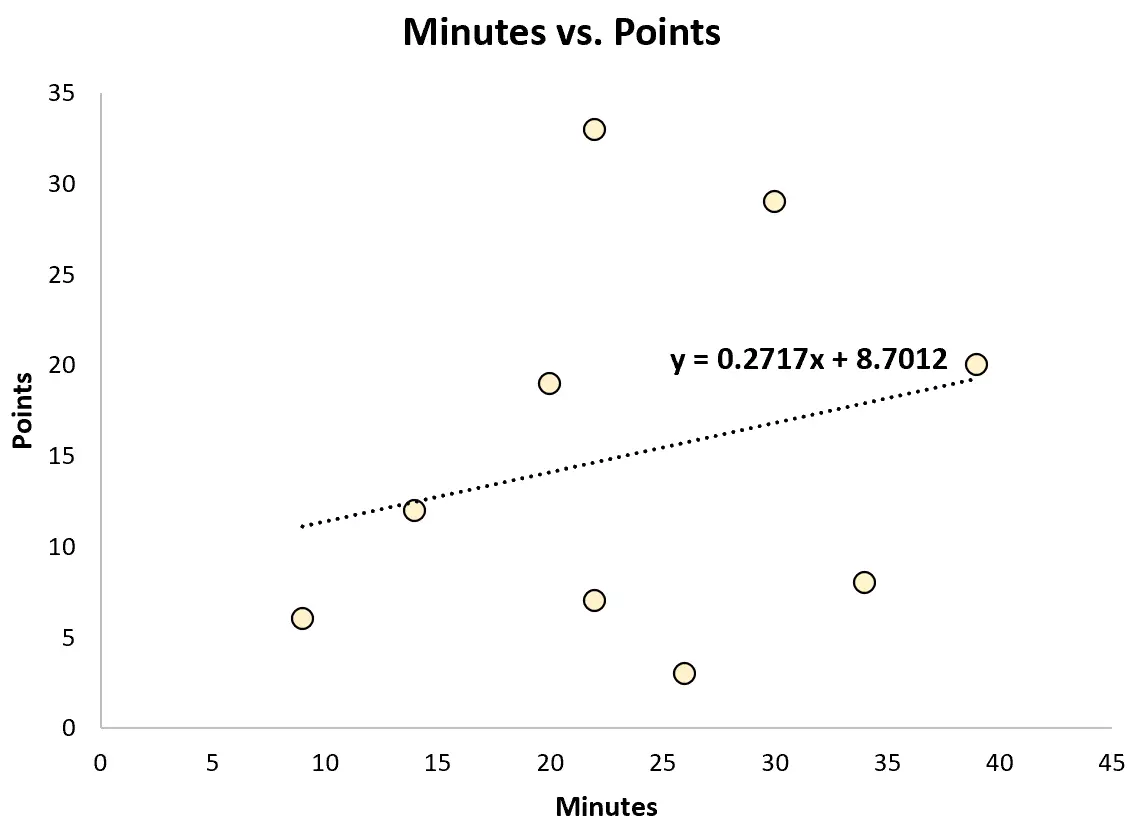
近似された回帰式は次のとおりです。
ポイント = 8.7012 + 0.2717*(分)
スカウトはこの方程式を使用して、プレー時間に基づいてプレーヤーが獲得するポイント数を予測できます。たとえば、30 分間プレーしたアスリートは16.85ポイントを獲得する必要があります。
ポイント = 8.7012 + 0.2717*(30) = 16.85
追加リソース
なぜ統計が重要なのでしょうか?
統計においてサンプルサイズが重要なのはなぜですか?
統計における観察とは何ですか?
統計における表形式データとは何ですか?
著者について
ベンジャミン・アンダーソン博士
私はベンジャミンです。退職した統計教授から、専任の Statorials 教育者になりました。 統計分野における豊富な経験と専門知識を活かして、私は Statorials を通じて学生に力を与えるために自分の知識を共有することに尽力しています。もっと知る